文章目录
前言
Hive数据仓库在Hadoop的生态家族中占有及其重要的地位,并且实际的业务当中用的也非常多,可以说Hadoop之所以这么流行在很大程度上是因为Hive的存在。特别是针对离线数据仓库业务来说,基本都是在以hive为基础,进行分层设计,辅以调度系统,从而完成整个数据仓库业务的定时执行。本博文是在参考其他博主的优秀文章并且结合自己的理解与实际操作写下
一、Hive基本概念
1.1 什么是Hive
Hive:它是由Facebook开源用于解决海量结构化日志的数据统计。它是基于大数据生态圈hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。其本质是将HQL转化成MapReduce程序

从图示可以看出,Hive从某种程度上讲就是很多“SQL—MapReduce”框架的一个封装,可以将用户编写的Sql语言解析成对应的MapReduce程序,最终通过MapReduce运算框架形成运算结果提交给Client。
1.2 Hive的优缺点
优点:
① 操作接口采用类SQL语法,提供快速开发的能力。
② 避免了去写 MapReduce,减少开发人员的学习成本。
③ Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
④ Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
⑤ Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
① Hive的HQL表达能力有限。
② 迭代式算法无法表达。
③ Hive的效率比较低
④ Hive自动生成的MapReduce作业,通常情况下不够智能化。
⑤ Hive调优比较困难,粒度较粗。
1.3 Hive架构原理

1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java 访问 hive)、WEBUI(浏览器访问 hive)。
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。Hive将表中的元数据信息存储在数据库中,如derby(自带的)、Mysql(实际工作中配置的),Hive中的元数据信息包括表的名字、表的列和分区、表的属性(是否为外部表等)、表的数据所在的目录等。Hive中的解析器在运行的时候会读取元数据库MetaStore中的相关信息。在这里和大家说一下为什么在实际业务当中不用Hive自带的数据库derby,而要重新为其配置一个新的数据库Mysql,是因为derby这个数据库具有很大的局限性:derby这个数据库不允许用户打开多个客户端对其进行共享操作,只能有一个客户端打开对其进行操作,即同一时刻只能有一个用户使用它,自然这在工作当中是很不方便的,所以我们要重新为其配置一个数据库。
3.Hadoop
使用 HDFS 进行存储,使用MapReduce 进行计算。
4.驱动器:Driver
① 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如 antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
② 编译器(Physical Plan):将AST编译生成逻辑执行计划。
③ 优化器(Query Optimizer):对逻辑执行计划进行优化。
④ 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive来说,就是MR/Spark。
从上面的体系结构中可以看出,在Hadoop的HDFS与MapReduce以及MySql的辅助下,Hive其实就是利用Hive解析器将用户的SQl语句解析成对应的MapReduce程序而已,即Hive仅仅是一个客户端工具,这也是为什么我们在Hive的搭建过程中没有分布与伪分布搭建的原因。(Hive就像是刘邦一样,合理的利用了张良、韩信与萧何的辅助,从而成就了一番大事!)。
1.4 Hive运行机制

Hive的运行机制正如图所示:创建完表之后,用户只需要根据业务需求编写Sql语句,而后将由Hive框架将Sql语句解析成对应的MapReduce程序,通过MapReduce计算框架运行job,便得到了我们最终的分析结果。在Hive的运行过程中,用户只需要创建表、导入数据、编写Sql分析语句即可,剩下的过程将由Hive框架自动完成,而创建表、导入数据、编写Sql分析语句其实就是数据库的知识了,Hive的运行过程也说明了为什么Hive的存在降低了Hadoop的学习门槛以及为什么Hive在Hadoop家族中占有着那么重要的地位。
二、Hive的操作
在初步了解Hive的基本概念之后,我们将对Hive进行实践操作。所谓“纸上得来终觉浅,绝知此事要躬行”。首先建立一个txt格式的文本,数据如下所示:
id city name sex
1 beijing zhangli man
2 guizhou lifang woman
3 tianjin wangwei man
4 chengde wanghe woman
5 beijing lidong man
6 lanzhou wuting woman
7 beijing guona woman
8 chengde houkuo man
Hive的操作对于用户来说实际上就是表的操作、数据库的操作。下面将围绕两个方面进行介绍。
2.1 Hive表——内部表、外部表、分区表的创建
所谓内部表就是普通表,创建语法格式为:
create table tablename #内部表名
(
id int, #字段名称,字段类型
city string,
name string,
sex string
)
row format delimited #一行文本对应表中的一条记录
fields terminated by ‘\t’#指定输入文件字段的间隔符,即输入文件的字段是用什么分割开的。
实际操作(用beeline客户端模式):
beeline -u jdbc:hive2://node1:10000 -n "用户名" -p "密码"


