【召回】CF算法 — UI矩阵–》II矩阵
(1)以userid itemid score形式整理训练数据
总体思路:首先和cb一样,对处理完的用户元数据,物品元数据,行为数据进行cf数据准备工作,我们的目的事输出:
user,item score,其中主要是的到用户对item的score,其中用户收听的音乐的时常和总的时长相除得到score
python gen_cf_train.py
#coding=utf-8
import sys
input_file = "../data/merge_base.data"
# 输出cf训练数据
output_file = '../data/cf_train.data'
ofile = open(output_file, 'w')
key_dict = {
}
with open(input_file, 'r') as fd:
for line in fd:
ss = line.strip().split('\001')
# 用户行为
userid = ss[0].strip()
itemid = ss[1].strip()
watch_len = ss[2].strip()
hour = ss[3].strip()
# 用户画像
gender = ss[4].strip()
age = ss[5].strip()
salary = ss[6].strip()
user_location = ss[7].strip()
# 物品元数据
name = ss[8].strip()
desc = ss[9].strip()
total_timelen = ss[10].strip()
item_location = ss[11].strip()
tags = ss[12].strip()
#拼接key,为了将同一个用户对相同物品的时长全部得到,需要做个聚合
key = '_'.join([userid, itemid])
if key not in key_dict:
key_dict[key] = []
key_dict[key].append((int(watch_len), int(total_timelen)))
#循环处理相同用户对相同item的分数
for k, v in key_dict.items():
t_finished = 0
t_all = 0
# 对<userid, itemid>为key进行分数聚合
for vv in v:
t_finished += vv[0]
t_all += vv[1]
# 得到userid对item的最终分数
score = float(t_finished) / float(t_all)
userid, itemid = k.strip().split('_')
ofile.write(','.join([userid, itemid, str(score)]))
ofile.write("\n")
ofile.close()
得到如下数据:cf_train.data
userid, itemid, score
0189c9fecdd47bb64720c23a960272d3,935400252,1.3
014e7a8f4544bcd156365d3f348399c2,068800255,1.21889952153
00af96daaf12d1afa11d102f9f98fc3b,405100213,0.0581395348837
00383d3536ce00ad469cb1c57946686a,732009535,1.5703125
00fa3f43730a4374a43e1edfab614bb4,720400256,1.41509433962
0027834e40d613c175f715052aa341af,411500272,1.30735930736
00e5dd1b98a94f1976e49ffedc830e84,177200319,0.764705882353
(2)用ALS协同过滤算法跑出item-item数据 (套用协同过滤)
II矩阵数据准备,redis数据分为这么几个部分,这部分的数据需要利用到MapReduce框架,进行map和reduce排序。
一、MR实现CF算法
1.归一化,
归一化阶段我们主要是将相同的item进行单位模计算,把数据映射到0~1范围之内处理,更加便捷快速。因为后续我们要用到cos相似度计算公式,将相同的item的分数进行平方和再开根号,最后进行单位化。相似度的计算公式:
2.取pair对
相同用户两两取pair,输出两次,形成II矩阵
3.计算总和
将相同pair的分数相加
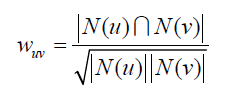
(1)归一化:
map阶段,只要将转数据换成item,user,score ,因为我们要在reduce阶段进行相同item单位化,要充分用到shuffle阶段的排序。
#!usr/bin/python
# -*- coding: UTF-8 -*-
'''
思路:转换成i,u,s的矩阵
'''
import sys
for line in sys.stdin:
ss = line.strip().split(',')
if len(ss) != 3:
continue
u , i , s = ss
print '\t'.join([i,u,s])
reduce阶段,我们需要将相同item平方和相加开根号,然后再单位化计算,最后输出。
#!usr/bin/python
# -*- coding: UTF-8 -*-
'''
在map的基础上将每个item进行归一化,map已经将相同的item排好序,根据map的结果进行给先平方再开根号:
思路 :
1、截取字符串,取出item,user,socre
2、在for循环中进行判断,当前的item和下一个是否相同,要是相同,将相同的放到列表(user,score)列表里面,否则往下执行
3、若不相同,循环user和score列表,计算模计算,然后再次循环,进行单位化计算
'''
import sys
import math
cur_item = None
user_score_list = []
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 3:
