- 矢量数据报文(Packet Vector) 与 标量报文
所谓的“矢量 Vector” 是与 “标量 Scalar” 报文处理相对而言的,矢量是一个自然科学术语,是一种既有大小、又有方向的量,又称为向量。在计算机科学中,矢量图 (Vector Graph)可以无线放大永不变形。
标量报文处理方式:
是人类常用的思维逻辑方式,即:报文时按照到达先后次序来处理,第一个报文处理完,在处理第二个,以此类推。 更为窗体的方式还需要结合处理中断,并遍历调用栈(e.g. calls b、calls c、calls d… return return return),然后从中断返回,函数会频繁嵌套调用。 最后,该过程执行后续三种操作之一 : a、不处理 , b、丢弃或重写、c、转发报文。
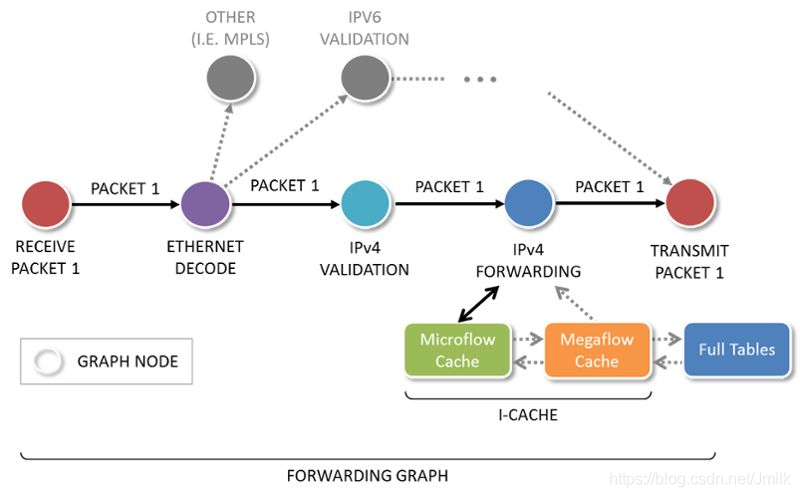
由此可见, 传统的标量报文处理方式、具有一个明显的缺陷 — I-Cache misses ( cpu 质量缓存抖动)。因为 Cache 具有时间局限性 、空间局限性的特点,所以每个数据报文都会产生一个 I-Cache misses 。面对这个问题,除了提供更大的 Cache 空间之外,没有解决方法。
矢量数据报文处理方式 :
矢量报文处理方式是一次处理多个报文,即,一次处理一个报文数组(Packet Vector) , 而非单个报文(Packet) 。把一批从底层硬件队列 Rx Ring (接收队列) 收到的报文,组成一个报文数组,称为 Packet Vector 矢量报文, 再助于 Packet Processing Graph 报文处理图 来组织处理流程。
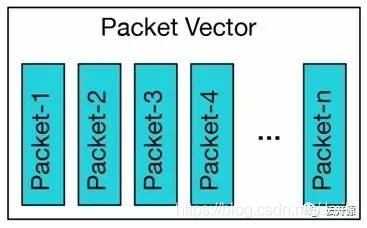
矢量报文处理方式积极地利用 Cache 的时间局限性特点,将一组 Packets 组织称一个 Packet Vector ,如果 I-Cache 命中, 则这一组 Packet 都会命中; 否则,都未命中。 而未命中时, 则通过 Packet Vector 中的第一个报文 Packet-1 为 I-Cache 镜像预热, 为 Packet Vector 中、后续的 Packets 进行 CPY 质量缓存加速。如此, Packet Vector 中剩下 Packets 的处理性能可以直接达到极限。
 简而言之,矢量报文处理方式、将整个 Packet Vector 的高速缓存 Miss Time 分摊到了第一个报文(packet-1) 的高速缓存 Miss Time , 使单个报文的处理开销显著降低。
简而言之,矢量报文处理方式、将整个 Packet Vector 的高速缓存 Miss Time 分摊到了第一个报文(packet-1) 的高速缓存 Miss Time , 使单个报文的处理开销显著降低。
由此可见,矢量报文处理解决了标量报文处理的主要性能缺陷,并具有如下优点:
a、 解决 I-Cache 抖动问题;
b、 对 I-Cache 进行预热、缓解读指令延时问题,高性能并且更加稳定。
- 数据报文的矢量图
VPP 的软件架构包括一个开发框架、和一系列根据 Packet Processing Graph 组织的 Graph Node 。
(2.1)Packet Processing Graph:
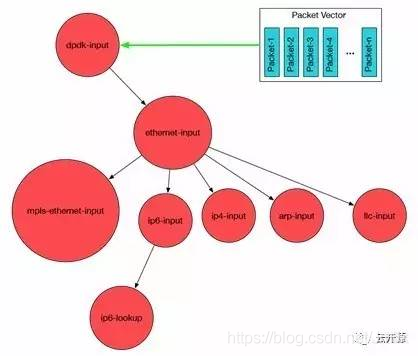
则由多个 Graph Node (姑且称 图节点)组成, Graph Node 把整个报文处理流程、分解为一个个先后连接的 Service Node (服务节点);Packet Vector 首先被第一个 Graph Node 处理, 然后依次被第二个、第N个 Graph Node 处理,依次类推。
(2.2)开发框架:
包含了基本的数据结构、定时器、驱动程序、在 Graph Node 间 分配 CPU 时间片的调度器、性能调优工具 (e.g. 计数器、抓包工具)。 VPP 的开发框架采用 Plugin 机制, Plugin Graph Node 与 VPP Build-in Graph Node 被同等对待, 从而有利于快速灵活地开发新功能。 因此, 插件机制使开发者能够充分利用现有模块、快速开发出新功能。 实际上,插件的本质就是实现了某一特定功能的 Graph Node, 但也可以是一个驱动程序或者CLI 。 Plugin Graph Node 能被插入到 VPP 的 Packet Processing Graph 中的任意位置。
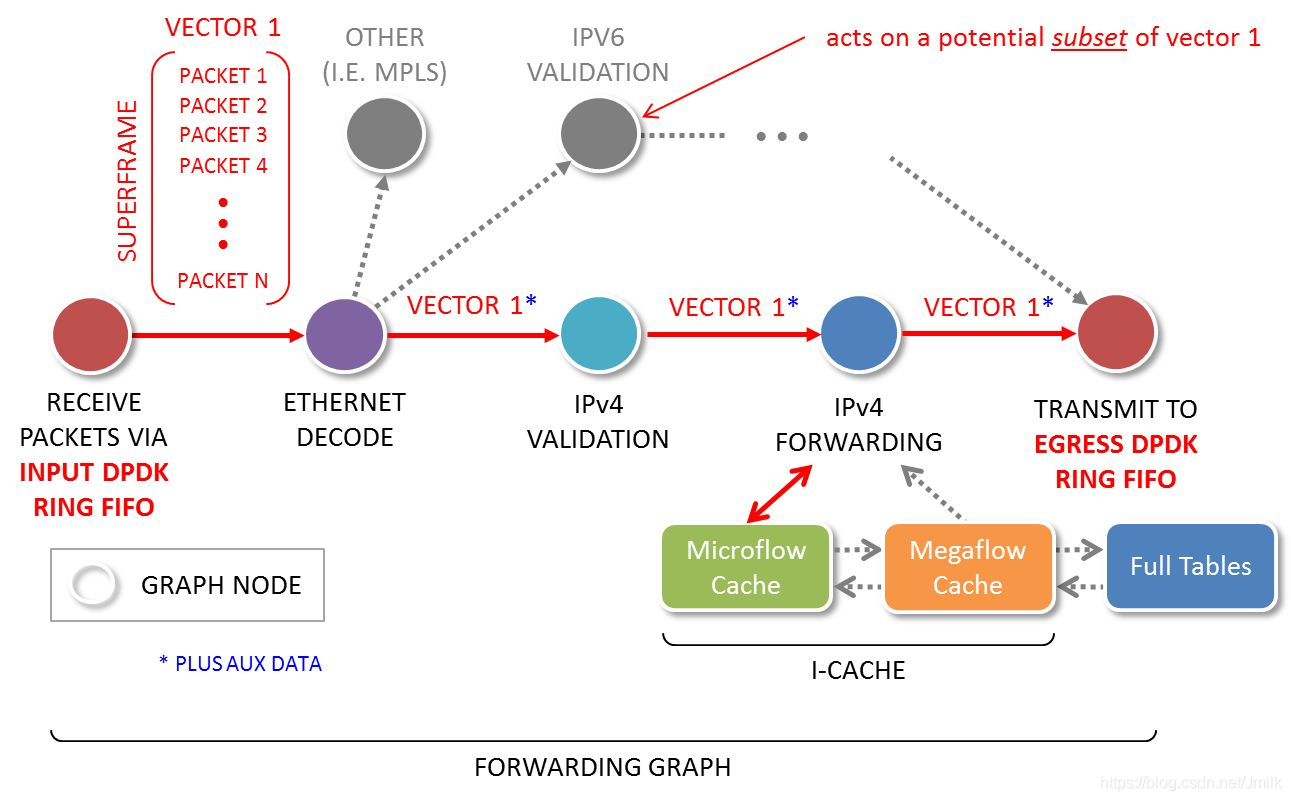
- Packet Processing Graph 处理流程
如下图
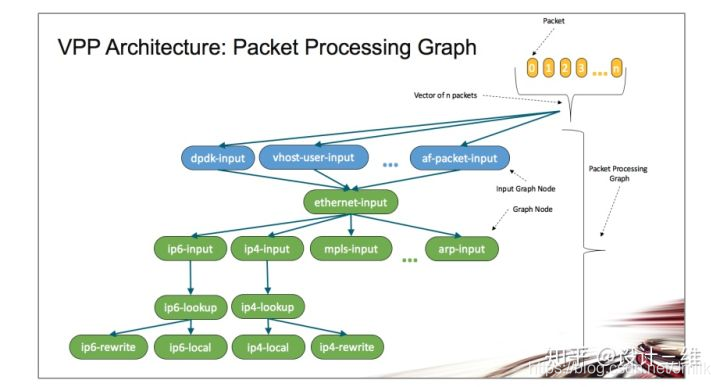 VPP 首先从 Input Node (输入节点)轮询以太网接口的接收队列,获取批量数据报文;接着把这些数据报文按照下一个 Graph Node 的功能组成一个 Packet Vector 或者 帧 (Frame) 。 比如: ethernet-input Node 收集所有 IPv6 的数据报文、并把他们传递给 ip6-input Node 。
VPP 首先从 Input Node (输入节点)轮询以太网接口的接收队列,获取批量数据报文;接着把这些数据报文按照下一个 Graph Node 的功能组成一个 Packet Vector 或者 帧 (Frame) 。 比如: ethernet-input Node 收集所有 IPv6 的数据报文、并把他们传递给 ip6-input Node 。
当 ip6-input Node 被调度时, 它取出第一个 packet-1 , 利用双循环 (Dual-Loop) 或 四循环( Quad-Loop) 以及通过预取报文到 cpu 缓存技术来处理报文, 可以有效减少 I-Cache miss 数量, 以达到最优性能。
