目录
可以直接运行的源码下载地址:https://download.csdn.net/download/weixin_43442778/15877803
视频演示链接:https://live.csdn.net/v/157249
1 课程设计目的
因为疫情的原因,大段时间会面对居家隔离的无聊,不如自己跟自己下一盘棋,“下一盘五子棋吧!”。此课程设计通过五子棋算法设计,加深对机器学习中强化学习概念的理解与应用。
2 设计任务与要求
谷歌旗下人工智能公司 DeepMind 发布了一篇新论文,它讲述了团队如何利用AlphaGo 的机器学习系统,构建了新的项目AlphaZero。AlphaZero使用了名为强化学习(reinforcement learning)的AI技术,它只使用了基本规则,没有人的经验,从零开始训练,横扫了棋类游戏AI。本次课程设计的任务如下:
1. 给出“自己与自己程序的对抗”的视频,给自己的棋盘加上自己特有的标签,作为你自己程序的论证(防抄袭),比如说,棋子有自己设计。
2. 按照提供的模板,填写课程设计报告。

图 2.1:五子棋谱
3 设计原理
3.1 强化学习
强化学习在这里主要由两个部分组成,一个部分是环境(environment),另一个部分是策略(policy)。环境由三个部分组成(状态(state),动作(action),奖励(reward))通俗点来讲,环境就是一个黑箱函数,该函数的输出为当前的state和上一个action的reward,而接受的输入为action。用围棋来举例子就是,围棋当前棋盘上的棋子的位置就是状态,而我们选择下了一步棋,那么棋盘的状态就发生了改变(多了一个字),我们之前选择下的那步棋的好坏就是我们的reward。而策略(policy)是在这里抽象为一个输入状态,输出action的函数。policy比较类似人类的思考过程,棋手(policy)通过观察棋盘(state),下了一步棋(做出action)。所以强化学习就可以理解为寻找一个输入状态输出动作,来使得我们的环境反馈的reward最大的一个函数。
3.2 蒙特卡洛树搜索
下面介绍与强化学习相结合的蒙特卡洛树搜索(MCTS),与普通的蒙特卡罗树有区别。蒙特卡罗树搜索本质上是一颗有不同节点(node)的树,节点与节点之间相连接。每个节点可以在这里可以代表一个棋盘的状态,假设我们的棋盘大小为15*15,而初始棋盘(棋盘上什么都没有的状态)的状态就是我们的最开始的根节点状态,而其下理论上有225个子节点,分别代表了初始玩家下在225个不同位置时的棋盘状态,而这225个字节点,每个子结点其下理论上又单独可有最多224的子节点,以此类推。对于每个节点,上面储存着该节点的访问次数(counter)与每一个子节点的Q值(每一个子节点相对于父节点来说代表着一个走子的动作{action},而Q值在这里可以简要理解为该动作好坏的评分)。
4 模型介绍
首先在我们的训练过程中,模型每次下出一步棋,会有两个流程。一个流程是模拟(simulation),一个是实际走子(play out)。模拟过程可以理解为,在我们正式走子之前,进行的预测(simulation),根据我们的预测结果来进行实际走子(play out)。
4.1 模拟
与传统蒙特卡罗树搜索不同,Alpha Zero的模拟是在神经网络输出结果指导下的模拟。传统的MCTS算法如图所示(图片来自于维基百科)。

图3.1 : 传统的MCTS算法
模拟过程一般会进行很多次,我们首先对其中一次进行讲解。对于传统的蒙特卡罗树搜索来说,首先基于选取一个“最优”动作(这里的最优要打引号,因为这并不是真的最优,而是当前该动作的一种综合 估计值+置信度 的衡量,具体后面讲UCB公式时我会讲。)。我们持续不断的选取“最优”动作,直到我们来到一个节点,并选择了一个我们之前从来每访问的动作,也因此这里并没有一个与该动作对应的节点。到这里我们完成了图中selection的部分。然后进入expansion部分,我们在这里创建新节点,记住,每次模拟只创建一个节点。然后进入MCTS的Simulation部分(注意这里的Simulation与上文中提到的模拟Simulation并不是同一个,做好区分)传统的MCTS会进行随机策略,抽象到棋盘上就相当于在棋盘上面随机走子。随机走子走到了尽头,我们就来到了Backpropagation的部分,我们将随机走子的结果(访问次数,胜负之类的信息)更新到这次模拟所经历的所有节点中,也就是说递归更新所有子节点的父节点。(对于一个节点来说,其执行一个动作会前进到其下的节点,其下的节点就是子节点,而相对于子节点来说,该节点就是父节点。如图中节点(12/21)是节点(7/10),节点(5/8),节点(0/3)的父节点,而这三个节点是(12/21)的子节点)。
我们这里使用的MCTS与传统的MCTS有所不同,首先在selection阶段,我们选择节点是根据神经网络指导下进行选择的,每次选择选取最大的upper confidence bound值的节点
UCB公式为:
![]()
其中
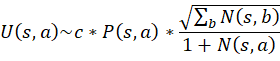
在这里UCB是一个权衡置信度(或者方差)和探索值的公式,通俗点来说,就是未探索的action和已经探索很多次但是探索反馈很高的action都会有较大的UCB值。Q值代表蒙特卡罗树中以探索的值,Q值的更新就是在之前蒙特卡罗树搜索中每一次backpropagation反馈的值的平均值。而P值是先验概率,是由神经网络计算得到的值,而N是该action的探索次数,而c是一个用于调节平衡模型探索的超参数。所以这个公式的特点就是,对于一个反复探索同时有很好的奖励的action,和缺乏探索的action都会有很高的值。这样就能很好的平衡探索与最优之间的平衡了。
其次的不同点是,在MCTS的backpropagation阶段,如果当前节点并没有分出胜负,是由神经网络进行打分(value),反馈的是value而不是随机探索出来的结果。具体value是什么我们放在神经网络阶段继续讲解。
4.2 走子
当模拟过程结束后,我们进入了走子过程。在这一步我们用不同action的探索次数之间的比例当作我们实际的概率分布,我们按照该概率分布选择我们的action(概率可以增加一点噪音做一些额外的exploration)。这里的概率分布要保存下来,训练神经网络的时候要用。我们按照“模拟 - 走子 - 模拟 - 走子”的流程一直走下去,直到我们的游戏结束。游戏结束的时候我们将游戏记录保存下来,可以用于神经网络的训练。
4.3 神经网络
神经网络输入为当前棋盘,原版输入是一个17x19x19的大型矩阵,有8个代表自己下棋的历史记录,8个代表对手下棋的历史记录,另外一个代表当前player。我们在这里也做一些简化,保留当前player的输入信息,将自己的历史记录和对手的历史记录都压缩为一个channel。这样我们的输入就为3 x board size x board size的矩阵。输出为双端口,分别为当前棋盘的状态值(value)和当前棋盘各个位置的走子的概率。更新的Loss function定义为:
![]()
其中v是value,z是当游戏结束的时候的实际的胜负,对于当前的player来说,如果他胜利了z的值就是+1,如果是失败了就是-1。在这里我们做一个回归的loss,经过大数据的训练,神经网络会掌握一个宏观的胜负概率的。而第二项是我们神经网络的输出与MCTS探索出来的概率分支之间的交叉熵,第三项就是一个L2正则项。
在这里我们选择普通的SGD进行优化,虽然Adam优化具有更好的收敛速度等优点,但是收敛性能却未必比SGD好。
5 仿真过程与结果


图5.1 开始界面


图5.2 最终结果
参考资料
- https://zhuanlan.zhihu.com/p/59567014