continue
item = ss[0]
userid = ss[1]
score = ss[2]
#wordcount判断,当前和下一个是否相同,相同添加到列表,不相同进行归一化计算
if cur_item == None:
cur_item = item
if cur_item != item:
#定义sum
sum = 0.0
#循环列表进行模向量计算
for ss in user_score_list:
user,s = ss
sum += pow(s,2)
sum = math.sqrt(sum)
#单位化计算
for touple in user_score_list:
u,s = touple
# 进行单位化完成后,我们输出重置成原来的user-item-score输出
print "%s\t%s\t%s" % (u, cur_item, float(s / sum))
#初始化这两个变量
cur_item = item
user_score_list = []
user_score_list.append((userid,float(score)))
#定义sum
sum = 0.0
#循环列表进行模向量计算
for ss in user_score_list:
user,s = ss
sum += pow(s,2)
sum = math.sqrt(sum)
#单位化计算
for touple in user_score_list:
u,s = touple
# 进行单位化完成后,我们输出重置成原来的user-item-score输出
print "%s\t%s\t%s" % (u, cur_item, float(s / sum))
(2)两两取pair对
思路:两两取pair对,我们在map阶段,其实什么都不用做,保证输出user,itemid,score即可。**
map阶段:
#!usr/bin/python
# -*- coding: UTF-8 -*-
#在进行pair取对之前,什么都不需要做,输出就行
import sys
for line in sys.stdin:
u, i, s = line.strip().split('\t')
print "%s\t%s\t%s" % (u, i, s)
reduce阶段:
将同一个用户下的item进行两两取对,因为要形成II矩阵,就必须以user为参考单位,相反形成uu矩阵,就必须以item参考,所以将同一个用户下的item进行两两取对,并将分数相乘,就得到临时这个相似度,因为还没有对相同pair对的分数相加,这个是最后一步要做的。
#!usr/bin/python
# -*- coding: UTF-8 -*-
'''
思路:进行map排好序之后,我们的会得到相同user对应的不同item和score,这里我们主要的思路是进行相同用户两两取pair
1、进行判断,当前用户和下一个用户是不是一样,若是不一样,我们进行两两取对,形成ii矩阵
2、若是相同,我们将不同的item和score放入list里面
'''
import sys
cur_user = None
item_score_list = []
for line in sys.stdin:
user,item,score = line.strip().split('\t')
if cur_user == None:
cur_user= user
if cur_user != user:
#进行两两pair,利用range函数
for i in range(0,len(item_score_list)-1):
for j in range(i+1,len(item_score_list)):
item_a, score_a = item_score_list[i]
item_b, score_b = item_score_list[j]
# 输出两遍的目的是为了形成II矩阵的对称
print "%s\t%s\t%s" % (item_a, item_b, score_a * score_b)
print "%s\t%s\t%s" % (item_b, item_a, score_a * score_b)
cur_user = user
item_score_list = []
item_score_list.append((item,float(score)))
#进行两两pair,利用range函数
for i in range(0,len(item_score_list)-1):
for j in range(i+1,len(item_score_list)):
item_a, score_a = item_score_list[i]
item_b, score_b = item_score_list[j]
# 输出两遍的目的是为了形成II矩阵的对称
print "%s\t%s\t%s" % (item_a, item_b, score_a * score_b)
print "%s\t%s\t%s" % (item_b, item_a, score_a * score_b)
(3)进行最终分数求和,我们最后的阶段是要将相同pair的分数相加才能得到两个item的相似度。
map阶段,将相同item对排序到一起,就要将pair组成一个key进行排序,将同一个partition后数据放倒一个reduce桶中,MapReduce框架shuffle阶段,key只是做排序,partition只是做分区,不要搞混了。
#!usr/bin/python
# -*- coding: UTF-8 -*-
'''
sum的map中,我们需要把相同的itemA,itemB组成key,为了使相同的key能够在shuffle阶段分配到同一个reduce中,
因为是计算item的相似度,要把相同的相加
'''
import sys
for line in sys.stdin:
item_a,item_b,score = line.strip().split('\t')
key = '#'.join([item_a,item_b])
print '%s\t%s' %(key,score)
reduce阶段主要任务就是将相同的item的pair对相加.
