前言
本部分按照数据链路层、网络层、传输层以及应用层进行分类,共有 10 个实验。需要使用协议分析软件 Wireshark 进行,请根据简介部分自行下载安装。
准备
请自行查找或使用如下参考资料,了解 Wireshark 的基本使用:
选择对哪块网卡进行数据包捕获
开始/停止捕获
了解 Wireshark 主要窗口区域
设置数据包的过滤
跟踪数据流
一、数据链路层
实作一 熟悉 Ethernet 帧结构
使用 Wireshark 任意进行抓包,熟悉 Ethernet 帧的结构,如:目的 MAC、源 MAC、类型、字段等。
参考:wireshark抓包新手使用教程




实作二 了解子网内/外通信时的 MAC 地址
ping 你旁边的计算机(同一子网),同时用 Wireshark 抓这些包(可使用 icmp 关键字进行过滤以利于分析),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址是多少?这个 MAC 地址是谁的?
然后 ping qige.io (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 icmp 过滤),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址是多少?这个 MAC 地址是谁的?
再次 ping www.cqjtu.edu.cn (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 icmp 过滤),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址又是多少?这个 MAC 地址又是谁的?
1.
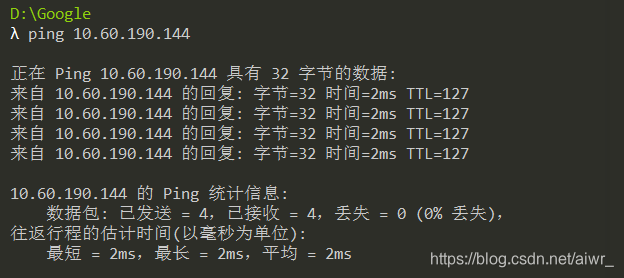
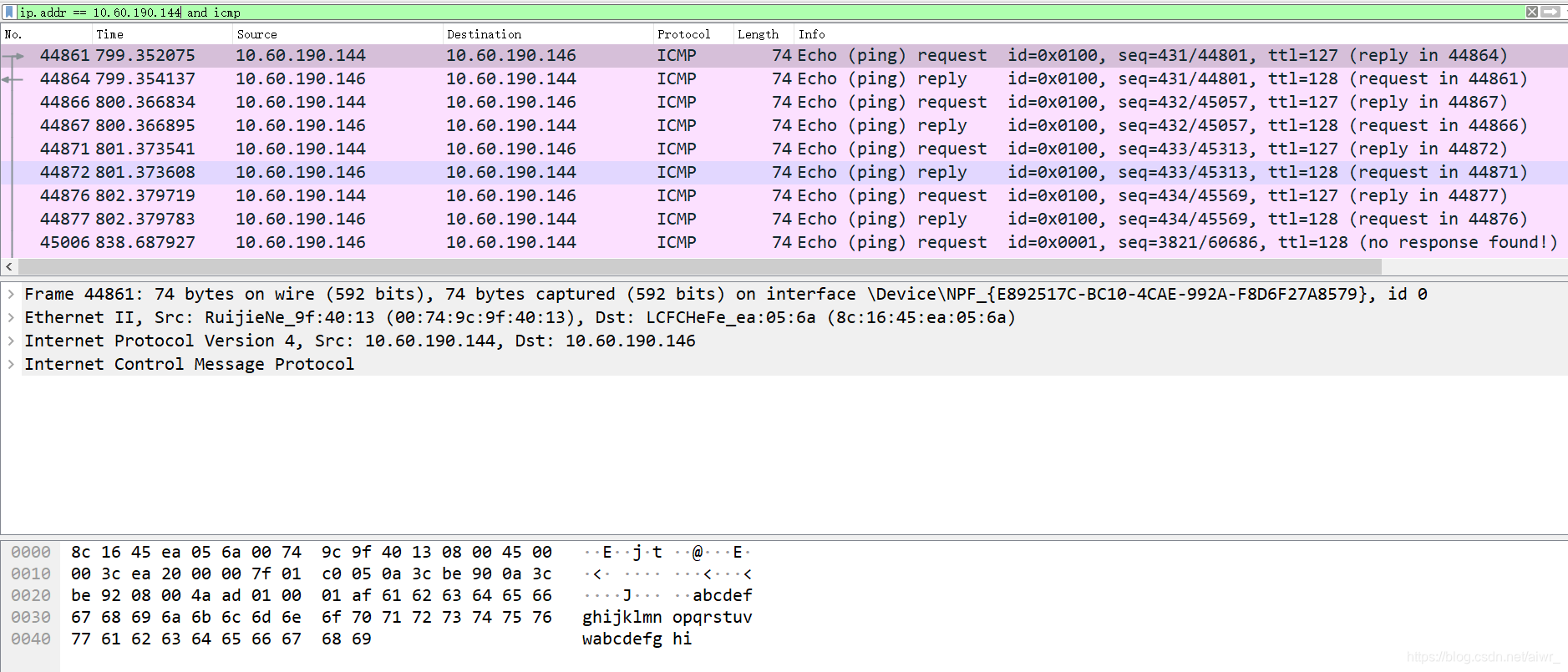
ping旁边的计算机,虽然处于同一子网,不过发出帧和返回帧的MAC地址均会存在问题(会经过网关),具体问题未知
2.
