目录
note:该笔记以 MySql 数据库为例
1. DDL(Data Define Language) 语句
1.1 对数据库的操作
1.1.1 查看当前数据库
# 查看当前数据库
show databases;
# 查看创建数据库的定义信息
show create database mydb2;
# 查看当前正在被操作的数据库
select database();
# 切换/使用某个数据库
use mydb1;
1.1.2 创建数据库
# 创建数据库 mydb1
create database mydb1;
# 创建数据库 mydb1 如果其不存在
create database if not exists mydb1;
# 创建数据库并设置其编码格式
create database mydb2 character set gbk;
1.1.3 修改数据库
# 修改数据库的信息
alter database mydb2 character set utf8;
1.1.4 删除数据库
# 删除数据库
drop database mydb2;
# 按某种条件删除数据库
drop database if exists mydb2;
1.1.5 退出数据库
# 推出数据库
quit;
or
exit;
1.2 对数据表的操作
1.2.1 创建数据表

# 创建数据表
create table student(id int not null,name varchar(20) not null ,age int not null);
# 跨行创建
mysql> create table users(
-> id int not null
-> );
1.2.2 查看数据表
# 查看数据表的创建语句(定义信息)
show create table student;
# 查看数据表的内容
select * from student;
# 查看所有的数据表
show tables;
# 显示表结构
desc student;
1.2.3 常见的约束
1. not null:非空
1.2.4 删除数据表
# 删除数据表
drop table users2;
1.2.5 修改数据表
# 增加一列
alter table student add address varchar(50);
# 修改某列的内容
# 这里要注意,如果本身该列设置了 not null 约束,那么修改时也要加上该约束,否则该约束被取消(不能改名字)
alter table student modify name varchar(30) not null;
# 删除某列
alter table student drop address;
# 数据表重命名
rename table student to user;
#数据表某一列的列名的修改
# 将 user 表中的 name 列改为 names 列(可以改名字)
alter table user change name names varchar(30) not null;
# 修改表的字符集
alter table account default character set utf8;
2. DML(Data Manage Language)语句
note:
1.对表中的数据进行增(insert),删(delete),改(update)列的数据,没有查
2.mysql 中,字符串和日期都需要用 ’ ’ (单引号)括起来
3.空值为 null
4.命令行中,最好不要使用中文
2.1 插入列值
# 插入多列值
insert into user(id,names,age) values (1,'zhangsan',18);
2.2 临时修改客户端和服务器编码
set names 'gbk';
2.3 修改列值
# 修改列值
update user set address= '北京市' where names='a';
# 修改多列值
update user set age=10,names='wangwu' where id=1;
2.4 删除列值
# 删除某列值
delete from user where names='wangwu';
# 删除表中所有数据
delete from user
note:
- delete 和 truncate 的区别:delete 是把所有内容删空,但结构还在。truncate 是把表扔掉,重新建一个新表,truncate 删除的数据不能找回,但速度快,但 delete 可以保留数据日志。
3. DQL(Data Query Language)语句
查询语句

note:
- 基础查询都是返回的虚拟表
3.1 常见的查询方式
# 利用运算符查询
# != 和 <> 一样
SELECT sname FROM stu WHERE age=35;
# between...and
# 前小后大
SELECT sid,sname,age FROM stu WHERE age BETWEEN 35 AND 37;
# IN 在某条件内查询
SELECT * FROM stu WHERE age IN (35,36,37);
# 多个非的结果
SELECT * FROM stu WHERE age NOT IN (35,36,37);
3.2 模糊查询
关键字:LIKE
通配符:
1. _:匹配一个字符
2. %:匹配任意数量字符
# 查询含 L 后只匹配一个字符的
# _ 有几个,就可以查询几个
SELECT * FROM stu WHERE sname LIKE 'l_';
# 查询含 L 前后任意数量字符的
SELECT * FROM stu WHERE sname LIKE '%l%';
3.3 字段控制和字段查询
# 去除重复记录(去除 age 字段重复的记录)
SELECT DISTINCT age FROM stu
# 求和查询
SELECT *,age+10 FROM stu
# 求和查询,如果 fee 列是 null,此时不能直接加
# 会导致结果为 null,此时需要将 null 替换成 0
SELECT *,pay+IFNULL(fee,0) FROM teacher
# 字符串拼接查询,+ 只能用于算数加法
SELECT CONCAT(sid,': ',sname) FROM stu
# 添加别名 【as 别名】
SELECT CONCAT(sid,': ',sname) AS '编号:名字' FROM stu
# 排序(默认升序)
SELECT CONCAT(sid,': ',sname) AS '编号:名字' FROM stu
# 排序(降序)
SELECT * FROM stu ORDER BY age DESC
# 多列排序,要求先满足前面的排序,再满足后面的排序
SELECT * FROM teacher ORDER BY sid DESC,age DESC
3.4 聚合函数
# count() 按纵向统计非空行数
SELECT COUNT(*) AS ‘非空’ FROM stu
# max() 统计最大值,null 不参与计算
SELECT MAX(age) FROM stu
# sum() 求和,null 不参与计算
# avg() 求平均值,null 不参与计算,会取小数
3.5 分组查询
# 分组查询 【group by】
# 和聚合函数一起作为查询条件的列,作为分组条件
select count(*),group from teacher group by group
# having 字句
# having 用于筛选结果是在计算后实现的内容
select group sum(sal) from teacher group by group having sal > 10000
# limit 限制,限制查询结果的起始行和总行数
# 从 0 行开始,查询 2 行
SELECT * FROM stu LIMIT 0,2
3.6 多表查询
多表约束:外键约束
多表的关系
- 一对多,建表原则,多的一方创建一个字段,字段作为外键指向“一”的一方。比如老师-学生,学生为多,学生表中有一个老师字段,该字段指向老师表
- 多对多,建表原则,需要创建第三张表,表中至少两个字段,两个字段作为外键,指回各自表的主键。
- 一对一
多表查询
-
合并结果集:union(去重), union all(不去重)
-
连接查询,横向合并,多表乘积,即如 t1 有 3 行,t2 有 2 行,则连接查询结果集是 3*2 得 6 行
-

内连接 [inner] join on,先判断 on 的条件,再查询结果
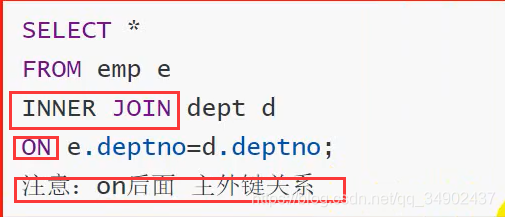
外连接 outer join on
左外连接 left [outer] join,先查询 emp (左表)表在判断条件 on,未匹配到则返回 null
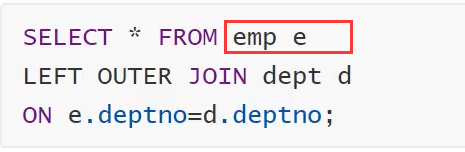
右外连接 right [outer] join
左右外连接的使用场景, -
子查询
一个 select 语句中包含另一个 select 语句
位置:
- where 后,被查询的一部分
a. any,
b. all, - from 后,作为临时表

note
- unoin 纵向合并,必须要两个表的列数相等,但列数据类型可以不同
# 合并集
SELECT * FROM t1 UNION SELECT * FROM t2;
# 使用连接查询,往往需要进行过滤,才可以得到需要的结果
SELECT * FROM link1 ,link2 WHERE link1.id = link2.id
# 内连接
4. 完整性约束
需要的数值,均处于数值正确的状态。
比如,年龄应该是整数,如果输入小数就不完整了,还比如,要求输入 5 个数值,你只输入了 3 个,也叫不完整 。
当你确保数据的完整性就是添加约束
完整性分类
- 实体完整性:一行就是一个实体,标识一行数据不重复,实体唯一性
a. 主键约束,数据唯一,不能为空,一般在创建表时添加
b. 唯一约束
c. 自动增长列 - 域完整性:列
- 引用完整性:多表之间,B 表中的数据 b 引用自 A 表中的数据 a

# 主键约束
# 第一种添加方式
CREATE TABLE stu
(
id INT PRIMARY KEY,
`name` VARCHAR(50)
)CHARSET= utf8;
# 第二种添加方式,可以创建联合主键
CREATE TABLE stu3
(
id INT,
`name` VARCHAR(50),
idCard INT,
# 当 id 和 idCard 都重复时才报错
PRIMARY KEY(id,idCard)
)CHARSET= utf8;
# 第三种方式
CREATE TABLE stu4
(
id INT ,
`name` VARCHAR(50),
idCard INT,
)CHARSET= utf8;
ALTER TABLE stu4 ADD PRIMARY KEY(id);
# 唯一约束 【unique】
# 数据不能重复但可以为 null
CREATE TABLE stu6
(
id INT PRIMARY KEY,
`name` VARCHAR(10) UNICODE
)CHARSET=utf8;
# varchar(),具有自动压缩的功能,即末尾的空格会被自动消除
# 自动增长列
# 不能单独使用,需要和主键配合
# 给主键添加自动增长的数值,列只能是数值类型
# 自动增长的列可以不写,程序自动添加
CREATE TABLE stu7
(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(10) UNICODE
)CHARSET=utf8,,AUTO_INCREMENT=100;
# AUTO_INCREMENT=100,指定初始值
# 域完整性
# 约束该列只能使用的数据类型
# 非空约束
# 默认值【default】
# 引用完整性约束
CREATE TABLE stu5
(
sid INT PRIMARY KEY,
`name` VARCHAR(20) NOT NULL,
sex VARCHAR(5) DEFAULT '女'
)CHARSET= utf8;
CREATE TABLE score
(
id INT,
score DOUBLE(5,2),
sid INT,
# 引用完整性约束
# fk_score_sid 是自取的名字
CONSTRAINT fk_score_sid
FOREIGN KEY(sid)
REFERENCES stu5(sid)
)CHARSET=utf8;
# 此时不能删除主表(stu5),要先删除从表,才能删除主表
# 外键列和主键列的数据类型要一致
5. 事务
- 一组要么同时执行成功,要么同时执行失败的 SQL 语句,即原子操作
- 一个事务将会产生永久性的持久化改变,也就是说,insert,update 等,都是一个事务
- 其中关键字 commit 表示成功,rollback 表示失败(有一个失败就失败)
- 事务的四大特点:原子性,一致性(同成功,同失败),隔离性(不会出现中间状态的结果),持久性(永久改变)
# 开启事务
START TRANSACTION;
INSERT INTO account(`name`,money)VALUES('lili',10000);
# 失败则回滚
ROLLBACK;
# 成功则提交
COMMIT;
6. 常用函数(谷歌)
7. 导出导入数据库
7.1 命令方式
# 导出数据库到 f:/test.sql
# 类似于对现在的库做了一个备份
mysqldump -u root -p mydb2 >f:/test.sql
# 导入数据库到一个已经选择的数据库
# 先登录 mysql
use mydb1;
source f:/test.sql
7.2 通过可视化工具(sqlyog)
8. 创建用户和授权
8.1 创建用户
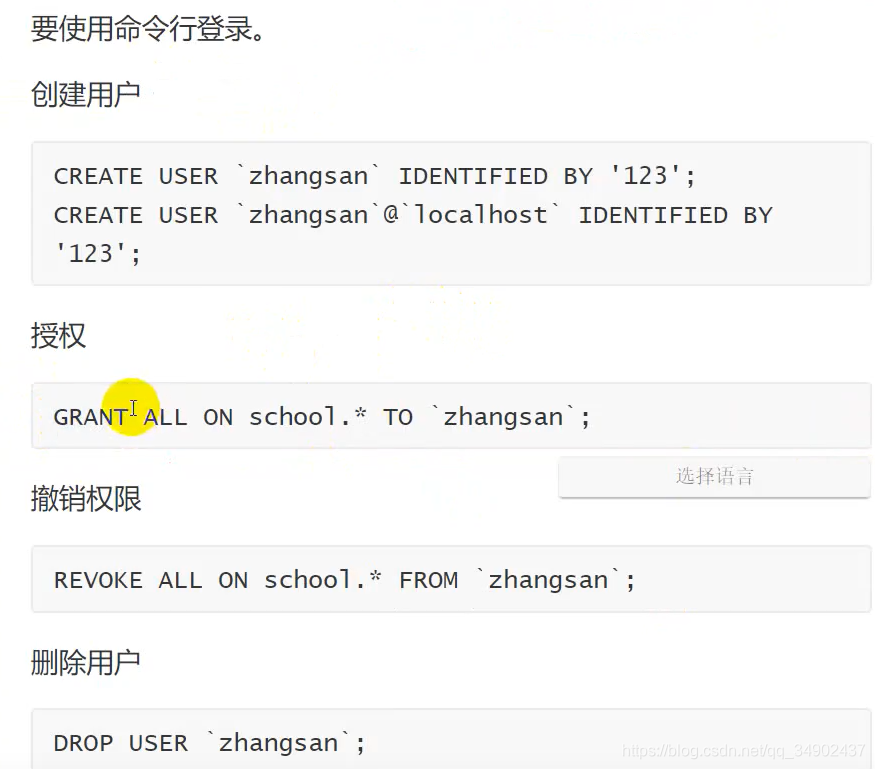
note:
- 授权是一个数据库给另一个数据库授权,图中是 school 数据库的所有权限给 zhangsan 数据库
8. 视图(未完)
9. 高级用法
9.1 表操作
9.1.1 被查询数据作为新的插入值
SELECT @var_name := income.`totalIncome` FROM income WHERE `curdate` = DATE_SUB(CURDATE(),INTERVAL 1 DAY);
INSERT INTO income(totalIncome,`curdate`,curIncome,parkOneIncome,parkTwoIncome,
parkThreeIncome,normalIncome,vipIncome)VALUES(@var_name,
CURDATE(),0,0,0,0,0,0);
注意
SQL 语法的定义
1、{}大括号括起来并且中间有个|管道符的代表 n 选一,必须输入
2、[]中括号里括起来的表示可有可无
3、小写字母代表变量,将来可以替换
4、大写字母代表关键字,必须输入
5、一般有 sepcification 后缀的表示这是一个规范,后边还会有详细的介绍
6、 |管道符连接的信息没有用{}大括号括起来代表可以有其中一个也可以同时都有