'''
思路:将相同的item的分数进行相加,得到最后的相似度
'''
import sys
cur_item = None
score = 0.0
for line in sys.stdin:
item, s = line.strip().split('\t')
if not cur_item:
cur_item = item
if cur_item != item:
ss = item.split("#")
if len(ss) != 2:
continue
item_a, item_b = ss
print "%s\t%s\t%s" % (item_a, item_b, score)
cur_item = item
score = 0.0
score += float(s)
ss = item.split("#")
if len(ss) != 2:
sys.exit()
item_a, item_b = ss
print "%s\t%s\t%s" % (item_a, item_b, score)
执行上述程序运行脚本run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
#要想cf代码直接改成cf_train.data
INPUT_FILE_PATH_1="/cf_train.data"
OUTPUT_PATH_1="/output1"
OUTPUT_PATH_2="/output2"
OUTPUT_PATH_3="/output3"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH_1
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH_2
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH_3
Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH_1 \
-mapper "python 1_gen_ui_map.py" \
-reducer "python 1_gen_ui_reduce.py" \
-jobconf "mapreduce.map.memory.mb=4096" \
-file ./1_gen_ui_map.py \
-file ./1_gen_ui_reduce.py
Step 2.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $OUTPUT_PATH_1 \
-output $OUTPUT_PATH_2 \
-mapper "python 2_gen_ii_pair_map.py" \
-reducer "python 2_gen_ii_pair_reduce.py" \
-jobconf "mapreduce.map.memory.mb=4096" \
-file ./2_gen_ii_pair_map.py \
-file ./2_gen_ii_pair_reduce.py
Step 3.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $OUTPUT_PATH_2 \
-output $OUTPUT_PATH_3 \
-mapper "python 3_sum_map.py" \
-reducer "python 3_sum_reduce.py" \
-jobconf "mapreduce.map.memory.mb=8000" \
-file ./3_sum_map.py \
-file ./3_sum_reduce.py
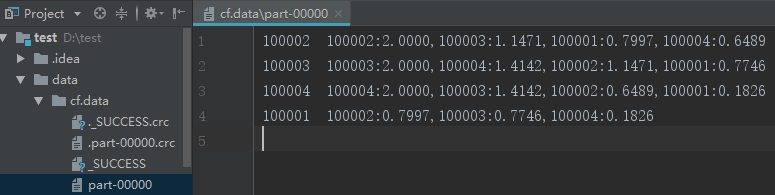
最后得到基于cf的ii矩阵
cf_train.data ,执行得到cf.result (最后一列没有超过1的)
000000228 006900337 0.495383099617
000000228 237400301 0.4655287556
000000228 489600256 0.327370227556
000000228 880800319 0.6522021568
000000228 895300223 0.0654423912424
(3)对数据格式化,item-> item list形式,整理出KV形式
python gen_reclist.py
结果统一放入放入redis,读kv,以itemid_A为key,其余两列追加为value,放到rec_dict。
区分key,加前缀CB_ ,SET为redis命令,实现批量灌入
#coding=utf-8
'''
思路:这个处理的逻辑和CB中完全一样,不一样的是redis的key是CF开头
'''
import sys
infile = '../data/cf.result'
outfile = '../data/cf_reclist.redis'
ofile = open(outfile, 'w')
MAX_RECLIST_SIZE = 100
PREFIX = 'CF_'
rec_dict = {
}
with open(input_file,'r') as fd:
for line in fd:
itemid_A, itemid_B, score = line.strip().split('\t')
#判断itemA在不在该字典里面,若不在,创建一个key为itemA的列表,把与itemA相关联的itemB和score添加进去
if itemid_A not in rec_dict:
rec_dict[itemid_A] = []
rec_dict[itemid_A].append((itemid_B, score))
#循环遍历字典,格式化数据,把itemB和score中间以:分割,不同的itemB以_分割
for k,v in rec_dict.items():
key = PREFIX+k
#接下来格式化数据,将数据以从大到小排列后再格式化
#排序,由于数据量大,我们只取100个
list = sorted(v,key=lambda x:x[1],reverse=True)[:MAX_RECLIST_SIZE]
#拍好序后,我们来格式化数据
result = '_'.join([':'.join([str(val[0]),str(round(float(val[1]),6))]) for val in list])
ofile.write(' '.join(['SET',key,result]))
ofile.write("\n")
ofile.close()
类似如下数据:
(4)灌库
