正则表达式
1. 前言
最好用的验证工具,没有之一
https://regex101.com/
在线验证工具
官方最新的文档
https://docs.python.org/zh-cn/3/library/re.html?highlight=re#module-re
第一步:定义变量
第二步:引入正则模块
第三步:定义筛选内容
如:
content ='''沐足城,消费98块钱
沐足城,消费168块钱
沐足城,消费298块钱
沐足城,消费998块钱'''
import re
p = re.compile(r'')
for dalao in p.findall(content):
print(dalao)
注意
# 这里面的表示我的第一行开始就是数据
content ='''沐足城,消费98块钱
'''
# 这里表示第二行开始才是数据
content ='''
沐足城,消费98块钱
'''
2. 特殊字符
metacharacters元字符
.*+?\[]^${
}|()
实用技巧
因为有这种特殊符号,所以
re.compile()里面要添加r
re.compile(r'')
表示不要进行python语法中的字符串转译
那么我们为什么要循环?
因为执行re.compile()得到的是一个类,所以我们才可以对它进行加工(使用方法)
p = re.compile(r'')
print(type(p))
得到的是<class 're.Patterr'> 是一个类
.findall为找到所有符合条件的列表文本
for dalao in p.findall(content):
print(type(dalao))
得到的是<class 'str'> 字符串
3.元字符讲解
- 【.】
.
点-匹配所有字符
表示要匹配任何单个字符(一个字符,不能为0)【除了换行符之外】
【.块】
所有以块结束,并且包括前面的一个字符的词语
例
p = re.compile(r'.块')
8块
8块
8块
8块
- 【*】
*
表示匹配前面的子表达式任意次数,包括0次
缺省模式是按行来匹配的,(遇到换行符号就结束)
例
p = re.compile(r',.*')
,消费98块钱
,消费168块钱
,消费298块钱
,消费998块钱
【,】以逗号开头
【.】表示任意字符
【*】任意次数
【.*】任意字符可以出现任意次数
例
p = re.compile(r'9*')
9
9
99
例
p = re.compile(r'费9*')
费9
费
费
费99
这里是以【费】开头,任意次,可以是0次
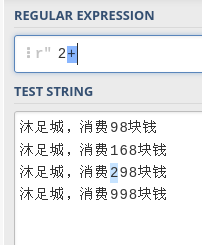
- 【+】
+
+号表示匹配前面的子表达式一次或者多次
+号 重复匹配多次,不包括0次
- {}
{}
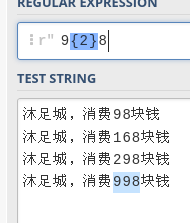
{}花括号-匹配指定次数
9{2}8 其中9 出现2次 以8结尾
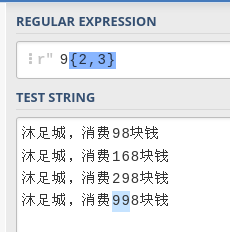
9{2,3} 其中9 出现2至3次
- 【\】
\
\ 反斜杠 对元字符的转义
添加在需要转义的元字符前面
\. 表示包含【.】 这个符号,【.】不再是任意字符的意思
\d 匹配0-9之间任意一个数字字符
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式[^0-9] 包括换行符
\s 匹配任意一个空白字符,[空格键,tab,换行],等价于表达式[\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式[^\t\n\r\f\v]
\w 匹配任意一个文字字符,[大写字母,小写字母,数字,下划线],等价于表达式[a-zA-Z0-9]
\W 匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9]
如
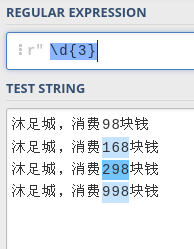
\d 反斜杠加d表示数字
\d{3} 数字出现3次
- ?
?
第一种
?号 可以表示匹配前面的子字符0至1次

第二种
?号 取消贪婪模式 尽量分得更多的数组
p = re.compile(r'<.*?>')
内容为<html><head></head></html>
右侧会展示历表内有4个元素

贪婪模式下
p = re.compile(r'<.*>')
右侧会展示历表内有1个元素

- [ ]
[]
[ ] 方括号 里面的元素只表示一位,里面填写的为定义条件
[2-5]==[2345] 里面的杠表示范围
[25]==2或5
[a-c]==[abc]
[ac]==a或c
[A-C]==[ABC]
[AC]==A或C
[.]==在这里只表示点,不再是任意字符
[^]==表示非
[^\d]==表示非数字
[^abc]==非abc三个字符
如


- ^
^
向上箭头表示文本开头
p = re.compile(r'^\d+')
案例在下文中
- $
$
$表示文本末尾
p = re.compile(r'\d+$')
案例在下文中
- ()
()
圆括号,组选择
筛选符合条件中,只取括号里面的内容
import re
p = re.compile(r'^(.*)剑',re.MULTILINE)
for dalao in p.findall(content):
print(dalao)
我们需要的是不要剑这个字的

小案例
多个()组选择
content = '''小明,是个学生,手机号码是18898836599
赵昊,是个大佬,手机号码是18898836588
王猛,是个技工,手机号码是18898836577'''
import re
p = re.compile(r'(.{2,3}),.*个(.*),.*(\d{11})',re.MULTILINE)
for dalao in p.findall(content):
print(dalao)
提取里面的姓名,职业,点电话号码
 在我们的自己编辑器里面则会生成
在我们的自己编辑器里面则会生成
('小明','学生','18898836599')
('赵昊','大佬','18898836588')
('王猛猛','技工','18898836577')
在工具网站里面
Full match 表示是匹配到符合条件的记录
Group 表示是筛选过后的记录
第二个参数
re.ASCII简写re.A
p = re.compile(r'\w{2,4}',re.A)
p = re.compile(r'\w{2,4}'.re.ASCII)
让 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII,而不是Unicode。这只对Unicode样式有效,会被byte样式忽略。
这里是点击了选项ASCII之后得到的结果,(点击小灰旗)
右侧有4个元素


re.MULTILINE简写re.M
p = re.compile(r'^\d+',re.M)
p = re.compile(r'^\d+',re.MULTILINE)
设置以后,
样式字符 ‘^’ 匹配字符串的开始,和每一行的开始(换行符后面紧跟的符号);
样式字符 ‘ ′ 匹 配 字 符 串 尾 , 和 每 一 行 的 结 尾 ( 换 行 符 前 面 那 个 符 号 ) 。 默 认 情 况 下 , ’ ’ 匹 配 字 符 串 头 , ′ ' 匹配字符串尾,和每一行的结尾(换行符前面那个符号)。 默认情况下,’^’ 匹配字符串头,' ′匹配字符串尾,和每一行的结尾(换行符前面那个符号)。默认情况下,’’匹配字符串头,′’ 匹配字符串尾。对应内联标记 (?m) 。
p = re.compile(r'^\d+',re.MULTILINE)
文本每行开头

p = re.compile(r'^\d+')
仅文本开头

p = re.compile(r'\d+$',re.MULTILINE)
每行末尾

p = re.compile(r'\d+$')
仅文本末尾

正则里面的分割方法
split
content ='''小明, 赵昊; 王猛。 张三''''
import re
contentlist = re.split(r'[,;。\s]\s*',content)
for dalao in p.findall(contentlist):
print(dalao)
解释
[,;。\s]==出现,号或;号或。号或空白符
\s* == 出现空白符号任意次0至N次
# 创建一个新变量 = 正则切割(条件,切割目标参数)
contentlist = re.split(r'[,;。\s]\s*',content)
得到的结果 列表
[小明','赵昊','王猛','张三]