利用python对excel或者csv文件进行批量操作时,除了使用xlrd库或者xlwt库进行表格的操作读与写,还可以使用pandas库进行类似的操作,而且一些情况下pandas操作更加简介方便。
pandas的read_csv或者read_excel方法可以进行读取操作,我们看到参数很多,使用skiprows可以设置跳过相应的行数:
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
arse_cols=None,date_parser=None,na_values=None,thousands=None,
convert_float=True,has_index_names=None,converters=None,dtype=None,
true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
io参数:一般是文件路径+文件名,
sheet_name参数:用来设置读取的工作表名称,可以为str,int,list或None,默认0。
设置为整数用于零索引工作表位置,字符串/整数列表用于请求多个工作表。设置None获取所有工作表。
header参数:用来指定哪些行作为列名的,默认是第0行,接收的参数可以是整数,可以是有整数组成的列表
index_col参数:指定用哪些列做为行索引,可以接收整数,或者由整数组成的列表,默认是None。
这个参数的作用是指定用哪一列做为行索引。如果传给参数的是整数n,则表示指定第n列作为行索引,如果传入的是列表,则表示需要指定多列作为行索引。
skiprows参数:要跳过的行或行范围(甚至是lambda)下面是操作文件案例:

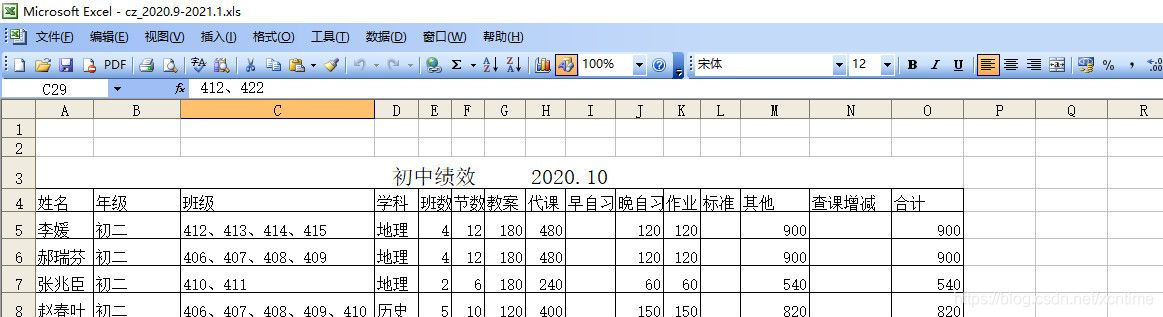
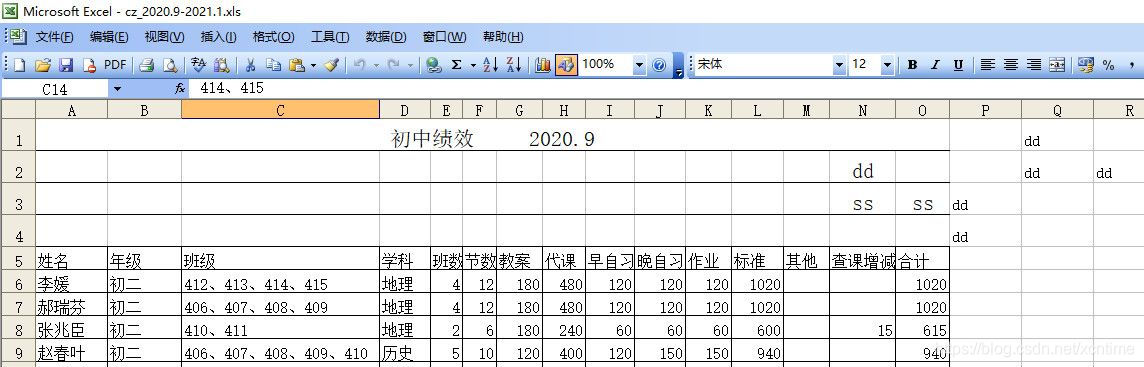
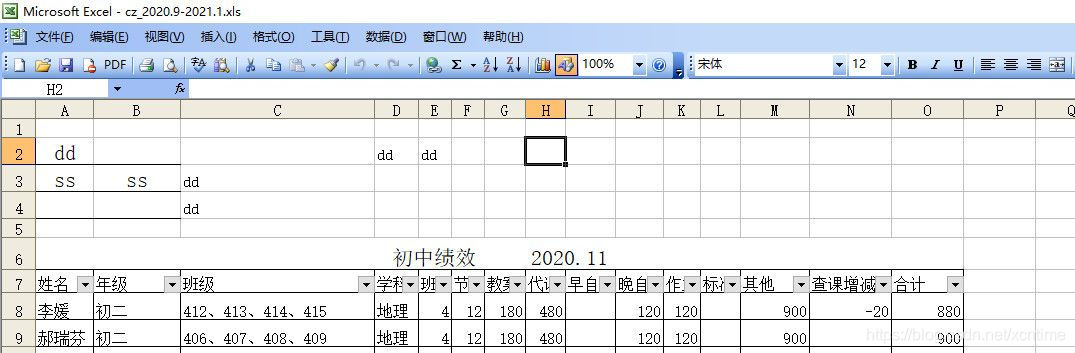
我们观察到,多个工作表中的标题前一定数量的空行无用行,而且不同工作表标题前的空行数量不一样,导致行索引的行位置不确定,能不能让程序自己来判断,跳过相应的行数呢
import pandas as pd
import numpy as np
import re
dfs=pd.read_excel(r".\cz_2020.9-2021.1.xls",sheet_name=None,header=None,index_col=None,skiprows=None)
df_dst=pd.DataFrame(data=None,columns=["姓名","年级","合计"])
