1、博客批量导出为md
import requests
import parsel
import tomd
import os
import re
#对一篇文章的爬取
def spider_one_csdn(title_url): # 目标文章的链接
head={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52"
}
html=requests.get(url=title_url,headers=head).text
page=parsel.Selector(html)
#创建解释器
title=page.css(".title-article::text").get()
content=page.css("article").get()
content=re.sub("<a.*?a>","",content)
content = re.sub("<br>", "", content)
#过滤a标签和br标签
text=tomd.Tomd(content).markdown
#转换为markdown 文件
path = os.getcwd() # 获取当前的目录路径
file_name = "./download"
final_road = path + file_name
try:
os.mkdir(final_road)
print('创建成功!')
except:
# print('目录已经存在或异常')
pass
try:
with open(final_road+r"./"+title+".md",mode="w",encoding="utf-8") as f:
f.write('---\n' + "title: " + title + '\n---\n')
f.write(text)
except:
print(title)
def get_article_link(user):
page=1
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52",
"Referer": "https://blog.csdn.net/tansty_zh"
}
while True:
link = "https://blog.csdn.net/{}/article/list/{}".format(user, page)
print("现在爬取第", page, "页")
html = requests.get(url=link, headers=head).text
cel = parsel.Selector(html)
name_link = cel.css(".article-list h4 a::attr(href) ").getall()
if not name_link:
break
#没有文章就退出
for name in name_link:
spider_one_csdn(name)
page+=1
def main():
name="weixin_44704985" #修改成你的csdn名称
get_article_link(name)
if __name__ == '__main__':
main()
2、文件夹整理
分类整理Markdown文件,如图为我的文件夹结构,文件夹上层为download

3、批量生成符合hexo分类和命名格式的文件
生成格式如下
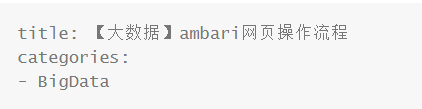
import os
def rename_all(dir):
for home, dirs, files in os.walk(dir):
for d in dirs:
for filename in os.listdir(os.path.join(home, d)):
fullname = os.path.join(home, d, filename)
rename_one(filename,fullname)
def rename_one(filename,fullname):
with open(fullname,mode="r",encoding="utf-8") as f:
file_name = filename.split(".md")[0]
hexo_categories = fullname.split("/")[2].split("\\")[0]
hexo_title = 'title: ' + file_name + '\n'
hexo_categories = 'categories:\n' + '- ' + hexo_categories + '\n'
hexo_str = '---\n' + hexo_title + hexo_categories + '\n---'
markdown = f.read()
text = markdown.split("---\n")[-1]
with open(fullname,mode="w",encoding="utf-8") as f:
f.write(hexo_str)
f.write(text)
f.close()
if __name__ == "__main__":
path = "./download/"
rename_all(path)
4、文件转移到hexo根目录下的文件夹“source_posts\”中
效果如下