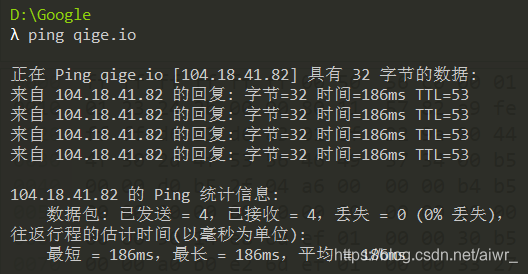
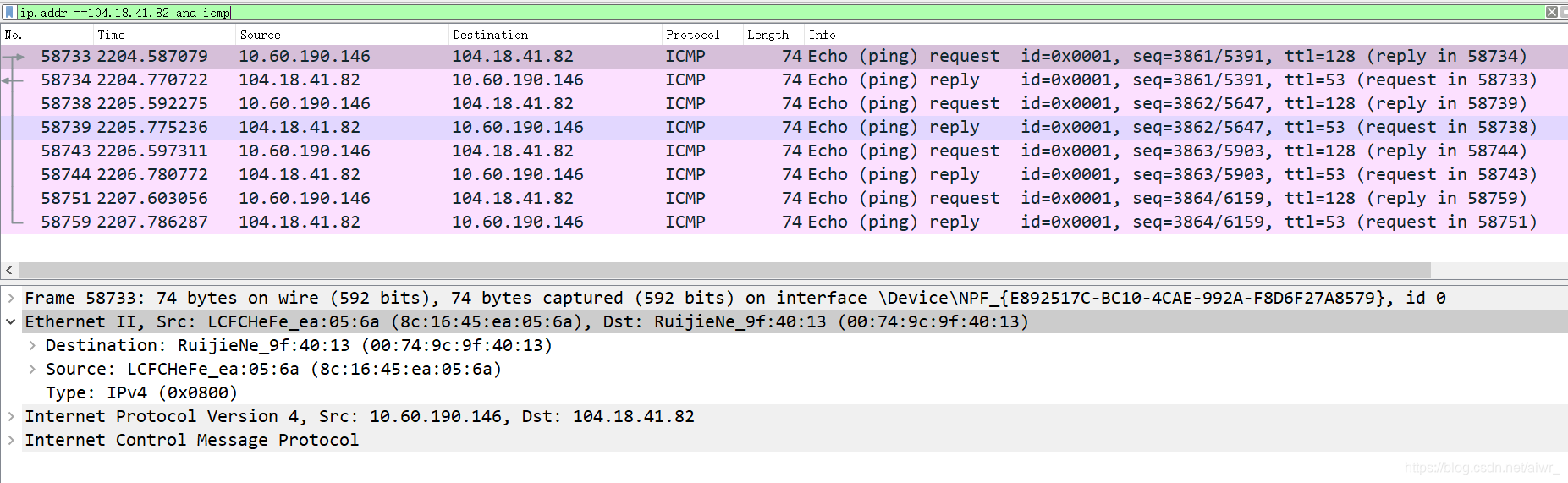
发出帧的目的 MAC 地址:00:74:9c:9f:40:13
返回帧的源 MAC 地址:00:74:9c:9f:40:13
这个地址是本主机所在子网的网关MAC地址
3.
