第一步:模块安装
pip install pandas
第二步:使用(单个工作表为例)
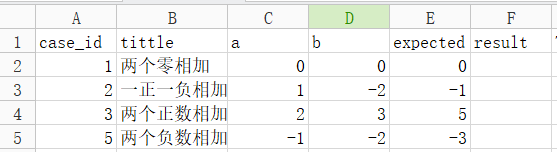
说明:如果有多个工作表,那么只要指定sheetname=索引,(第一个工作表为0,第二个工作表为1,以此类推)
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True,has_index_names=None,converters=None,dtype=None,true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
第三步:导入与读取数据
import pandas as pd #映入模块
df = pd.read_excel('python0109.xlsx') #读取excel
第四步:读取表格数据(iloc[]与loc[]区别)
loc[]:基于行标签和列标签(x_label、y_label)进行索引
列标签:从0开始
行标签:默认第一行为行标签
例如:df.loc[0,"case_id"]
结果:1
例如:df.loc[0,"title"]
结果:两个零相加
iloc[]:基于行索引和列索引(index,columns) 都是从 0 开始
注意:他的行索引默认从第二行开始
例如:df.iloc[0,0]
结果:1
例如:df.iloc[0,1]
结果:两个零相加
第四步:reindex()使用
df.reindex(['case_id','title','a','b','expected']) 默认指行
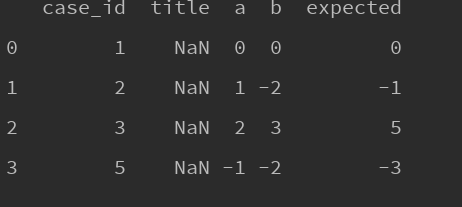
例如:df.reindex(columns=['case_id','title','a','b','expected']) 指明之后是列
结果:
第四步:存入列表
1 import pandas as pd 2 df = pd.read_excel('python0109.xlsx') 3 test_data = [] 4 for i in df.index.values:#获取行号的索引,并对其进行遍历: 5 #根据i来获取每一行指定的数据 并存入到列表中 6 row_data = df.loc[i].reindex(['case_id','title','a','b','expected']) #loc[i]这里就是行,reindex(['case_id','title','a','b','expected'])这里就是列
7 test_data.append(row_data) 8 print(test_data)
备注:学习记录知识