1.一般字符类
. --匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
? --匹配一个任意字符
^ --匹配字符串的开头
$ --匹配字符串的末尾。
[…] --用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’
[^…] --不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
例:
[Pp]ython --匹配 “Python” 或 “python”
rub[ye] --匹配 “ruby” 或 “rube”
[aeiou] --匹配中括号内的任意一个字母
[0-9]-- 匹配任何数字。类似于 [0123456789]
[a-z] --匹配任何小写字母
[A-Z] --匹配任何大写字母
[a-zA-Z0-9] --匹配任何字母及数字
[^aeiou] --除了aeiou字母以外的所有字符
[^0-9] --匹配除了数字外的字符
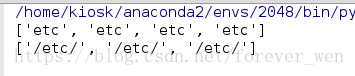
import re
s = "etc/resolv.conf', '/etc/extlinux.conf', '/etc/mtools.conf', '/etc/"
pattern1 = r"etc"
pattern2 = r"/etc/"
print(re.findall(pattern1,s))
print(re.findall(pattern2,s))
2.特殊字符类(字符出现的次数)
re* --匹配0个或多个的表达式。
re+ --匹配1个或多个的表达式。
re? --匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
re{ n} --精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。
re{ n,} 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。“o{1,}” 等价于 “o+”。“o{0,}” 则等价于 “o*”。
re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
特殊字符类(预定义字符)
\w --匹配字母数字及下划线,等价于’[A-Za-z0-9_], 这里中文也可以匹配
\W --匹配非字母数字及下划线 ,[^A-Za-z0-9_]
\s --匹配任意空白字符,等价于 [\t\n\r\f\v]
\S --匹配任意非空字符,等价于 [^ \f\n\r\t\v]
\d --匹配任意数字,等价于 [0-9]
\D --匹配任意非数字,等价于 [^0-9]
\A --匹配字符串开始
\Z --匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串
\b --匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。
\B --匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。
import re
print(re.findall(r".","hello\n"))
print(re.findall(r"\d","dhjc987"))
print(re.findall(r"\D","dhjc987"))
print(re.findall(r"\s","hello\nworld\t你好\r"))
print(re.findall(r"\S","hello\nworld\t你好\r"))
print(re.findall(r"\w","ni号123_____%^&"))
print(re.findall(r"\W","ni号123_____%^&"))