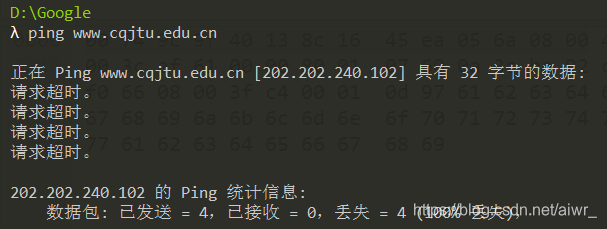
发出帧的目的 MAC 地址:00:74:9c:9f:40:13
返回帧的源 MAC 地址:00:74:9c:9f:40:13
这个地址是本主机所在子网的网关MAC地址
问题
通过以上的实验,你会发现:
访问本子网的计算机时,目的 MAC 就是该主机的
访问非本子网的计算机时,目的 MAC 是网关的
请问原因是什么?
访问本子网的计算机时,目的 MAC 就是该主机的,访问非本子网的计算机时,目的 MAC 是网关的。这是因为本机在访问非本子网的计算机时,必定会经过网关,而访问本子网的计算机时,是直接到达的,所以目的MAC地址就是该主机的。
实作三 掌握 ARP 解析过程
1.为防止干扰,先使用 arp -d * 命令清空 arp 缓存
2.ping 你旁边的计算机(同一子网),同时用 Wireshark 抓这些包(可 arp 过滤),查看 ARP 请求的格式以及请求的内容,注意观察该请求的目的 MAC 地址是什么。再查看一下该请求的回应,注意观察该回应的源 MAC 和目的 MAC 地址是什么。
3.再次使用 arp -d * 命令清空 arp 缓存
4.然后 ping qige.io (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 arp 过滤)。查看这次 ARP 请求的是什么,注意观察该请求是谁在回应。
