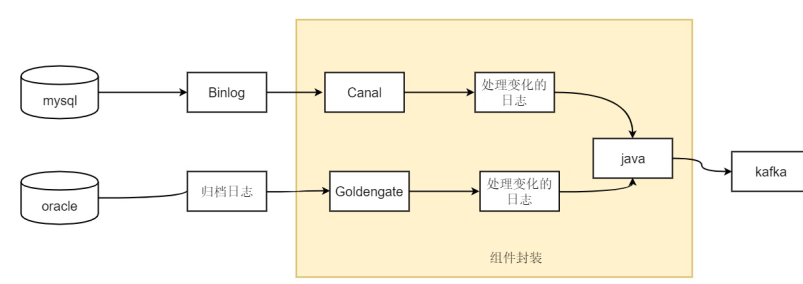
Flume基础
1、Flume是什么?
Flume是数据采集,日志收集的框架,通过分布式形式进行采集,(高可用分布式)
本质:可以高效从各个网站服务器中收集日志数据,并且存储到HDFS、hbase
2、Flume可以对接的数据源?
Console、RPC、Text、Tail、Syslog、Exec等
3、Flume接受的数据源输出目标?
磁盘,hdfs,hbase, 经过网络传输kafka
data->flume->kafka->spark streaming/ storm / flink -> hbase,mysql
4、agent部署在一台服务器中的进程,负责收集该服务器的日志数据
5、flume使用event使用event对象作为数据传递的格式,是内部数据传输的基本单元
两部分组成:通过一个转载数据的字节数组+一个可选头部构成
6、agent:三个重要组件:
source : 表示flume的数据源
channel: 存储池
file: 保证数据不丢失,速度相对较慢
memory: 数据可能会丢失,速度较快
当数据传输完成之后,该event才从通道中进行移除--(可靠性)
sink: 将event传输到外部介质
• 功能:
– 支持在日志系统中定制各类数据发送方,用于收集数据
– Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力
Flume特性
- Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume 可以采集文件,socket 数据包、文件、文件夹、kafka 等各种形式源数据,
- 又可以将采集到的数据输出到 HDFS 、hbase 、hive 、kafka 等众多外部存储系统中
- 对一般的采集需求,通过对 flume 的简单配置即可实现
- Flume 针对特殊场景也具备良好的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景
- Flume 的管道是基于事务,保证了数据在传送和接收时的一致性.
- Flume 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等。
Flume核心
Flume 事件
• Event对象是Flume内部数据传输的最基本单元
• 两部分组成:Event是由一个转载数据的字节数组+一个可选头部构成
• Event由零个或者多个header和正文body组成
• Header 是 key/value 形式的,可以用来制造路由决策或携带其他结构化信息(如事件的时间戳或事件来源的服务器主机名)。你可以把它想象成和 HTTP 头一样提供相同的功能——通过该方法来传输正文之外的额外信息。
• Body是一个字节数组,包含了实际的内容
headers (可有可无) -> key
body(数据) -> value
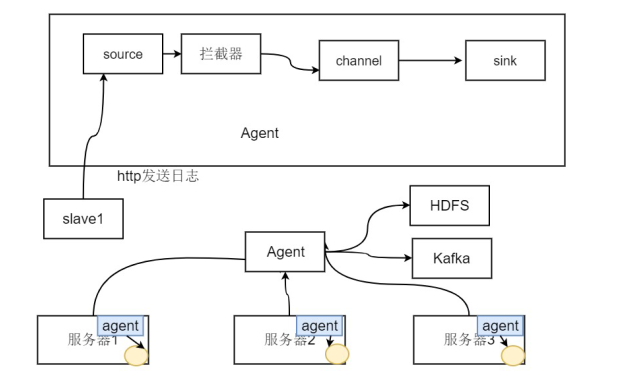
Flume Agent
• Flume内部有一个或者多个Agent
• 每一个Agent是一个独立的守护进程(JVM)
• 从客户端哪儿接收收集,或者从其他的Agent哪儿接收,然后迅速的将获取的数据传给下一个目的节点Agent
• Agent主要由source、channel、sink三个组件组成。
Agent Source
• 一个Flume源
• 负责一个外部源(数据发生器),如一个web服务器传递给他的事件
• 该外部源将它的事件以Flume可以识别的格式发送到Flume中
• 当一个Flume源接收到一个事件时,其将通过一个或者多个通道存储该事件
Agent Channel
• 通道:采用被动存储的形式,即通道会缓存该事件直到该事件被sink组件处理
• 所以Channel是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着桥梁的作用,channel是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接
• 可以通过参数设置event的最大个数
• Flume通常选择FileChannel,而不使用Memory Channel
– Memory Channel:内存存储事务,吞吐率极高,但存在丢数据风险
– File Channel:本地磁盘的事务实现模式,保证数据不会丢失(WAL实现)write ahead log ( 将日志预写先写到磁盘)
Agent Sink
• Sink会将事件从Channel中移除,并将事件放置到外部数据介质上
– 例如:通过Flume HDFS Sink将数据放置到HDFS中,或者放置到下一个Flume的Source,等到下一个Flume处理。