for sht_name,df in dfs.items():
#仅仅读取 XXXX.XX格式的工作表
if re.match(r"\d{4}\.\d{1,2}",sht_name):
# first_row = (df.count(axis=1) >= df.shape[1]).idxmax() #查找列名所在行数的一种方法,处理10,11月份没有问题,9月份出现问题
first_row = (df.count(axis=1) >= df.count(axis=1).max()).idxmax() #查找列名所在行数的另一种办法
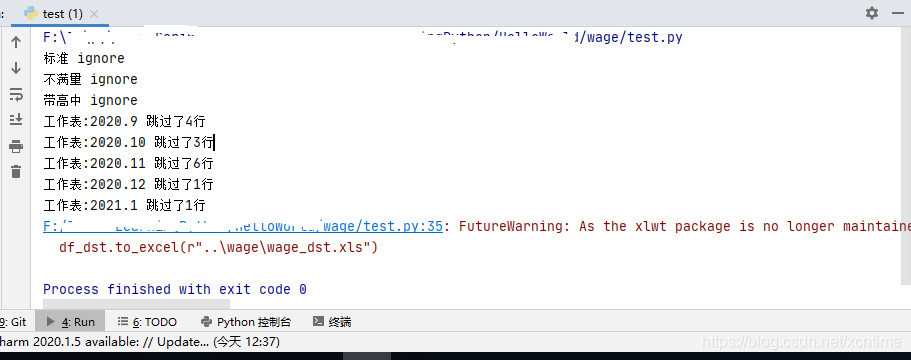
print("工作表:%s 跳过了%d行" %(sht_name,first_row))
df.columns=df.loc[first_row] #更改当前df的列索引名称
df.rename(columns =lambda x:str(x).strip("\r\n\t ."),inplace=True) #去掉列名首位的空白字符
df=df.loc[first_row+1:]
df_dst=pd.merge(df_dst,df[["姓名","年级","合计"]],how="outer",on="姓名",suffixes=("",sht_name)) #以姓名作为公共列,对多个df数据集进行连接。
#print(df)
else:
print(sht_name,"ignore")
#删掉第一个年级列,将第一个合并列移动到最后
df_tmp=df_dst.pop("合计")
df_dst.insert(df_dst.shape[1],"合计",df_tmp)
df_dst= df_dst.drop(["年级"],axis=1)
df_dst.to_excel(r"..\wage\wage_dst.xls")
程序运行结果如下:
最关键的代码如下:
# first_row = (df.count(axis=1) >= df.shape[1]).idxmax() #查找列名所在行数的一种方法,处理10,11月份没有问题,9月份出现问题
first_row = (df.count(axis=1) >= df.count(axis=1).max()).idxmax() #查找列名所在行数的另一种办法
df.columns=df.loc[first_row] #更改当前df的列索引名称
df=df.loc[first_row+1:]
也就是充分利用df.count(axis=1)的效果,对10,11月份的工作表使用(df.count(axis=1) >= df.shape[1]).idxmax()也可以达到效果,但是