1.
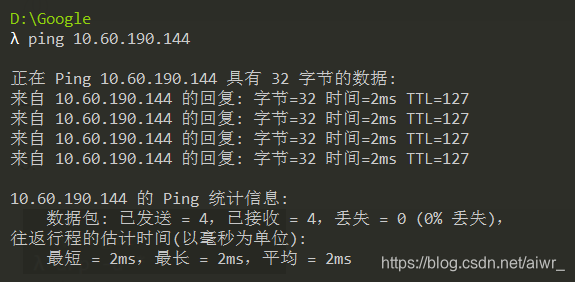
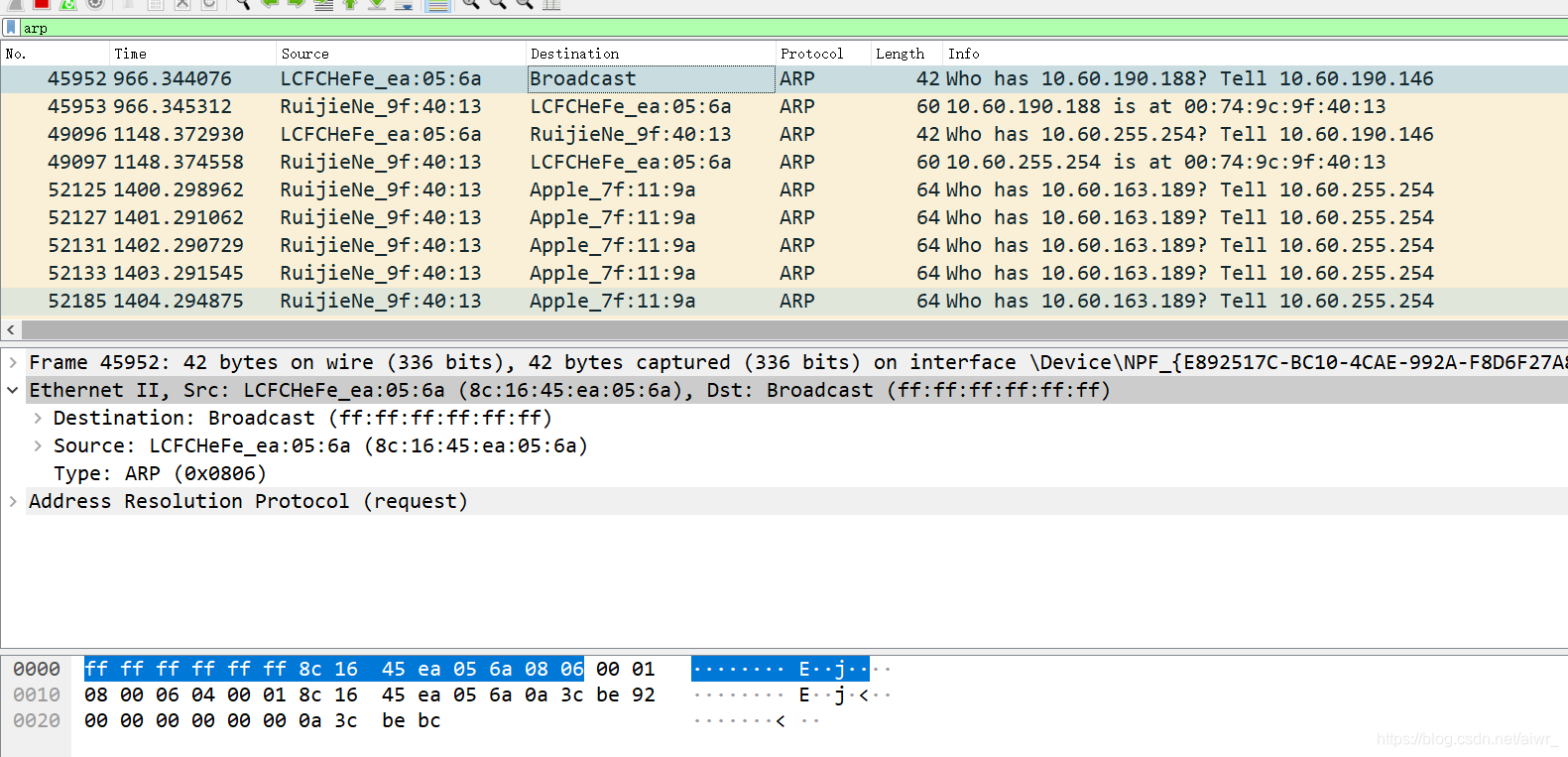
目的MAC地址:ff:ff:ff:ff:ff:ff
回复是对方的MAC物理地址
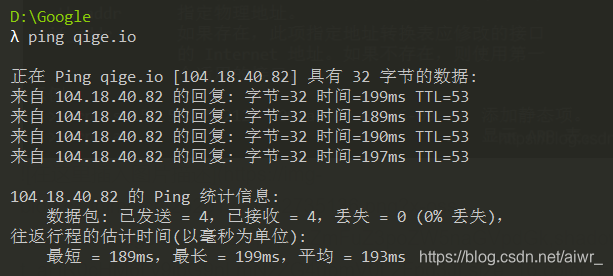

发出帧的目的 MAC 地址:ff:ff:ff:ff:ff:ff
问题
通过以上的实验,你应该会发现,
1.ARP 请求都是使用广播方式发送的
2.如果访问的是本子网的 IP,那么 ARP 解析将直接得到该 IP 对应的 MAC;如果访问的非本子网的 IP, 那么 ARP 解析将得到网关的 MAC。
请问为什么?
当本机访问的是本子网的计算机,数据包无需离开本通信子网, ARP 解析将也是在本子网里进行,所以ARP解析得到是对方主机的MAC物理地址;
当本机访问的是非本子网的计算机,数据包需要离开本通信子网,ARP 解析就要经过网关,因此,该ARP 解析得到的目的MAC物理地址就是本网关的物理地址。
二、网络层
实作一 熟悉 IP 包结构
使用 Wireshark 任意进行抓包(可用 ip 过滤),熟悉 IP 包的结构,如:版本、头部长度、总长度、TTL、协议类型等字段。
ping qige.io
