问题:
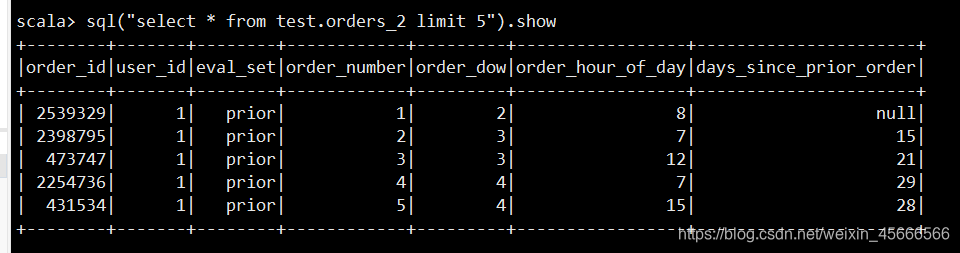
Hive查询:
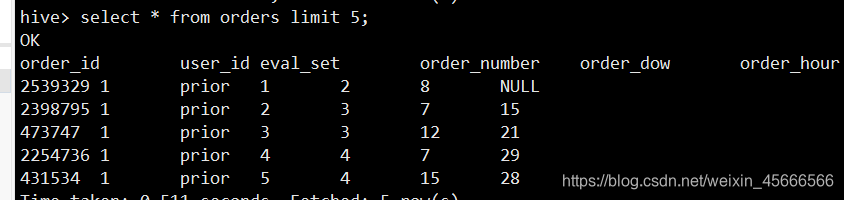
Spark SQL 查询
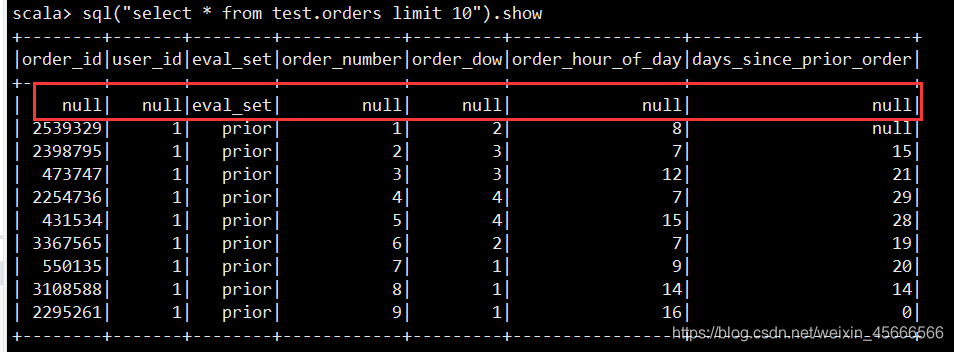
- 同一张表,结果查询效果不一样
- spark sql查询的表第一行即是源数据的表头,至于为什么有的是空值,是因为其所在字段都设置成int了,不相符合。
原因:
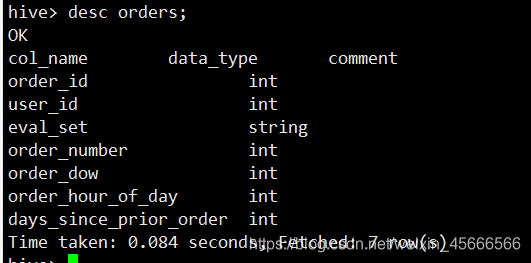
1、Hive表中不出现表头即脏数据的原因是我在创建表的时候跳过了文件的第一行
create table trains(
order_id int
,product_id int
,add_to_cart_order int
,reordered int
)
row format delimited fields terminated by ','
lines terminated by '\n'
--跳过文件行第一1行
tblproperties("skip.header.line.count"="1");
2、
-
Hive在创建表的时候可以通过增加:tblproperties(“skip.header.line.count”=“1”) 语句来忽略第一行。
-
但Hive中设置的忽略表头在Spark中不生效!这就是原因
解决
解决方法1:
\quad \quad Hive表在创建表时,加载csv数据之前通过shell命令就清理一下脏数据。
- 在load数据之前,将原数据的第一行去掉,其余数据定向输出到一个新文件里,然后我们用新文件的数据加载表
sed '1d' tmp.csv > tmp_res.csv
解决方法2:
\quad \quad 在原始表的基础上,再建立一个备份表,基于这个备份表,通过Spark Sql进行读写操作。
create table if not exists orders_2
row format delimited fields terminated by ","
as
select * from orders;
验证:
Hive查询:
扫描二维码关注公众号,回复:
12803727 查看本文章

select * from orders_2 limit 5;

Spark SQL 查询:
import spark.sql
sql("select * from test.orders_2 limit 10").show