– 对于缓存在通道中的事件,Source和Sink采用异步处理的方式
• Sink成功取出Event后,将Event从Channel中移除
• Sink必须作用于一个确切的Channel
• 不同类型的Sink:
– 存储Event到最终目的的终端:HDFS、Hbase
– 自动消耗:Null Sink
– 用于Agent之间通信:Avro
拦截器Agent Intercepto
• Interceptor用于Source的一组拦截器,按照预设的顺序必要地方对events进行过滤和自定义的
处理逻辑实现
• 在app(应用程序日志)和 source 之间的,对app日志进行拦截处理的。也即在日志进入到
source之前,对日志进行一些包装、清新过滤等等动作
• 官方上提供的已有的拦截器有:
– Timestamp Interceptor:在event的header中添加一个key叫:timestamp,value为当前的时间戳
– Host Interceptor:在event的header中添加一个key叫:host,value为当前机器的hostname或者ip
– Static Interceptor:可以在event的header中添加自定义的key和value
– Regex Extractor Interceptor:通过正则表达式来在header中添加指定的key,value则为正则匹配的部分
• flume的拦截器也是chain形式的,可以对一个source指定多个拦截器,按先后顺序依次处理
选择器Agent Selector
• channel selectors 有两种类型:
Replicating Channel Selector (default):将source过来的events发往所有channel
Multiplexing Channel Selector:而Multiplexing 可以选择该发往哪些channel
• 对于有选择性选择数据源,明显需要使用Multiplexing 这种分发方式
• 问题:Multiplexing 需要判断header里指定key的值来决定分发到某个具体的channel,如果demo和demo2同时运行在同一个服务器上,如果在不同的服务器上运行,我们可以在 source1上加上一个 host 拦截器,这样可以通过header中的host来判断event该分发给哪个channel,而这里是在同一个服务器上,由host是区分不出来日志的来源的,我们必须想办法在header中添加一个key来区分日志的来源
通过设置上游不同的Source就可以解决
可靠性:
• Flume保证单次跳转可靠性的方式:传送完成后,该事件才会从通道中移除
• Flume使用事务性的方法来保证事件交互的可靠性。
• 整个处理过程中,如果因为网络中断或者其他原因,在某一步被迫结束了,这个数据会在下一次重新传输。
• Flume可靠性还体现在数据可暂存上面,当目标不可访问后,数据会暂存在Channel中,等目标可访问之后,再
进行传输Taildir断点重传
• Source和Sink封装在一个事务的存储和检索中,即事件的放置或者提供由一个事务通过通道来分别提供。这保证
了事件集在流中可靠地进行端到端的传递。
– Sink开启事务
– Sink从Channel中获取数据
– Sink把数据传给另一个Flume Agent的Source中
– Source开启事务
– Source把数据传给Channel
– Source关闭事务
– Sink关闭事务
Flume实践:
agent进行重命名: a1
sources: r1
sinks: k1
channels: c1
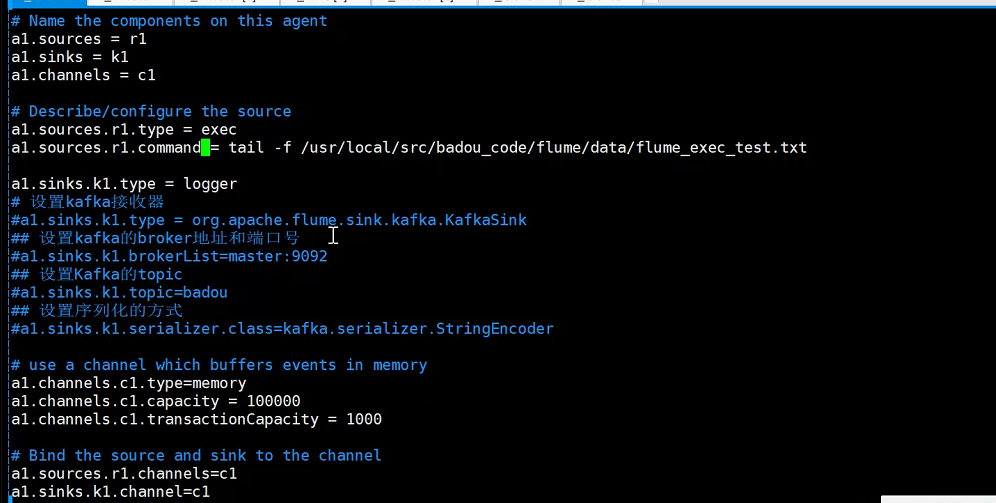
]# vim flume.conf
运行flume-ng
./bin/flume-ng agent --conf conf --conf-file ./conf/flume.conf -name a1 -Dflume.root.logger=DEBUG,console
需求1:通过netcat作为source, sink为logger的方式
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console
需求2:通过netcat作为source, sink为logger的方式,现在我之关心字母,过滤掉数字
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console
需求3:通过netcat作为source, sink写到hdfs
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console
如何设置flume防止小文件过多?