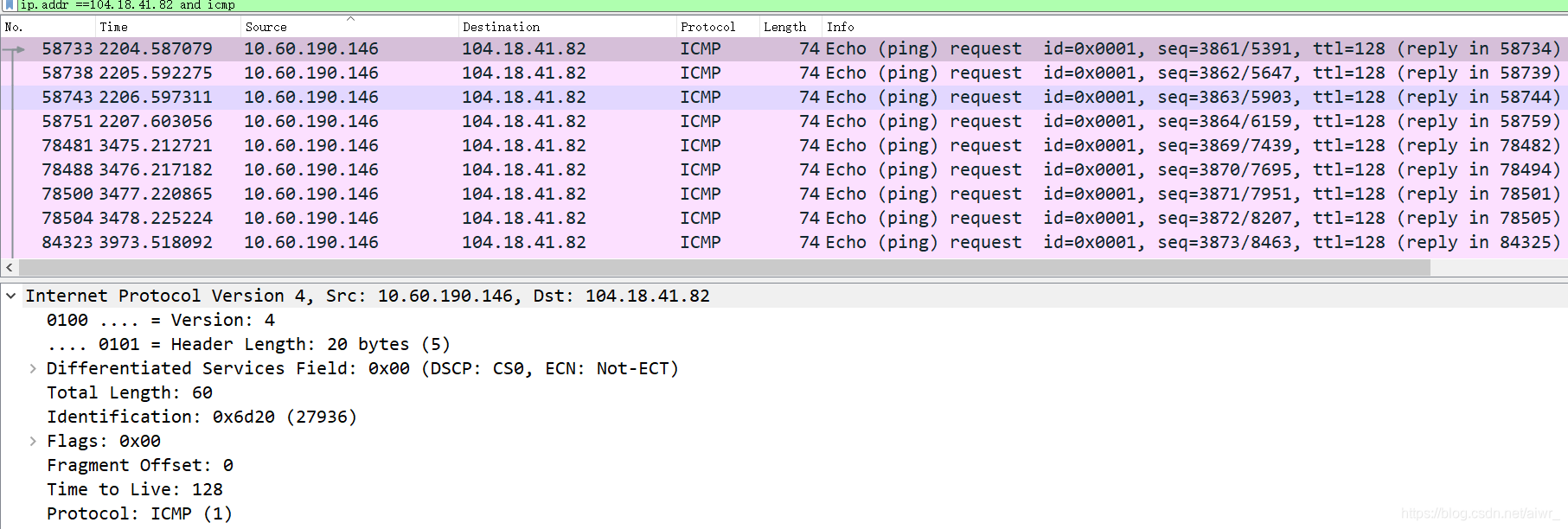
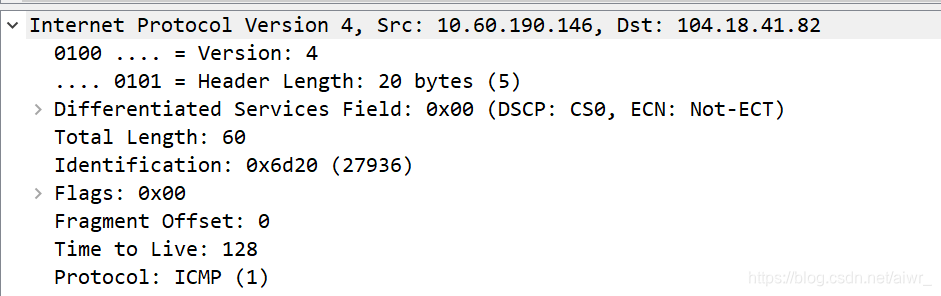
版本:IPV4
头部长度:20 bytes
总体长度:60
TTL:128s
协议:ICMP
问题
为提高效率,我们应该让 IP 的头部尽可能的精简。但在如此珍贵的 IP 头部你会发现既有头部长度字段,也有总长度字段。请问为什么?
IP的头部长度可使接收端计算出报头在何处结束及从何处开始读数据。而总长度字段则是接受数据,读出数据等。
实作二 IP 包的分段与重组
根据规定,一个 IP 包最大可以有 64K 字节。但由于 Ethernet 帧的限制,当 IP 包的数据超过 1500 字节时就会被发送方的数据链路层分段,然后在接收方的网络层重组。
缺省的,ping 命令只会向对方发送 32 个字节的数据。我们可以使用 ping 202.202.240.16 -l 2000 命令指定要发送的数据长度。此时使用 Wireshark 抓包(用 ip.addr == 202.202.240.16 进行过滤),了解 IP 包如何进行分段,如:分段标志、偏移量以及每个包的大小等
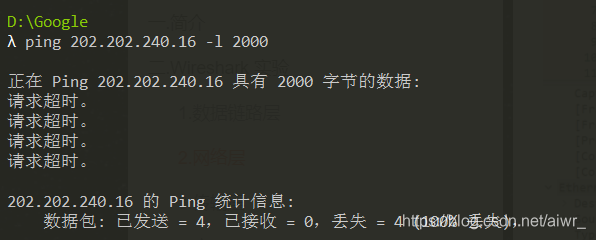
由于给出的地址不能请求成功,所以我换成了

