TfidfVectorizer
作用
将文本进行向量化表示。
原理
这里的tf(term frequency)是词的频数,idf(inverse document frequency)是这个词的逆文档频率。
假设有文档集合如下:
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
其中列表中的每个元素都是一个文档,所以上面一共有4个文档。第一个文档为"Chinese Beijing Chinese"。
那么我们如何将这些文档变成向量呢?
老方法,我们先统计所有文档中的词汇量。一共有{“Chinese",“Beijing”,“Shanghai”,“Macao”,“Tokyo”,“Japan”}6个词汇。
然后我们将我们的每一个文档都用一个6维向量来表示,但是问题是每一维向量上我们应该填什么数?
第一种方法
我们可以使用one-hot编码,那么第二个文档就会被编码成(1,0,1,0,0,0),因为第一个文档只有{“Chinese”,“Shanghai”}两个词汇。
第二种方法
我们发现方法一不是0就是1,我们是否可以改进一下?使得这个向量代表更多信息?可以使用tf-idf。
我们先看idf的公式:
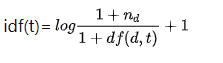
以第一个文档为例(“Chinese Beijing Chinese”):
tf的计算很简单,数就行了,tf("Chinese")=2,tf("Beijing")=1。可以注意到我前面的用词,是词的频数,虽然英语是frequency(频率)。idf的计算稍微复杂一些。我们需要查看整个文档,计算idf("Chinese"),我们先统计"Chinese”在整个文档集合中出现的次数,我们发现4个文档中都有"Chinese”,即 d f ( d , " C h i n e s e " ) = 4 df(d,"Chinese")=4 df(d,"Chinese")=4,而 n d n_d nd表示文档集的文档个数,所以 n d = 4 n_d=4 nd=4。将以上两项带入idf公式,有idf("Chinese")=log(5/5)+1=0+1=1。同理idf("Beijing")=log(5/2)+1=1.916290731874155,注意这里的对数是以 e e e为底的。- 最后,我们使用公式 t f i d f ( t ) = t f ( t ) ∗ i d f ( t ) tfidf(t)=tf(t)*idf(t) tfidf(t)=tf(t)∗idf(t)得到
tfidf("Chinese")=2*1=2,tfidf("Beijing")=1*1.916290731874155=1.916290731874155。最终得到第一个文档的向量化表示(2, 1.916290731874155, 0, 0, 0, 0 )。当然,接着我们可以规范标准化表示,即 v ′ = v ∣ ∣ v ∣ ∣ 2 v'=\frac{v}{||v||_2} v′=∣∣v∣∣2v,或者叫做归一化。变成:(0.722056, 0.691834610, 0, 0, 0, )
我们使用sklearn来进行验证
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer()#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
print("fit后,训练数据的向量化表示为:")
print(tv_fit.toarray())
结果如下:
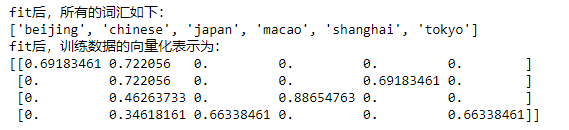
这和我们计算的是一样的(注意这里的词汇表是按字典顺序排的,所以第一个是"Beijing",我们要对号入座)。
紧接着,充实好了tv之后。我们如何将测试文档转化为向量表示呢?使用transform函数
test=["Chinese Beijing shanghai"]
tv_test=tv.transform(test)#测试数据不会充实或者改变tv,但这步充实了tv_test。
print("所有的词汇如下:")
print(tv.get_feature_names())
print("测试数据的向量化表示为:")
print(tv_test.toarray())
结果如下:

再次强调,测试数据是不会影响tv的,也就是说,原来训练的时候文档集是4个文档,现在计算idf的时候, n d n_d nd还是为4,而不是变成5个文档。类似的,idf公式中的df(d,t)也是查找单词t出现在原来4篇中的多少篇文档中。
结束
最后,我们可以用得到的向量,进行分类或者计算文档之间的相似度(比如使用余弦相似度)进行聚类等等。
补充
TfidfVectorizer中有一些参数或许我们会用得上,比如:

(一)
stop_words
这个是停用词,停用词就是说一些无关紧要的词,比如中文中{"的“,”地“}等等。你可以提供一个停用词的库给tv,那么tv将在文档中自动忽略这些停用词,相当于对文档做了一个预处理,删除了这些文档中的所有停用词。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(stop_words=["chinese"])#停用词注意要用小写,因为train会被自动转成小写。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
结果:

即没有了"chinese”这个停用词,词汇量少了一个。
我们再看另外一个值(直接指定为"english")。
stop_words="english"
这表示,sklearn中内部有一个大家普遍都认同的英语停用词库,比如"the"等。注意这是sklearn内置的,中文没有。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["the Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(stop_words="english")#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())

我们发现"the“作为停用词被自动删除了。
(二)
ngram_range
直接给个例子就明白了。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(ngram_range=(1,2))#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
结果:

我们发现,比之前多了一些词汇,现在两个单词组合在一起也被认为是一个词汇了。这是自然语言处理中的2元短语。在此处,这个参数表示将1元短语(单词),2元短语都看作总词汇表中的1项。
类似的你可以随便改参数,例如:
ngram_range=(2,2)#表示只要2元短语作为词汇表项。
(三)
max_df=0.9, min_df=2#如果是整数,那么就是含有该词的绝对文档数,如果是小数,就是含有该词的文档比例。
这个df应该还记得把?就是文档频率,但是注意不是逆(倒数)的,比如在上面"Shanghai"出现在4篇文档中的1篇,那么其频率就是0.25。
这个参数的意思就是删去那些在90%以上的文档中都会出现的词,同时也删去那些没有出现在至少2篇文档中的词。
比如:
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(max_df=0.9,min_df=0.25)#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
结果:

我们发现,这没有了"Chinese",因为其文档频率为df(d,"Chinese")=4/4=1>0.9。相当于是停用词,被忽略了。