a、限定一个文件的文件数据大小
a1.sinks.k1.hdfs.rollSize = 200*1024*1024
b、限定文件可以存储多少个event
a1.sinks.k1.hdfs.rollCount = 10000
需求4:通过HTTP作为source, sink写到logger
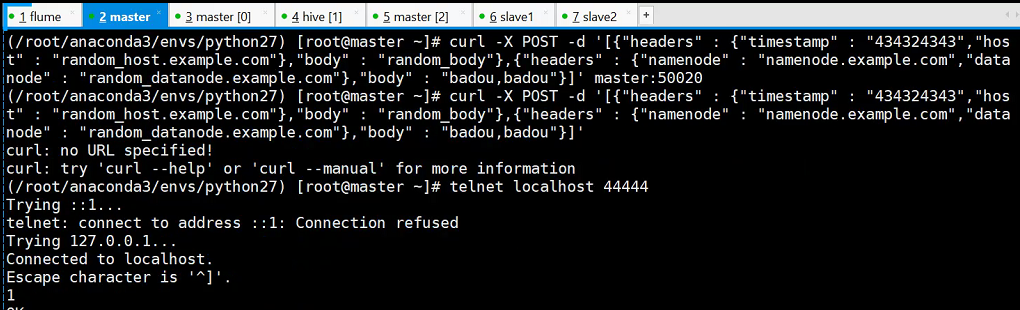
./bin/flume-ng agent --conf conf --conf-file ./conf/header_test.conf -name a1 -Dflume.root.logger=INFO,console
curl -X POST -d '[{"headers" : {"timestamp" : "434324343","host" : "random_host.example.com"},"body" : "random_body"},{"headers" : {"namenode" : "namenode.example.com","datanode" : "random_datanode.example.com"},"body" : "badou,badou"}]' master:50020
这里通过slave1也可以正常访问
需求5:将agent进行串联操作 agent->agent
1、slave2:
./bin/flume-ng agent -c conf -f conf/pull.conf -n a2 -Dflume.root.logger=INFO,console
2、master:
./bin/flume-ng agent -c conf -f conf/push.conf -n a1 -Dflume.root.logger=INFO,console
3、在master上执行
telnet localhost 44444
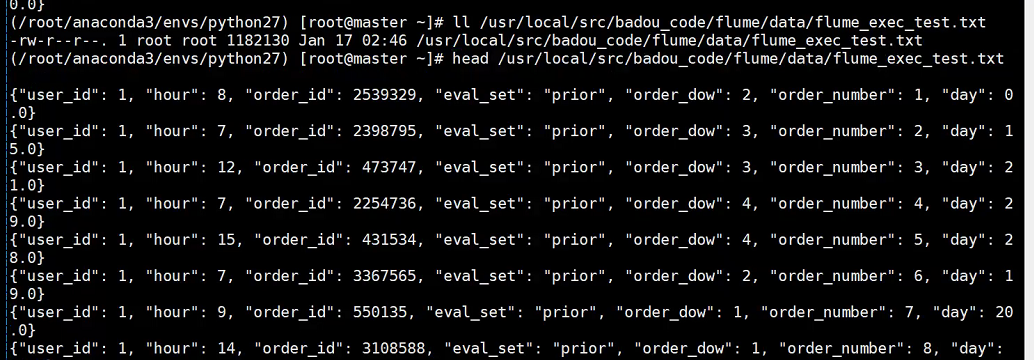
需求5:通过flume监控日志文件的变化,然后最终sink到logger ,得到json格式文件
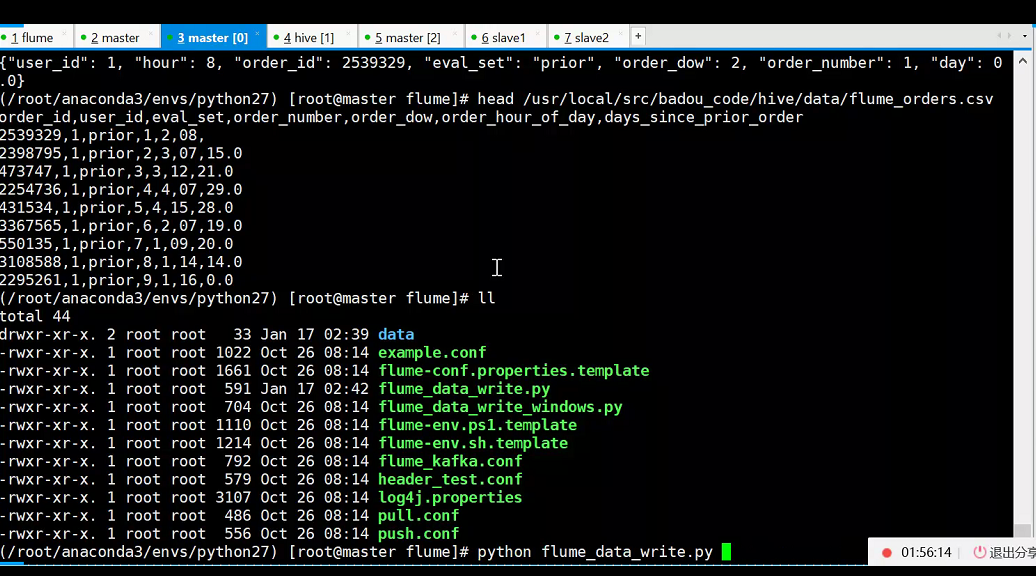
python flume_data_write.py
./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger=INFO,console
需求6:flume+kafka
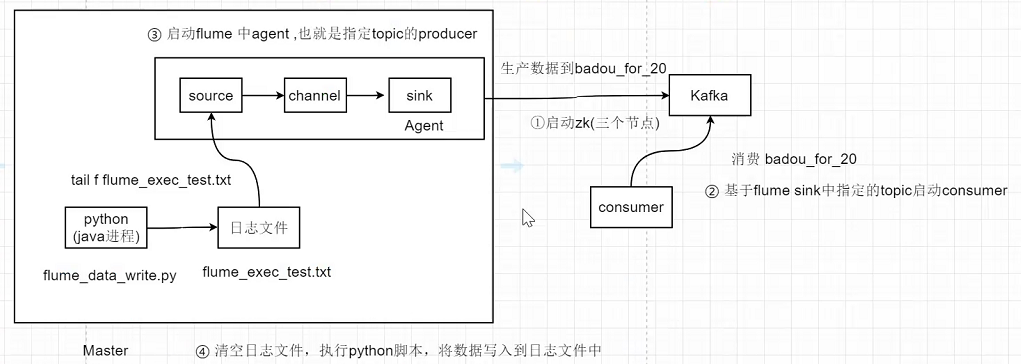
1.先启动zookeeper
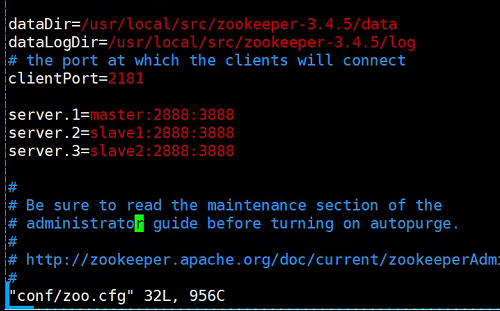
./zkServer.sh start
