介绍
visdom是Facebook专门为PyTorch开发的一款可视化工具,其开源于2017年3月。Visdom十分轻量级,但却支持非常丰富的功能,能胜任大多数的科学运算可视化任务。
Visdom可以创造、组织和共享多种数据的可视化,包括数值、图像、文本,甚至是视频,其支持PyTorch、Torch及Numpy。用户可通过编程组织可视化空间,或通过用户接口为生动数据打造仪表板,检查实验结果或调试代码。
注意,其不支持Python的int和float类型,所以需要先转换为ndarray或tensor。
Visdom核心概念
Visdom中有两个重要概念:
env:环境。不同环境的可视化结果相互隔离,互不影响,在使用时如果不指定env,默认使用main。不同用户、不同程序一般使用不同的env。
pane:窗格。窗格可用于可视化图像、数值或打印文本等,其可以拖动、缩放、保存和关闭。一个程序中可使用同一个env中的不同pane,每个pane可视化或记录某一信息。
使用时,先创建一个env,然后在env中创建pane。如下面的viz即创建的env对象,该env的名称为test2,之后通过viz的api可以在该test2的env中创建pane。如viz.text创建了一个pane即textwindow,其id随机产生。
viz=visdom.Visdom(env=u'test2')
textwindow=viz.text('Hello World!')
当然也可以手动给viz命名,通过win这个属性可以给pane命名,这样之后可以根据这个id对pane修改。
(没有主动命名id的话也可以将变量名当作id传给win,这样也能对上一个修改)
updatetextwindow = viz.text('Hello World! More text should be here')
viz.text('And here it is', win=updatetextwindow, append=True)
#设置了id的
viz.text("this pane has win id setted",win="new pane")
viz.text('new word',win="new pane",append=True)
结果:

visdom的操作
viz作为一个客户端对象,可以使用常见的画图函数,包括:
line:z类似Matlab中的plot操作,用于记录某些标量的变化,如损失、准确率等
image:可视化图片,可以是输入的图片,也可以是GAN生成的图片,还可以是卷积核的信息
text:用于记录日志等文字信息,支持html格式
histgram:可视化分布,主要是查看数据、参数的分布
scatter:绘制散点图
bar:绘制柱状图
pie:绘制饼状图
使用时直接viz.XXX(),然后传入参数即可。
更多操作可参考visdom的github主页
这里主要介绍深度学习中常见的line、image和text操作.
上述操作的参数一般不同,但有两个参数是绝大多数操作都具备的:
win:用于指定pane的名字,如果不指定,visdom将自动分配一个新的pane。如果两次操作指定的win名字一样,新的操作将覆盖当前pane的内容,因此建议每次操作都重新指定win。
opts:选项,接收一个字典,常见的option包括title、xlabel、ylabel、width等,主要用于设置pane的显示格式。
之前提到过,每次操作都会覆盖之前的数值,但往往我们在训练网络的过程中需不断更新数值,如损失值等,这时就需要指定参数update='append’来避免覆盖之前的数值。而除了使用update参数以外,还可以使用vis.updateTrace方法来更新图,但updateTrace不仅能在指定pane上新增一个和已有数据相互独立的Trace,还能像update='append’那样在同一条trace上追加数据。
viz.line的例子
这里的例子里一个pane里面画两条线 L 1 = 2 x + 1 L_1=2x+1 L1=2x+1和 L 2 = 2 x 2 − x L_2=2x^2-x L2=2x2−x,X和Y的shape要一样,都是N2,每条线N个点,一个点对应(X,Y),所以两条线就是N2。
viz=visdom.Visdom(env="demo")
L=np.array([[2*x+1,2*x**2-x] for x in np.arange(1,10)])
X=np.array([[x,x] for x in np.arange(1,10)])
viz.line(X=X,Y=L,win="lossdemo",opts=dict(
xlabel="Iteration",
ylabel="Loss",
title="xxmodel",
legend=["Loss1","Loss2"]
))
结果:
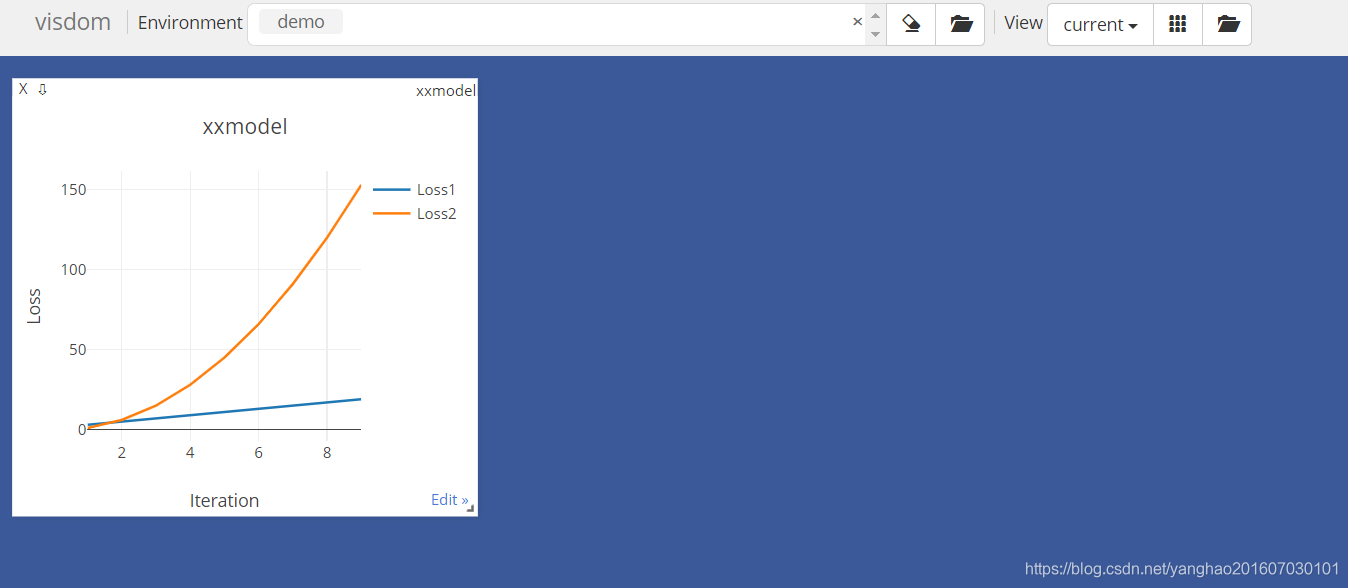
visdom在训练中可视化loss
这里给了一个demo展示如何在训练的过程中动态的展示loss 的变化,考虑到目标检测中的loss通常由两个组成(位置和分类损失),这里的给的demo是同时展示位置损失、分类损失和总损失3个变化,也就是3条线的案例,并且可以按照epoch和iteration变化呈现(分别在两个不同pane)。案例中将创建pane 的代码封装出来了,然后通过命令行的方式控制是否可视化。
这里给的demo中训练部分的代码是不完全的,如果需要的话后面再补充完全。*
