C
C是惩罚系数,即对样本分错的宽容度。C越高,说明越不能容忍出现分错,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。
gamma
千万要注意地是这个,否则容易死记硬背,即gamma和 σ \sigma σ是倒数关系。
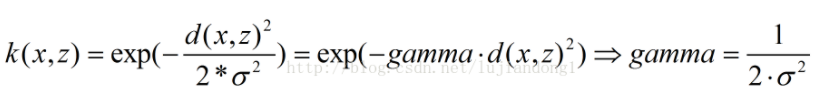
如果gamma设的太大,容易导致过拟合。
因为 σ \sigma σ会很小,很小的高斯分布长得又高又瘦,会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,但训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)。
反之,gamma越小,则往着欠拟合的方向走。
启示
当我们使用SVM的高斯核函数(RBF)的时候,如果发现训练数据上的准确率低,我们可以试着调大C,调大gamma。反之相反。