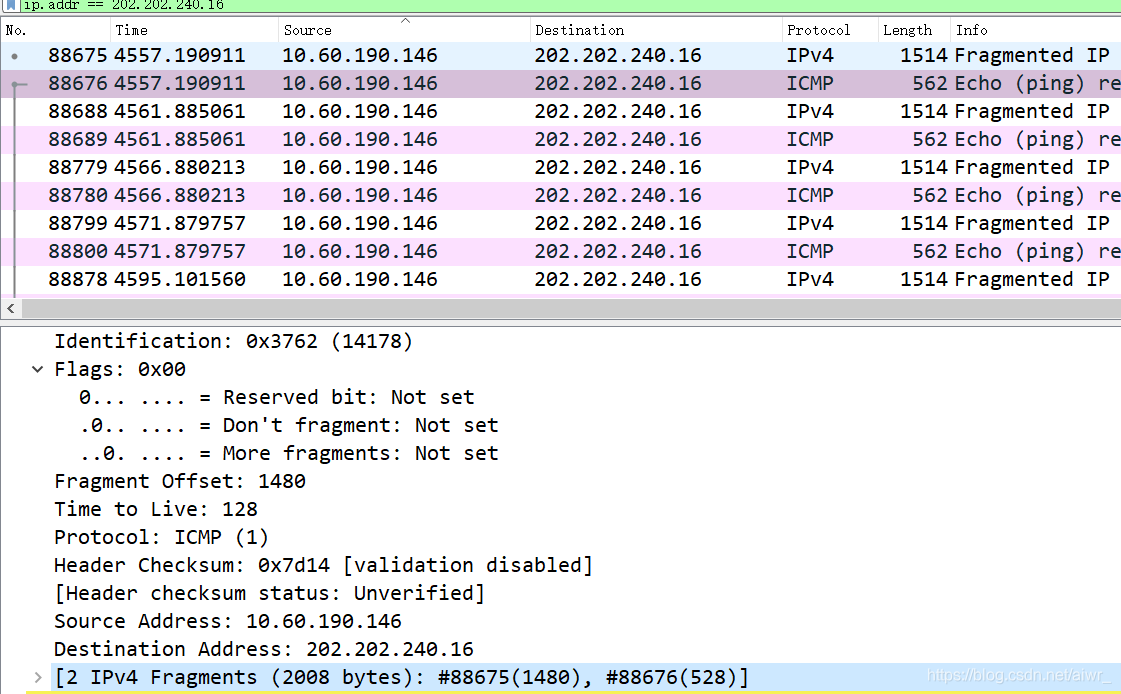
分成了1480和528两个包
问题
分段与重组是一个耗费资源的操作,特别是当分段由传送路径上的节点即路由器来完成的时候,所以 IPv6 已经不允许分段了。那么 IPv6 中,如果路由器遇到了一个大数据包该怎么办?
直接丢弃再通知发送端进行重传。
由于在 IPv6中分段只能在源与目的地上执行,不能在路由器上进行。当数据包过大时,路由器就会直接丢弃该数据包。
实作三 考察 TTL 事件
在 IP 包头中有一个 TTL 字段用来限定该包可以在 Internet上传输多少跳(hops),一般该值设置为 64、128等。
在验证性实验部分我们使用了 tracert 命令进行路由追踪。其原理是主动设置 IP 包的 TTL 值,从 1 开始逐渐增加,直至到达最终目的主机。
请使用 tracert www.baidu.com 命令进行追踪,此时使用 Wireshark 抓包(用 icmp 过滤),分析每个发送包的 TTL 是如何进行改变的,从而理解路由追踪原理。
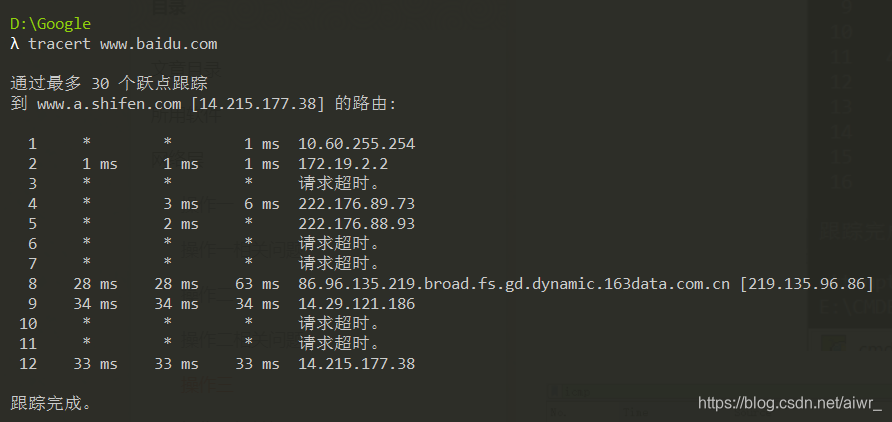

问题
在 IPv4 中,TTL 虽然定义为生命期即 Time To Live,但现实中我们都以跳数/节点数进行设置。如果你收到一个包,其 TTL 的值为 50,那么可以推断这个包从源点到你之间有多少跳?