当 ip6-input Node 节点处理完当前帧的所有报文后,把报文传递到后续不同的节点。比如:如果某报文检验失败、就被传递到 error-drop 节点。而正常报文被传递到 ip6-lookup 节点。 packet-1 依次通过不同的 Graph Node, 直到它们被 interface-output Node 发送出去。
-
Packet Processing Graph 的 Plugin 机制
VPP Packet Processing Graph 中的 Node 是 可以替代的, 这个特性和 VPP 支持动态加载 Plugin Node 的机制相结合时, 新功能可以被快速开发和部署,而不需要新建和编译一个定制的代码版本。
 简而言之, VPP 的 Graph Node 的组织方式, 使用户可以根据需求,通过 Plugin 的方式 插入新的 Graph Node 或者重新排列 Graph Nodes 的处理顺序,扩展非常方便, 也不会影响原有核心处理流程。
简而言之, VPP 的 Graph Node 的组织方式, 使用户可以根据需求,通过 Plugin 的方式 插入新的 Graph Node 或者重新排列 Graph Nodes 的处理顺序,扩展非常方便, 也不会影响原有核心处理流程。 -
Packet Processing Graph 的特性
(5.1) 每个 Graph Node 都利用 Packet Vector 作为输入/输出的最小处理单位;
(5.2) 从软件工程角度看,每个 Graph Node 都是独立和自治的;
(5.3) 从性能角度看,使可以优化 cpu 指令缓存 (I-Cache) 的使用,充分利用 CPU 的矢量结构,使报文内存加载和报文处理交织进行,达到更有效利用 CPU 处理流水线。
(5.4) 预测重用报文间的转发对象(比如:邻居表和路由表查找), 以及预先加载报文内容到 CPU 的本地数据缓存 (D-Cache) 供下一次循环使用,这些有效使用计算机硬件的技术, 使得 VPP 可以更细粒度的并行性。
VPP 的 Packet Processing Graph 特性,使它成为一个松耦合、且高度一致的软件架构,每一个 Graph Node 利用 Packet Vector 作为输入和输出的最小处理单位, 这就 提供松耦合特征。 通用功能被组合到每个 Graph Node 中, 这就提供高度一致的架构。
参考链接:
https://fd.io/
https://fd.io/documentation/
https://openfastpath.org/
https://www.metaswitch.com/blog/fd.io-takes-over-vpp
https://blog.csdn.net/Rong_Toa/article/details/107040703