创建pane和更新pane的函数
#create the vis,with initialized 0
def create_vis_plot(_xlabel, _ylabel, _title, _legend):
return viz.line(
X=torch.zeros((1,)).cpu(),
Y=torch.zeros((1, 3)).cpu(),
opts=dict(
xlabel=_xlabel,
ylabel=_ylabel,
title=_title,
legend=_legend
)
)
#update visdom plot
def update_vis_plot(iteration, loc, conf, window1, window2, update_type,
epoch_size=1):
viz.line(
X=torch.ones((1, 3)).cpu() * iteration,
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu() / epoch_size,
win=window1,
update=update_type
)
# initialize epoch plot on first iteration
if iteration == 0:
viz.line(
X=torch.zeros((1, 3)).cpu(),
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu(),
win=window2,
update=True
)
这里简化了训练的一些具体代码,只是大致写下流程
import argparse
# 解析
def str2bool(v):
return v.lower() in ("yes", "true", "t", "1")
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
parser.parser.add_argument('--visdom', default=False, type=str2bool,
help='Use visdom for loss visualization')
#这里还能输入其它可解析的参数
args = parser.parse_args()
# initialize
if args.visdom:
import visdom
viz = visdom.Visdom()
vis_title = 'SSD.PyTorch on ' + dataset.name
vis_legend = ['Loc Loss', 'Conf Loss', 'Total Loss']
iter_plot = create_vis_plot('Iteration', 'Loss', vis_title, vis_legend)
epoch_plot = create_vis_plot('Epoch', 'Loss', vis_title, vis_legend)
#初始化这些dataset,model,optimizer,lr_scheduler,loss_function,dataloader,device,
#epoch_size=len(dataset) // args.batch_size
model.train()
for epoch in total_epoch:
loss_conf=0
loss_loc=0
for iteration, batch in enumerate(dataloader):
....
if args.visdom and iteration != 0 and (iteration % epoch_size == 0):
update_vis_plot(epoch, loc_loss, conf_loss, epoch_plot, None,
'append', epoch_size)
images,targets=batch[0],batch[1]
with torch.no_grad():
#toTensor,and to(device)
optimizer.zero_grad()
output=model(output)
lossc,lossl=loss_function(output,target)
loss = loss_l + loss_c
loss.backword()
optimizer.step()
loc_loss += loss_l.data[0]
conf_loss += loss_c.data[0]
if args.visdom:
update_vis_plot(iteration, loss_l.data[0], loss_c.data[0],
iter_plot, epoch_plot, 'append')
torch.save(model.state_dict(),"path/to/save.pth")
写在最后:
关于命令行解析,可以参考Python官方源码:argparse — 命令行选项、参数和子命令解析器,默认添加的arg参数类型为str,但是如果需要其它类型如int就需要更改type,如果要改为bool类型则需要自己写个解析函数传到type中,如本例那样,因为它本身自带的转换bool的机制是空字符转换为False,其它为True。
关于visdom中的其它操作组,如散点图等,可以去看看其官网案例。