zookeeper配置:1. vim zoo.cfg 2. vim data/myid 是第几台写数字几
2.master启动kafka(端口9092)
./bin/kafka-server-start.sh config/server.properties & (后台启动)
三种方式查看进程是否正常启动:
jobs -l : 查看后台进程
ps -ef | grep 32918 : 查看后台进程
netstat -anp | grep 9092: 查看端口号
-- 查看kafka topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
-- 创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic badou_for_20
-- 消费badou_for_20 topic
./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic badou_for_20 --from-beginning
3、启动flume
./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger=INFO,console
4、清空日志文件
echo '' > flume_exec_test.txt
5、执行python flume_data_write.py, 模拟将后端日志写入到日志文件中
# -*- coding: utf-8 -*-
import random
import time
import pandas as pd
import json
writeFileName="/usr/local/src/badou_code/flume/data/flume_exec_test.txt"
cols = ["order_id","user_id","eval_set","order_number","order_dow","hour","day"]
df1 = pd.read_csv('/usr/local/src/badou_code/hive/data/orders.csv')
df1.columns = cols
df = df1.fillna(0)
with open(writeFileName,'a+')as wf:
for idx,row in df.iterrows():
d = {}
for col in cols:
d[col]=row[col]
js = json.dumps(d)
wf.write(js+'\n')
# rand_num = random.random()
# time.sleep(rand_num)