特征工程
一.为什么需要特征工程?
因为“数据和特征决定机器学习的上限,而模型和算法只是逼近这个上限而已”,使用专业背景知识和技巧处理数据,使算法变得更好。
二.什么是特征工程
sklearn库用于做特征工程
pandas库用来做数据清洗、数据处理。
特征抽取
定义:将任意数据(如文本或图像)转换为可用于机器学习的数字特征,也叫特征值化
使用sklearn.feature_extraction()函数
字典数据:使用字典特征提取
文本数据:使用文本特征提取
图像数据:使用图像特征提取
1.字典特征提取(将字典中属于类别的特征 转化为 one-hot编码)
目的:将字典中属于类别的特征 转化为 one-hot编码
应用场景:a.当数据集中类别特征比较多时(先将数据集中的特征转换为字典类型,再使用DictVectorizer()进行字典特征抽取)
b.当你本身拿到的数据就是字典类型时
from sklearn.feature_extraction import DictVectorizer
`
代码实现:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
# def datasets_demo():
# #获取数据集
# iris=load_iris()
# print('鸢尾花数据集:\n',iris)
# print('查看数据集描述:\n', iris['DESCR'])
# print('查看特征值的名字:\n', iris.feature_names)
# print('查看特征值:\n', iris.data, iris.data.shape)
# #数据集划分
# x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
# print('训练集的特征值:\n',x_train,x_train.shape)
def dict_demo():
data=[{
'city':'北京','temperature':100},{
'city':'上海','temperature':100},{
'city':'深圳','temperature':30}]
#实例化一个转换器类
transfer=DictVectorizer()
#调用fit_tranform()
data_new=transfer.fit_transform(data)
print('data_new:\n',data_new)
if __name__=='__main__':
#datasets_demo()
dict_demo()
返回一个sparse矩阵(稀疏矩阵):
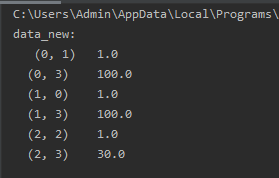
设置sparse=Flase时,返回二维数组:
transfer=DictVectorizer(sparse=False)
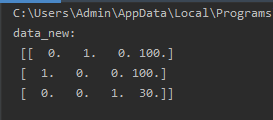
返回稀疏矩阵的好处:当特征太多时,可以省略很多很多0
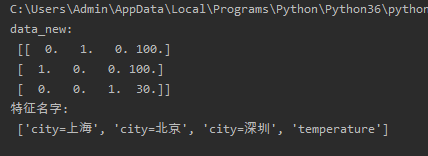
返回特征名字:
def dict_demo():
data=[{
'city':'北京','temperature':100},{
'city':'上海','temperature':100},{
'city':'深圳','temperature':30}]
#实例化一个转换器类
transfer=DictVectorizer(sparse=False)
#调用fit_tranform()
data_new=transfer.fit_transform(data)
feature_names=transfer.get_feature_names()
print('data_new:\n',data_new)
print('特征名字:\n', feature_names)
2.文本特征抽取(按特征词提取)
方法一:CountVectorizer()(统计每个样本特征词出现的个数)忽略单个字母和标点符号

①.当特征词为英文时:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
'''
英文文本特征提取
'''
data=['life is short,i like like python','life is too long,i dislike python ']
#实例化一个转换器类
transfer=CountVectorizer()
# 调用fit_tranform()
data_new=transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n',data_new)
#将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
count_demo()

②.当特征词为中文时:(不支持单个中文字)
每个字之间没有空格就会认为这句话是一个词:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_Chinese_demo():
"""
中文文本特征提取
"""
data = ['我爱北京天安门', '天安门最好看']
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_new = transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n', data_new)
# 将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
# count_demo()
count_Chinese_demo()

每个词之间有空格,他才能识别出来(手动分词),若想不进行手动分词,那就使用jieba库记性自动分词
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_Chinese_demo():
data = ['我 爱 北京 天安门', '天安门 最好看']
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_new = transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n', data_new)
# 将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
# count_demo()
count_Chinese_demo()

使用jieba库(中文自动分词)
例一:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
#返回生成器对象
a=jieba.cut(text)
print('生成器对象:',a)
#转换为列表
a = list(jieba.cut(text))
print('列表:',a)
#转换成字符串
a=''.join(list(jieba.cut(text)))
print('字符串:',a)
if __name__=='__main__':
cut_word('我爱北京天安门')

例二:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
text=" ".join(list(jieba.cut(text)))
return text
def count_Chinese_demo2():
"""中文文本特征抽取,自动分词
:return:"""
#1.将中文文本分词
data=["北京时间,常规赛下半段赛程正式打响,今天一共有两场比赛,奇才输给了灰熊,马刺输给了独行侠。",
'继火箭之后,马刺也将进入市场,开始甩卖老将,首当其冲就是球队功勋阿尔德里奇。',
'此外杜兰特也有坏消息,他的伤势问题,包括他如今带领的篮网也引来非议。']
data_new=[]#建一个空列表
for sent in data:
data_new.append(cut_word(sent))
print('新的,分好词的列表:\n',data_new)
#2.对分好词的新列表,进行文本特征抽取
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_final = transfer.fit_transform(data_new)
print('data_new:\n', data_final.toarray())
print('特征名字:\n', transfer.get_feature_names())
if __name__=='__main__':
count_Chinese_demo2()

方法一的缺点:无法找到关键词(在某一类文章中出现的次数很多,但是在其他类别的文章中出现次数很少)
方法二:Tf-idf()文本特征提取(在机器学习前期数据处理中很重要)
目的: 若一个词或者短语在一篇文章中出现的概率高,但是在其他文章中很少出现,则评估这个词后者端对这篇文章很重要。


from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
def tfidf_demo():
"""使用Tf-IDF进行中文文本特征抽取
:return:"""
#1.将中文文本分词
data=["北京时间,常规赛下半段赛程正式打响,今天一共有两场比赛,奇才输给了灰熊,马刺输给了独行侠。",
'继火箭之后,马刺也将进入市场,开始甩卖老将,首当其冲就是球队功勋阿尔德里奇。',
'此外杜兰特也有坏消息,他的伤势问题,包括他如今带领的篮网也引来非议。']
data_new=[]
for sent in data:
data_new.append(cut_word(sent))
print('新的,分好词的列表:\n',data_new)
#2.对分好词的新列表,进行文本特征抽取
# 实例化一个转换器类
transfer = TfidfVectorizer()
# 调用fit_tranform()
data_final = transfer.fit_transform(data_new)
print('data_new:\n', data_final.toarray())
print('特征名字:\n', transfer.get_feature_names())
if __name__=='__main__':
tfidf_demo()

结果的二维数组中概率大的值就是出现次数多的词,适合当关键词用于分类
总结:
特征抽取的目的:将原始数据进行特征值化,方便我们后续处理
1.对字典进行特征抽取:将字典数据中的类别转换为one-hot编码
2.对文本进行特征抽取:
法一:使用CountVectorizer(),统计每个样本特征词出现的个数
法二:计算Tf-idf()指标,评估这篇文章中每个词的重要程度