50跳
三、传输层
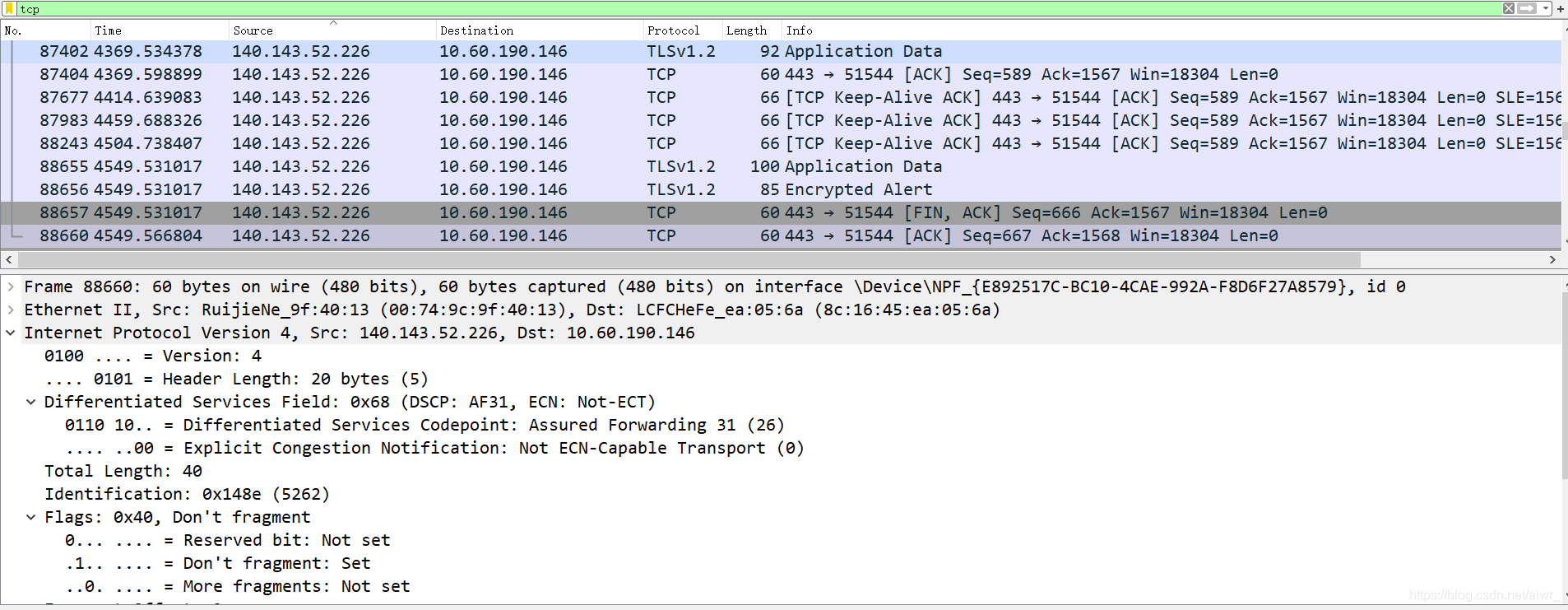
