所谓分布式对象缓存是指对对象缓存以一个分布式集群的方式对外提供服务,多个应用系统使用同一个分布式对象缓存提供的缓存服务。这里的缓存服务器是由多台服务器组成。这些服务器共同构成了一个集群对外提供服务,所以使用分布式对象缓存一个重要的问题就是,数据进行读写操作的时候,如何找到正确的缓存服务器进行读写操作。如果第一次写入数据的时候写入的是A服务器,但是数据进行缓存读取操作的时候访问的是B服务器,就不能够正确的查找到数据,缓存也就没有效果。
那么如何才能找到正确的缓存服务器呢?
当需要进行分布式缓存访问的时候,依然是以Key、value这样的数据结构进行访问的。比如Memcached提供的一个客户端API程序进行访问,客户端API程序会使用自己的路由算法进行路由选择,选择其中的某一台服务器,找到这台服务器的IP地址和端口以后,通过通讯模块和响应的服务器进行通信。
因为进行路由选择的时候,就是使用缓存对象的key进行计算,下次使用相同的key,使用相同路由算法进行计算,算出来的服务器依然还是前面计算出来这个服务器,所以通过这种方法可以访问到正确的服务器进行数据读写。服务器越多,提供的缓存空间就越大,实现的缓存效果也就越好。
那么,路由算法又是如何进行服务器路由选择的呢?
主要算法是哈希表的路由算法,也就是取模算法。
例如,我们这里缓存服务器集群有3台服务器,key的哈希值对3取模得到的余数一定在0、1、2三个数据之间,那么每一个数字都对应一台服务器,根据这个数字查询对应的服务器IP地址就可以了。这种取模算法进行路由计算非常简单,但是这个算法有一个问题,就是当服务器扩容个到时候,比如当前的缓存服务器集群有3台服务器,再添加1台的时候,这个时候就会由对3取模变为对4取模,导致的后果就是对3取模的时候写入的数据,对4取模的时候可能就查不到了。如果缓存查不到了之后,就会去数据库里查找。这样就会出现类似缓存雪崩现象。
对于这个路由算法,也可以使用一致性哈希算法。
一致性哈希算法与取余哈希算法不同,一致性哈希是有一个一致性哈希环构成。一致性哈希环的大小是0-2的32次方减1。这个取值范围的0和最后一个值2的32次方减1收尾相连,就构成了一个一致性哈希环。
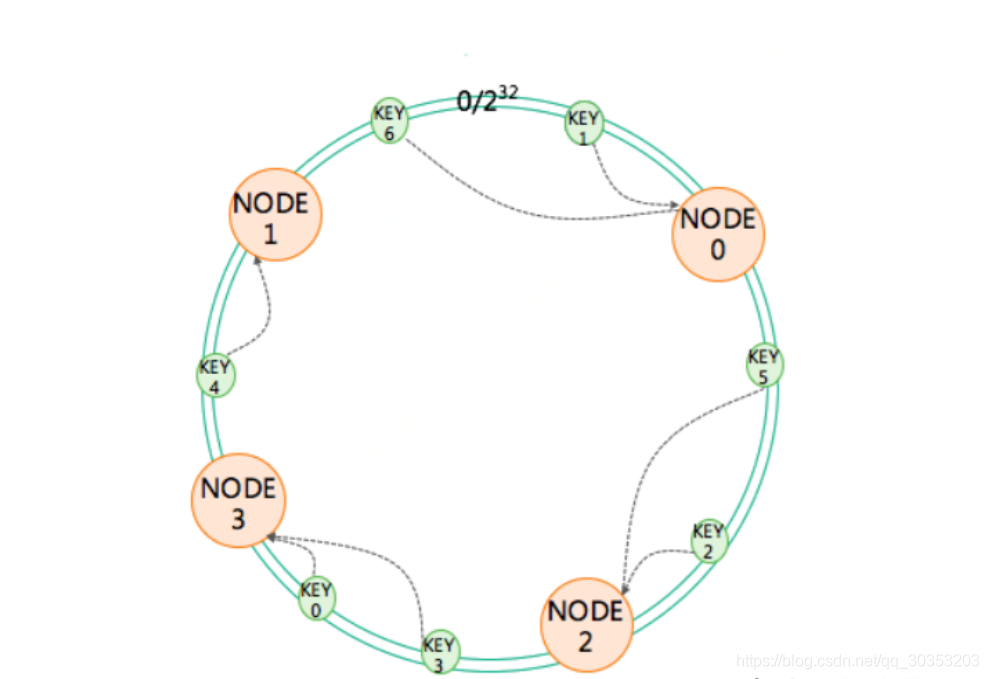
分布式缓存的路由算法是如何实现的?
对每个服务器的节点取模,求它的哈希值并把这个哈希值放在环上,所有的服务器都取哈希值放到环上,每一次进行服务器查找路由计算的时候,把key也取它的哈希值,取到的哈希值以后把key放到环上,顺时针查找距离它最近的服务器的节点是哪一个。通过这种方式可以实现,key不变的情况下找到的总是相同的服务器,这种一致性哈希算法除了可以实现像余数哈希一样的路由效果,对服务器的扩容效果比较好。
在一致性哈希环上进行服务器扩容的时候,新增加一个节点不需要改动前面取模算法的除数,导致最后的取值结果全部混乱,它只需要在哈希环里根据新的服务器节点的名称计算它的哈希值,把哈希值放到这个环上就可以。放到环上后,不会影响原先节点的哈希值,也不会影响到原先服务器在哈希环上的分布,只会影响到离它最近的服务器。这样的话对缓存的影响也比较小,它值会影响缓存里的一小段。对于这个一小段的数据,可以从数据库中读取,而数据库的压力只要在它的负载能力之内,也不会崩溃,系统就可以正常运行。所以通过一致性哈希算法可以实现缓存服务器的顺利伸缩扩容。
但是一致性哈希算法也有缺点,哈希值是一个随机值,把随机值放到一个环上,可能是不均衡的,也就是说某两个服务器可能距离很近,而和其他的服务器距离很远,这个时候就会导致有些服务器的负载压力特别大,有些服务器的负载压力特别小。
对于这个问题,改进办法就是使用虚拟节点,我们把一个服务器节点放入到一致性哈希环上的时候,并不是把真实的服务器的哈希值放到环上,而是将一个服务器虚拟成若干个虚拟节点,把这些虚拟节点的hash值放到环上。实践中一把一个服务器节点虚拟成200个虚拟节点,然后把200个虚拟节点放到环上。key依然是顺时针的查找距离它最近的虚拟节点,找到虚拟节点以后,根据映射关系找到真正的物理节点。