unix2dos cf_reclist.redis
cat cf_reclist.redis | /usr/local/src/redis-2.8.3/src/redis-cli --pipe
验证:

接下来返回推荐系统文章第五步:https://blog.csdn.net/qq_36816848/article/details/108383078
二、Spark编写Scala实现CF算法
UI矩阵–>II矩阵–>排序
数据文件:user_item_score.data
下载链接:https://pan.baidu.com/s/1JH571UUbu_Hd2p2D1y87Rw 提取码:43vk
package spark.example
import org.apache.spark._
import SparkContext._
import scala.collection.mutable.ArrayBuffer
import scala.math._
object CollaborativeFiltering {
def main(args: Array[String]) {
if (args.length != 5) {
System.err.println("Usage: spark.example.CollaborativeFiltering <1:input> <2:output> <3:topn> <4:max_prefs_per_user> <5:score_threshold>")
System.exit(1)
}
val conf = new SparkConf().setAppName("CollaborativeFiltering")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0))
val output_path = args(1).toString
val topn = args(2).toInt
val max_prefs_per_user = args(3).toInt
val score_threshold = args(4).toDouble
/*
* Step 1.
* Obtain UI Matrix:
*/
val ui_rdd = lines.map {
x =>
val fields = x.split(" ")
(fields(0).toString, (fields(1).toString, fields(2).toDouble))
}.filter {
x =>
x._2._2 > score_threshold
}.groupByKey(4).flatMap {
x =>
val user = x._1
val is_list = x._2
val is_arr = is_list.toArray
var is_arr_len = is_arr.length
if (is_arr_len > max_prefs_per_user) {
is_arr_len = max_prefs_per_user
}
val i_us_arr = ArrayBuffer[(String, (String, Double))]()
for (i <- 0 until is_arr_len) {
i_us_arr += ((is_arr(i)._1, (user, is_arr(i)._2)))
}
i_us_arr
}.groupByKey().flatMap {
x =>
val item = x._1
val u_list = x._2
val us_arr = u_list.toArray
var sum: Double = 0
for (i <- 0 until us_arr.length) {
sum += pow(us_arr(i)._2, 2)
}
sum = sqrt(sum)
val u_is_arr = ArrayBuffer[(String, (String, Double))]()
for (i <- 0 until us_arr.length) {
u_is_arr += ((us_arr(i)._1, (item, us_arr(i)._2 / sum)))
}
u_is_arr
}.groupByKey().cache()
/*
* Step 2.
* Obtain II Matrix:
*/
val ii_rdd = ui_rdd.flatMap {
x =>
val is_arr = x._2.toArray.sortBy(_._1)
val ii_s_arr = ArrayBuffer[((String, String), Double)]()
for (i <- 0 until is_arr.length) {
for (j <- (i + 1) until is_arr.length) {
ii_s_arr += (((is_arr(i)._1, is_arr(j)._1), is_arr(i)._2 * is_arr(j)._2))
}
}
ii_s_arr
}.groupByKey().map {
x =>
val ii_pair = x._1
val s_list = x._2
val s_arr = s_list.toArray
val len = s_arr.length
var s:Double = 0.0
for (i <- 0 until len) {
s += s_arr(i)
}
(ii_pair._1, (ii_pair._2, s))
}.flatMap {
x =>
val arr = ArrayBuffer[(String, (String, Double))]()
arr += ((x._1, (x._2._1, x._2._2)))
arr += ((x._2._1, (x._1, x._2._2)))
arr
}.groupByKey().map {
x =>
val bs_list = x._2
val bs_arr = bs_list.toArray.sortWith(_._2 > _._2)
var l = bs_arr.length
if (l > topn) {
l = topn
}
val s = new StringBuilder
for (i <- 0 until l) {
val score = "%1.8f" format bs_arr(i)._2
val tmp_s = bs_arr(i)._1 + ":" + score
s.append(tmp_s)
if (i != (l - 1)) {
s.append(",")
}
}
x._1 + "\t" + "\t" + s
}.saveAsTextFile(output_path)
}
}
输出结果: