我做这个小项目做了两天了,中间也是遇到各种问题。通过做这次的小项目,我慢慢开始转变成面向对象编程的方式。对函数式编程越来越上手。对于文本的字符处理,自己通过研究写了一个函数来进行处理(本来是打算使用递归的方式处理,后来证实比较困难。)因为,明天是要开始上课了。所以,项目只能暂时做到这里。唯一美中不足的地方在于没有采用与前端的交互,即没有引入Flask框架,我对Flask了解的不是很多导致没有做完整。我等自学完Flask后,应该可以做出一个完整项目。到时候,再跟大家分享一个更加完整项目。因为,最终的目标是要动态交互,还需要引入数据库跟前端配合。
话不多说,先上代码,如下图:
from selenium import webdriver#从selenium库导入浏览器驱动
from pyecharts.charts import *#调用pyecharts库中的所有图形
from pyecharts import options as opts#导入pyecharts中所有的配置项
import jieba#引入jieba库
import random#导入随机库,使时间随机
import time#导入时间库
import re
import os#导入系统模块
options = webdriver.ChromeOptions()#创建配置对象
options.add_argument('--headless')#添加参数无头模式
options.add_argument('--disable-gpu')#添加参数关闭gpu
driver = webdriver.Chrome(options=options)#使用chrome作为爬虫测试用的浏览器,没有引入配置。因为,要展示爬取效果。
class BaiDu_News:#定义BaiDu_News的类,百度新闻爬虫
def __init__(self):#定义一个初始化函数
self.data = []#定义一个存储处理后数据的空列表。
self.cut_data = []#定义一个空列表用于存储分词后得到的列表
self.dt = {
}#定义一个空字典用于统计词频
def Request(self,url):#定义一个请求函数,方便多次调用
driver.get(url)#发出get请求
driver.implicitly_wait(random.randint(3,5))#隐式等待,随机时间3-5秒
def Spyder(self):#定义一个爬虫函数
url = 'https://news.baidu.com/'#设置百度新闻的url地址
BaiDu_News.Request(self,url)#调用函数
hot_news = driver.find_element_by_xpath('//*[@id="left-col-wrapper"]').text#获取热点新闻
print("Hot_news")
print(hot_news)
BaiDu_News.save_file(hot_news)
print()#换行输出
def city(num):#定义一个有参数的函数city(),函数嵌套,嵌套在Spyder函数中。
try:#加入异常处理,增加程序的健壮性
print("正在抓取数据,请稍候...")#爬虫显示的效果
change = driver.find_element_by_xpath('//*[@id="change-city"]')#获取改变省市的按钮
change.click()#模拟点击打开改变页面
time.sleep(random.randint(2,3))#等待页面响应,避免速度太快获取到未更新的数据
other_city = driver.find_element_by_xpath('//*[@id="city_view"]/div[1]/a[{}]'.format(num))#选择城市
other_city.click()#模拟点击改变城市
time.sleep(random.randint(2,3))#等待响应
Title = driver.find_element_by_xpath('//*[@id="city_name"]').text#获取城市的标题
BaiDu_News.save_file(Title)#调用函数,保存城市标题到定义的存储函数中
print(Title)
City_news = driver.find_element_by_xpath('//*[@id="local_news"]/div[2]').text#获取城市的新闻
BaiDu_News.save_file(City_news)#调用函数,保存城市对应的新闻内容
print(City_news)
print()
except:#出现异常,执行:
print("出现异常!!")
def city2():#定义一个无参数的函数city2()
number = 4#设定初始化number值为4
while True:
number += 1#每次number自增1
if number == 33:#当number自增到33时退出爬取!
break
try:
print("正在抓取数据,请稍候...")
change = driver.find_element_by_xpath('//*[@id="change-city"]')#获取改变按钮
change.click()#模拟点击,回到所有省市页面
time.sleep(random.randint(2, 3))
province = driver.find_element_by_xpath('//*[@id="city_view"]/div[1]/a[{}]'.format(number))#选择省
province.click()#模拟点击,改变省
time.sleep(random.randint(2, 3))
for i in range(1, 30):
try:
city_name = driver.find_element_by_xpath('//*[@id="city_view"]/div[1]/a[{}]'.format(i))#选择市
city_name.click()#模拟人的鼠标左击
time.sleep(random.randint(2, 3))
Title = driver.find_element_by_xpath('//*[@id="city_name"]').text#获取城市的标题
BaiDu_News.save_file(Title)
print(Title)
City_news = driver.find_element_by_xpath('//*[@id="local_news"]/div[2]').text#获取城市的新闻
BaiDu_News.save_file(City_news)
print(City_news)
print()
change = driver.find_element_by_xpath('//*[@id="change-city"]')#获取改变按钮
change.click()#点击改变城市
time.sleep(random.randint(2, 3))#给页面响应时间,不设置导致速度太快,会爬取到未更新的省市数据。
province = driver.find_element_by_xpath('//*[@id="city_view"]/div[1]/a[{}]'.format(number))#重新选择省
province.click()#模拟点击,重新改变
time.sleep(random.randint(2, 3))#休眠时间设置为随机的2,3秒钟
except:#如果出现异常,执行:
print("超出范围!!\n准备爬取下一个省市!!")
Return = driver.find_element_by_xpath('//*[@id="btn_back"]')#获取返回的xpath路径
Return.click()#点击返回到当前页面,方便下一次循环的继续。
time.sleep(random.randint(2, 3))
break#跳出当前for循环,开始下一次循环。
finally:#无论是否出现异常,都执行finally语句
print("爬取完毕!!")
print()
time.sleep(random.randint(1,2))
except:
print("继续爬取!!")
for i in range(1,5):#前四个直辖市,采用单独定义的函数爬取,采用循环的方式调用。
city(i)#每次i变化都会自动会对函数调用。
city2()#调用函数,从第五个省市开始,采用第二种函数爬取。
def save_file(content):#定义一个存储函数
if os.path.exists('F:/Baidu_news.txt'):#如果路径中存在txt文件,则执行追加操作。
with open(r'F:/Baidu_new.txt', 'a+', encoding='utf-8') as f:#打开文件
f.write(content+"\n")#追加后换行,避免挤在同一行。
else:
os.mkdir('F:/Baidu_news.txt')#如果路径中不存在txt文件,则创建一个txt。
with open(r'F:/Baidu_new.txt','a+',encoding='utf-8') as f:
f.write(content+"\n")#追加后换行,避免挤在同一行。
def Word_Cut(self):#定义一个函数用于分词
with open(r"F:/Baidu_new.txt","r+",encoding="utf-8") as f:
lines = f.readlines()
for l in lines:
line = l.strip()
#print(line)
result = BaiDu_News.String_process(self,line)#将函数String_process处理结果的返回值String存储到变量result中
self.data.append(result)#将每一条处理后的结果result都加入到列表中,方便统一处理。
for d in self.data:
d = BaiDu_News.String_process(self,d)
# if ' ' in d:
# d = d.replace(' ',"")
cut = jieba.lcut(d)#精准模式分词
self.cut_data.append(cut)#将分词结果的列表加入到self.cut_data中
#print(self.cut_data)
def Word_All_Count(self):#定义函数统计所有词语的数量,并计算每个词语出现在文本中的概率
for element in self.cut_data:#从列表中取出每一个切分的列表。
for e in element:#从每一个切分的列表中分别找出每一个词语。
if len(e) == 1:#除去一个字的词语
continue
elif e not in self.dt.keys():#如果词语e第一次出现
self.dt[e] = 1#则赋予初始值1并加入到字典中。
elif e in self.dt.keys():#如果词语e再次出现则累加1进行词语计数。
self.dt[e] = self.dt[e] + 1
#print(self.dt)
Length = 0#定义整个文本的初始长度为0
self.plv = [] # 定义一个空列表用于存储频率
self.plv_dt = {
}
for l in self.data:#获取每个处理后的字符串长度
Length += len(l)#进行累加,得到整个文本的长度,用于计算频率
for word in self.dt:
#print(word+": 文本中出现的次数:"+str(self.dt[word]))#统计词语出现的次数
#print("文本中出现的频率是"+str(round(self.dt[word]/Length,10)))#统计词语的频率,保留10位小数
self.plv.append(round(self.dt[word]/Length,10))
self.plv_dt[word] = round(self.dt[word]/Length,10)
def Ten_Words_Count(self):#定义一个函数用于展示文本中前十个频率最高的词语
self.ten_dt = {
}#定义一个存储前10个数和概率的字典。
self.plv = sorted(self.plv,reverse=True)#从小到大进行排序并进行翻转。
#print(self.plv)
self.plv = self.plv[0:10]#将列表self.plv中前十个元素切片并取代self.plv
#print(self.plv)
print("文本中出现频率最高的前十个词语:")
for element in self.plv_dt:
if self.plv_dt[element] in self.plv:
self.ten_dt[element] = self.plv_dt[element]
print(element)#输出文本中前十个频率最高的词语
else:
continue
def String_process(self,string):#定义一个处理文本字符的函数。
varchar = '‘’“:#,!*!*【】,、&#|?『【|,&;』;?:"▏┃·./丨②~”(」)“(「)→@“》!..." "|—‖《?…_'#字符集合
ls = []
for s in string:
ls.append(s)
for element in ls:
if element in varchar:#判断是否在字符集合中
ls.remove(element)#在集合中就删除
String = ''
for l in ls:
String = String + l
return String#返回处理完成的字符串
#print(String)
def Data_Show(self):#定义可视化函数,使用pyecharts的Bar()条形图进行可视化
x_ls = []
y_ls = []
for d in self.ten_dt:#从字典中取出键(词语)加入列表
x_ls.append(d)
y_ls.append(self.ten_dt[d])#取出字典的值(词语的频率)加入列表
B = (
Bar()
.add_xaxis(x_ls)#加入x轴的数据,list类型
.add_yaxis('词频',y_ls)#加入y轴的标题和数据,也是list类型
.set_global_opts(title_opts=opts.TitleOpts(title="百度新闻词频统计图"))#设置全局配置,图形的标题。
.render('F:/Baidu_news.html')#图形存放的位置
)
if __name__ == '__main__':#定义一个主函数,程序入口。
BD = BaiDu_News()#实例化对象BD
BD.Spyder()#BD对象调用Spyder函数(方法)
BD.Word_Cut()
BD.Word_All_Count()
BD.Ten_Words_Count()
BD.Data_Show()
爬虫运行截图:
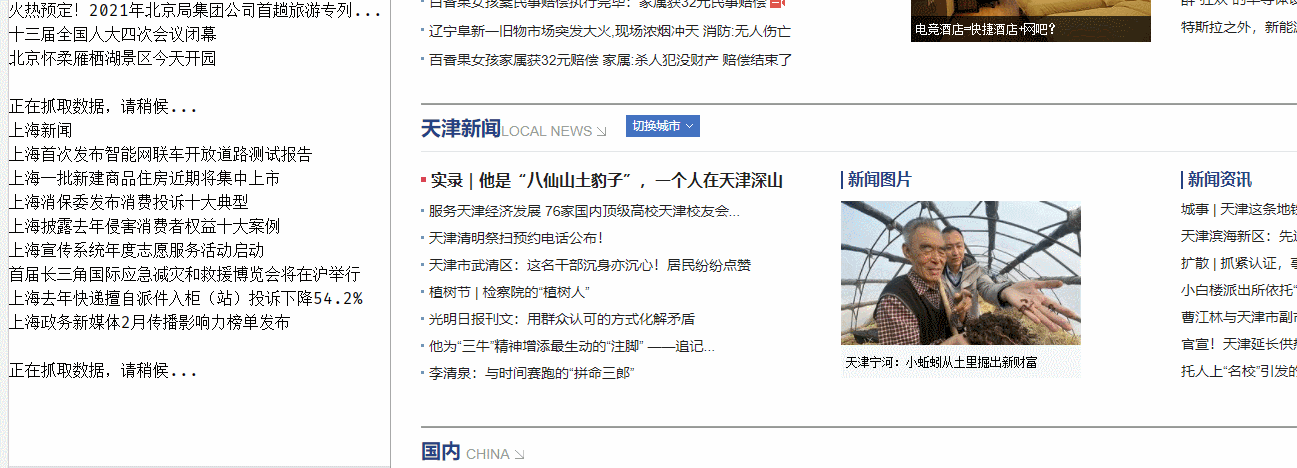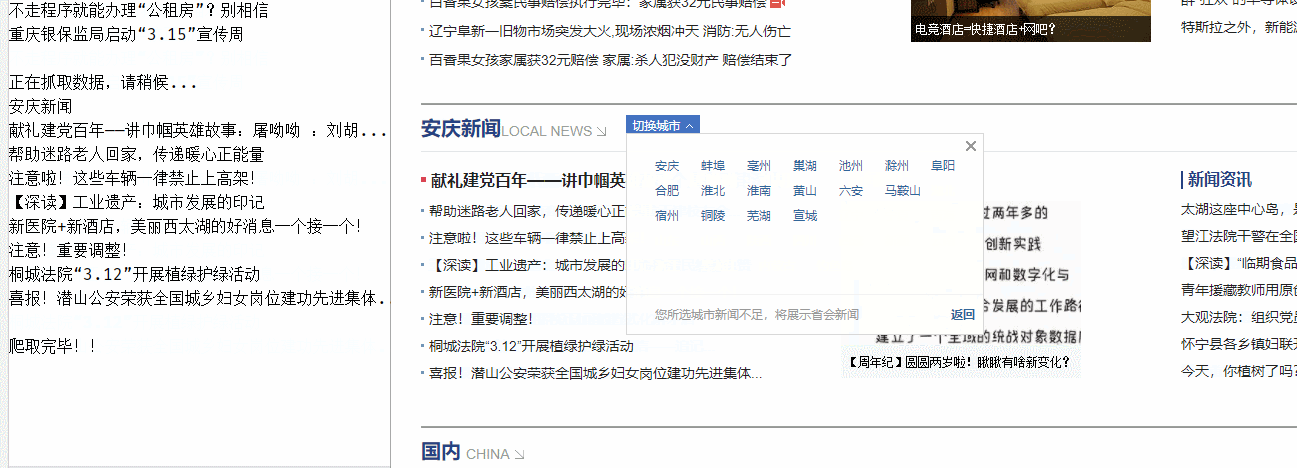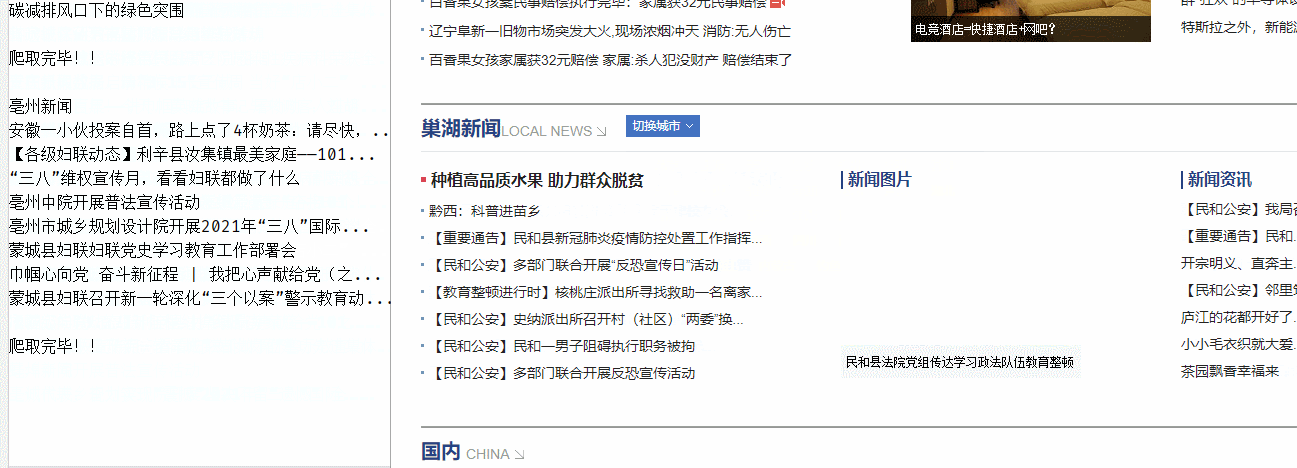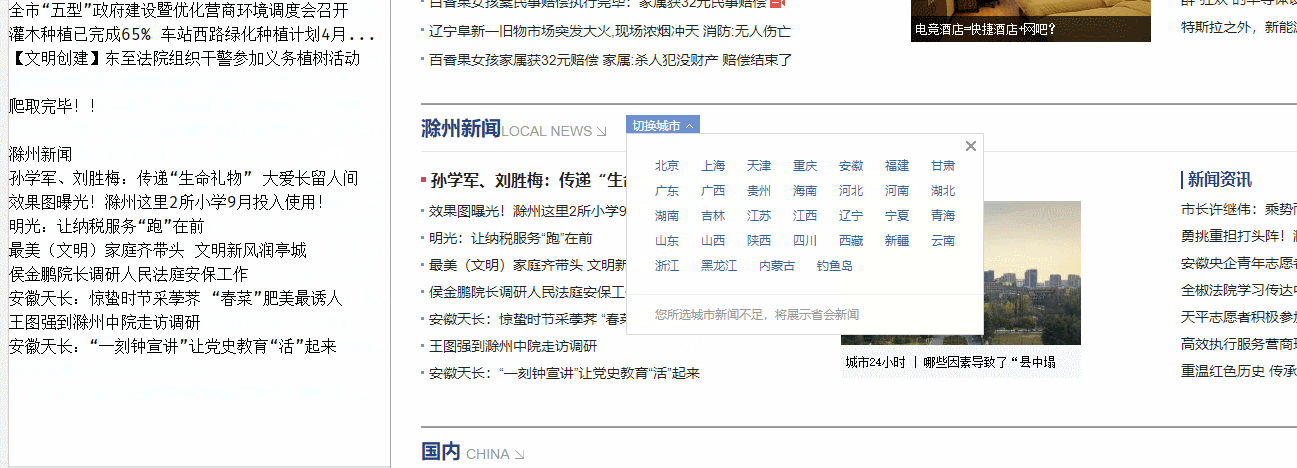
爬取到的各省市新闻的原始文本,如下图:

文本通过我自定义的函数进行预处理后得到的结果,如下图:

对全部词语进行统计,如下图:

输出每个词语的次数和对应的词频(保留10位小数),如下图:

对文中出现频率最高前10个词语的统计,如下图:

最后,进行词频可视化,如下图:

去F盘打开文件,如下图:

关于代码的解释,我都写在注释中了。通过做本次不完整的项目,明白了异常处理的用处。设计了自动化爬虫,当我爬虫失败的时候,我设置的异常处理机制可以让爬虫继续下去。包括爬取的范围也不需要去管,自定义一个大的范围,超出范围就证明爬完了。这时,异常处理会让爬虫继续爬取数据而不退出!还有对文本各种奇葩字符处理的时候,我定义了一个函数来实现对文本字符的处理,没有使用re库。因为,我试过了不太好使。同时也知道函数(方法)可以赋值给一个对象,在看re的sub参数明白的。我试着把函数赋值给变量,其实就是将函数的返回值赋值给变量。总之,通过这次自己做的历时两天小项目,虽然不够完整(开头指明了原因),但是收获足够多。在做这个项目的过程中也遇到各种各样的问题,但是都想尽办法去解决了。大家在看代码不明白的地方可以与我交流探讨,欢迎大家前来指正我代码中不足之处,也可以提出改进意见。
最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。