引言:
对于SVM的核函数,许多初学者可能在一开始都不明白核函数到底是怎么做到从二维空间映射到三维空间(这里我们特征空间以二维为例),因此本文主要讲解其中一种核函数——-高斯核函数作为介绍,另外感谢Andrew Ng在网易云课堂深入浅出的讲解,不但加深了我的理解,也为我写这篇博客提供了不少素材。
代价函数:
相比于Logistic Regression的代价函数:
SVM的代价函数只是稍微进行修改:
其中
其实也就是sigmod函数。
而cost函数可以由下图中的粉线表示:
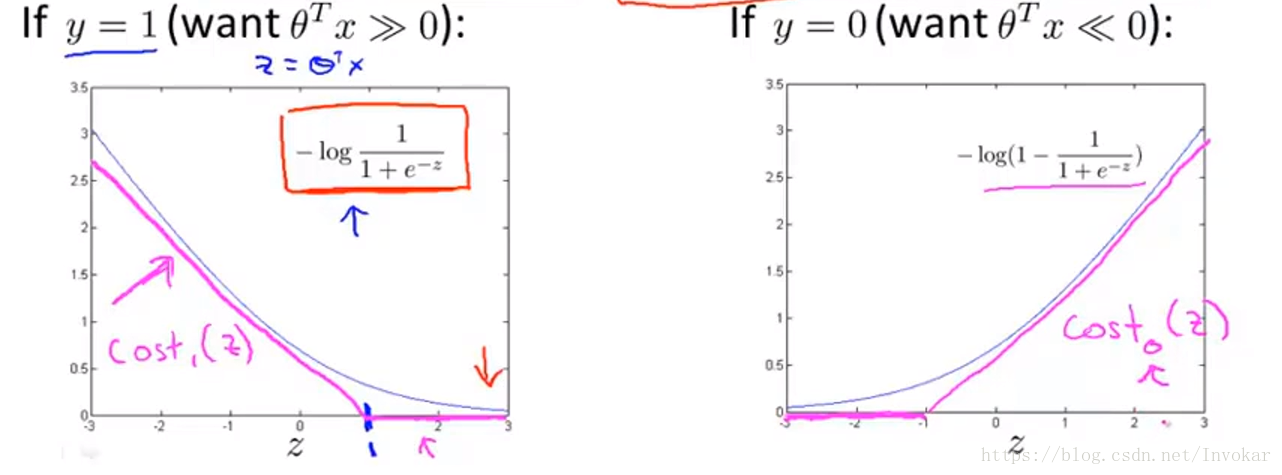
当然其中的转折点是人为定义的,这里选择以1为转折点。
此外,我们还能发现,相比于Logistic regression,SVM的优化函数只不是过 换成了 和修改了 函数,其实差别并不大。当然,我们也能从 老师PPT的图中可以看出sigmod函数的大致走向。
当然啦,如果你看不懂这个也没关系,这与下面的高斯核函数的理解上联系并不紧密。
为了引出核函数的作用,我们先来观察决策边界为非线性的情况:
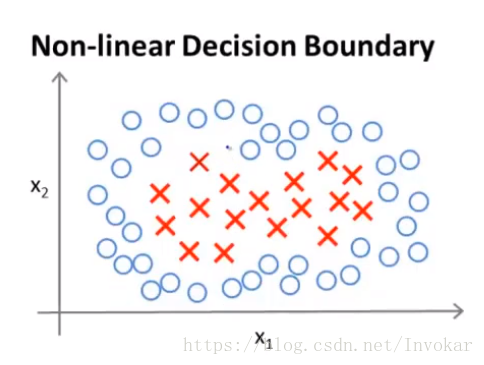
并且我们假设认为
否则, 为图中的 蓝色O
要想拟合这个非线性的决策边界,其中有一种方法就是用 高阶函数去拟合这个特征,事实上,这个方案是并不可行,因为这样做存在一定的问题: 从理论上来说,我们有很多不同的特征去选择来拟合这个边界(选择起来是一个问题)或者可能会存在比这些高阶多项式更好的特征,因为我们并不知道这些高阶多项式的组合是否一定对模型的提升有帮助。
引入高斯核函数:
首先我们先来看一下三维正态分布的图像:
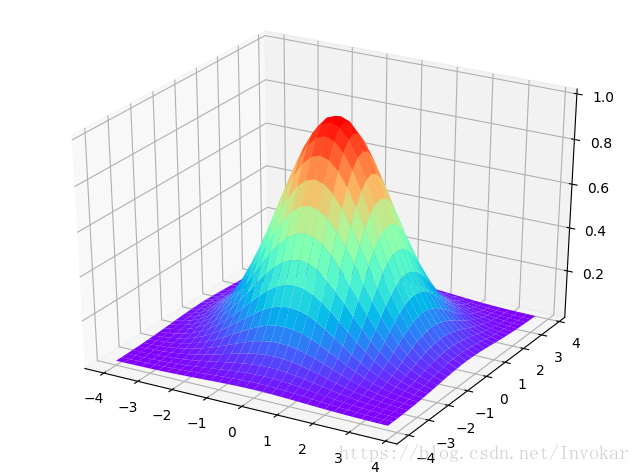
从图像中我们可以看出,离中心点越近,函数值就越接近于1。
其公式为:
由指数函数的特征,我们可以看到,如果指数部分为接近0,那么
就会接近1;如果指数部分越小,那么
就会越接近于0。
讲到这里,是否有点熟悉的感觉?没错,之前我在讲标签判定的时候,说到
决定着最后类别的确定,那么试想一下,如果我们把2维平面上的点,映射到到上图中,那么从上往下看就会看到类似于下面这张同心圆的图:
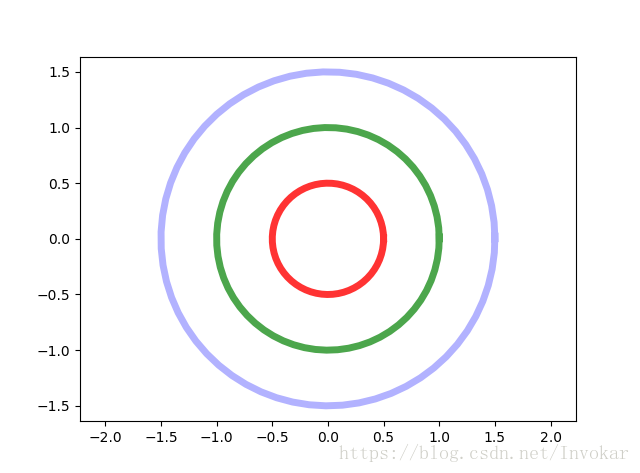
因此以任意一种颜色的同心圆作为决策边界,我们都可以完成对数据集的简单非线性划分。那么问题来了,如何映射到高维空间上去呢?——————高斯核函数!
我们可以在二维空间中构造3个新特征,如下图(PS:这是只是打个比方,现实中并不一定是3个特征)
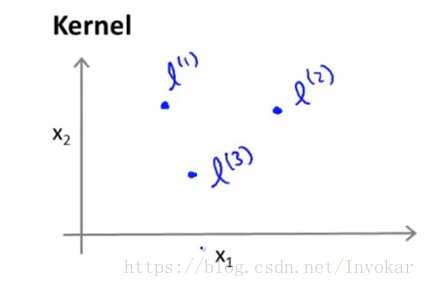
然后重新定义我们的假设:
否则, 为图中的 蓝色O
其中 就为我们的高斯核函数
那么就在这个平面上而言,越是接近于这三个点的点,他由通过高斯核函数对3个特征点进行计算时,结果之和就越容易大于1。
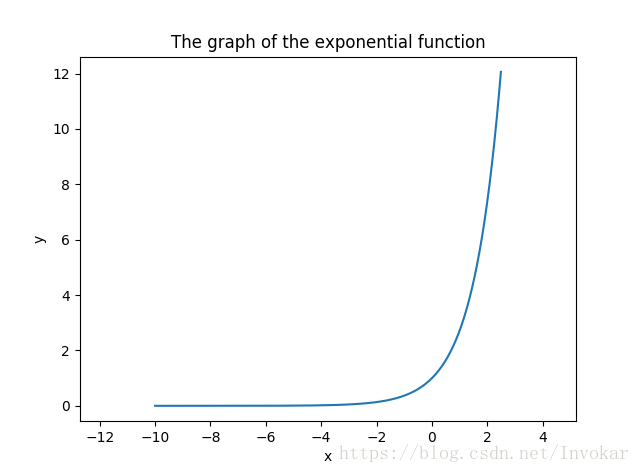
因为如果
和
越是接近,2范数就越趋向于0,则指数函数趋向于1,而对于那些别叫远的点而言,指数项中的
则会越大,前面添上”
”号,就越小,那么有指数函数的变化可得,结果之和会小于1。
所以到这里,我们便可以把二维平面上的数据点,映射到三维空间中,从而达到了可以进行复杂的非线性决策边界的学习。
如果觉得我有地方讲的不好的或者有错误的欢迎给我留言,谢谢大家阅读~