结果:

外部表(external table)的创建语法格式为:
create external table teblename #外部表名
(
id int,
city string,
name string,
sex string
)
row format delimited #一行文本对应一条记录
fields terminated by ‘\t’ #输入文件的字段是用什么分割开的。
location ‘hdfs://mycluster/testDir’#与hdfs中的文件建立链接。
注意:最后一行写到的是目录testDir,文件就不用写了,Hive表会自动testDir目录下读取所有的文件file。实际的操作过程当中发现,location关联到的目录下面必须都是文件,不能含有其余的文件夹,不然读取数据的时候会报错。
实际操作:
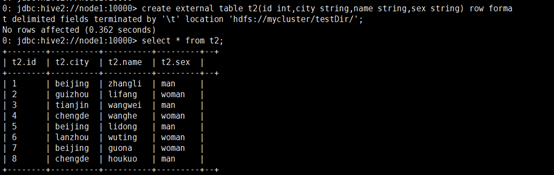
内部表与外部表的区别:
内部表在加载数据的过程中,实际数据会被移动到数据仓库目录中(hive.metastore.warehouse.dir),之后用户对数据的访问将会直接在数据仓库目录中完成;删除内部表时,内部表中的数据和元数据信息会被同时删除。
外部表在加载数据的过程中,实际数据并不会被移动到数据仓库目录中,只是与外部表建立一个链接(相当于文件的快捷方式一样);删除外部表时,仅删除该链接。补充:在工作中发现,对于外部表,即使hive中的表删除了,但是在HDFS中表的location仍然存在。
分区表
分区表的概念:指的是我们的数据可以分区,即按照某个字段将文件划分为不同的标准,分区表的创建是通过在创建表时启用partitioned by来实现的。
分区表的创建语法格式为:
create table tablename #分区表名
(
id int, #字段名称 字段类型
city string,
name string,
sex string
)
partitioned by(day int) #分区表字段
row format delimited #一行文本对应一条记录
fields terminated by ‘\t’ #输入文件的字段是用什么分割开的。
注意:分区表在加载数据的过程中要指定分区字段,否则会报错,正确的加载方式如下:
load data local inpath ‘/usr/local/consumer.txt’ into table t1 partition (day=2);
其余的操作和内部表、外部表是一样的。
实际操作:

2.2 将数据文件加载(导入)到Hive表中
在Hive中创建完表之后,随后自然要向表中导入数据,但是在导入数据的时候和传统数据库是不同的:Hive不支持一条一条的用insert语句进行插入操作,也不支持update的操作。Hive表中的数据是以load的方式,加载到建立好的表中。数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。导入数据的语法格式为:

导入数据时要注意以下几点:
- local inpath表示从本地linux中向Hive表中导入数据,inpath表示从HDFS中向Hive表中导入数据。
- 默认是向原Hive表中追加数据,overwrite表示覆盖表中的原数据进行导入。
- partition是分区表特有的,而且在导入数据数据时是必须添加的,否则会报错。
- load操作只是单纯的复制/移动操作,将数据文件复制/移动到Hive表对应的位置,即Hive在加载数据的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的表中。
三、Hive函数
3.1 系统内置函数:
- 查看系统自带的函数
hive> show functions;
- 显示自带的函数的用法
desc function upper;
- 详细显示自带的函数的用法
desc function extended upper;
3.2 系统内置常用函数:
- 数学函数
① round 四舍五入函数。
② ceil 向上取整函数。
③ sqrt 求平方根函数。
④ abs 求绝对值函数。
⑤ greatest 求一组数据中的最大值。
⑥ least 求一组数据的最小值。
⑦ cast 转换数据类型,成功返回结果,否则返回 Null。 - 字符串函数
① trim去空格函数。
② ltrim 左边去空格函数
③ rtrim 右边去空格函数。
④ concat_ws (separator,str1,str2,…) concat_ws第一个参数是其它参数的分隔符,分隔符的位置放在要连接的两个字符串之间,分隔符可以是一个字符串,也可以是其他参数。
3.3 自定义函数
- Hive 自带了一些函数,比如:max/min 等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
- 当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
- 根据用户自定义函数类别分为以下三种:
① UDF(User-Defined-Function)一进一出。
② UDAF(User-Defined Aggregation Function)聚集函数,多进一出
类似于:count/max/min。
③ UDTF(User-Defined Table-Generating Functions)一进多出,如 lateral view explore()。 - 官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins - 编程步骤:
① 继承org.apache.hadoop.hive.ql.UDF
② 需要实现 evaluate 函数;evaluate 函数支持重载;
③ 在 hive 的命令行窗口创建函数
a)添加jar
add jar linux_jar_path
b) 创建function
create [temporary] function [dbname.]function_name AS class_name;
④ 在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
- 注意事项
① UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
3.4 自定义UDF函数
- 创建一个Maven工程Hive
- 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
- 创建一个类
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
- 打成jar包上传到服务器/usr/local/testJar/udf.jar。
- 将jar包添加到hive的classpath。
hive(default)> add jar /usr/local/testJar/udf.jar;
- 创建临时函数与开发好的java class关联
hive(default)>create temporary function mylower as "com.atguigu.hive.Lower";
- 即可在hql中使用自定义的函数mylower
hive(default)> select ename, mylower(ename) lowername from emp;
3.5分析函数
分析函数:row_number() over()——分组TOPN
需求: 需要查询出每种性别中年龄最大的2条数据,数据如下
1,18,a,male
2,19,b,male
3,22,c,female
4,16,d,female
5,30,e,male
6,26,f,female
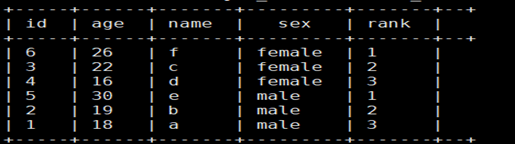
实际操作: 使用row_number函数,对表中的数据按照性别分组,按照年龄倒序排序并进行标记
select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber;
结果:
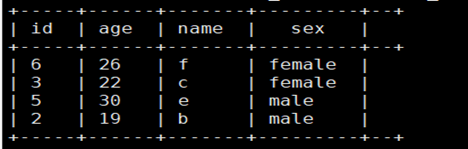
之后,利用上面的结果,查询出rank<=2的即为最终需求:
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber) tmp
where rank<=2;
结果:
3.6 转列函数
函数:explode()。数据如下
1,zhangsan,化学:物理:数学:语文
2,lisi,化学:数学:生物:生理:卫生
3,wangwu,化学:语文:英语:体育:生物
1.映射成一张表
create table t_stu_subject(id int,name string,subjects array<string>)
row format delimited fields terminated by ','
collection items terminated by ':';
2.导入数据
load data local inpath '/usr/local/testJar/subject.txt' overwrite into table t_stu_subject;

3用explode()对数组字段“炸裂”
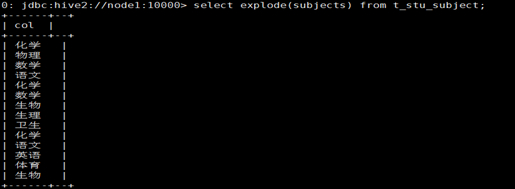
之后,利用这个explode的结果,来求去重的课程:
select distinct tmp.sub
from
(select explode(subjects) as sub from t_stu_subject) tmp;
结果:

四、综合案例
4.1 利用HQL去做统计
需要用hive做wordcount,有以下文本文件word.txt,
hello tom hello jim
hello rose hello tom
tom love rose rose love jim
jim love tom love is what
what is love
1.创建表
create table t_wc(sentence string);
2.导入数据
load data local inpath '/usr/local/testJar/word.txt' overwrite into table t_wc;
3.语句查询
SELECT word
,count(1) as cnts
FROM (
SELECT explode(split(sentence, ' ')) AS word
FROM t_wc
) tmp
GROUP BY word
order by cnts desc;
结果展示

总结
写下此篇博客,也是因为最近自己在做数仓方面的项目,清晰的讲解Hive,希望对大家有所帮助。