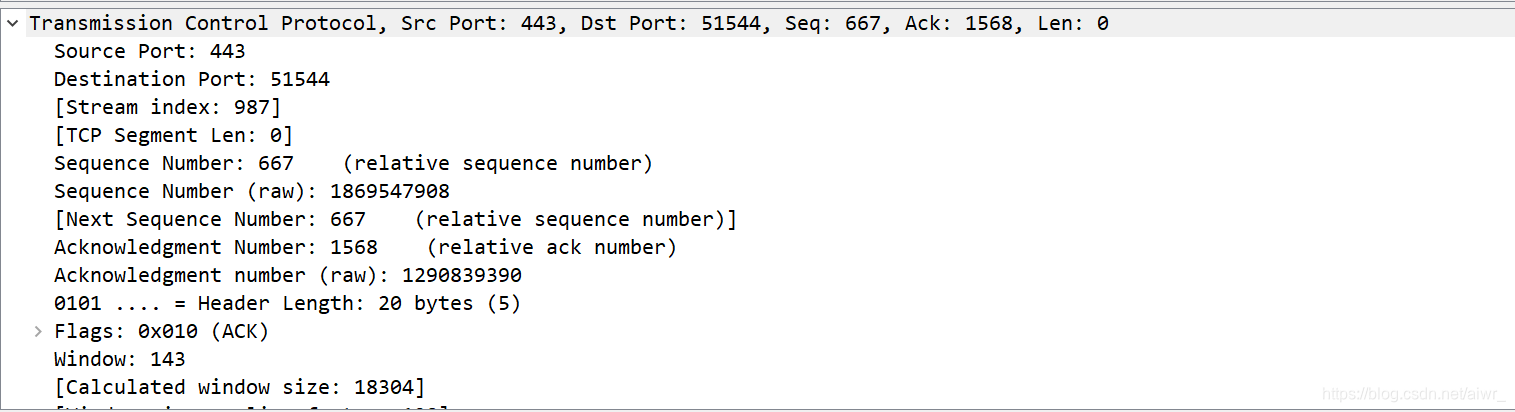
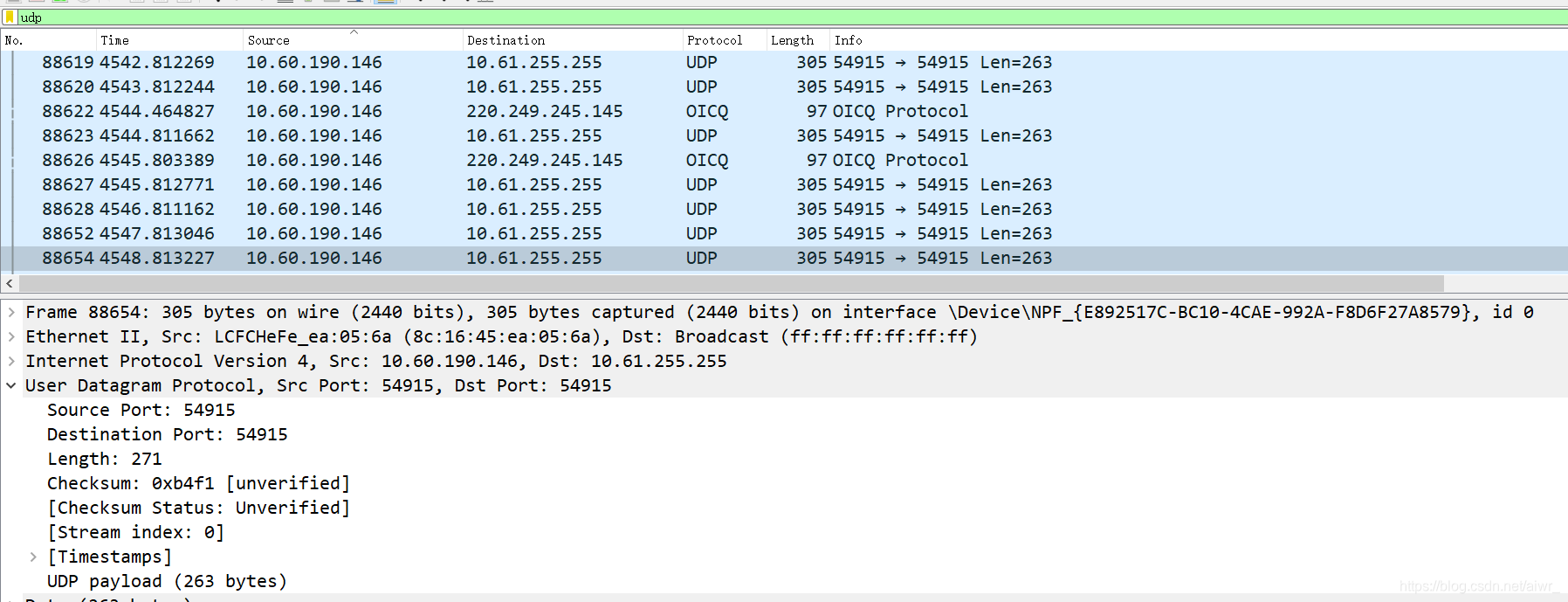
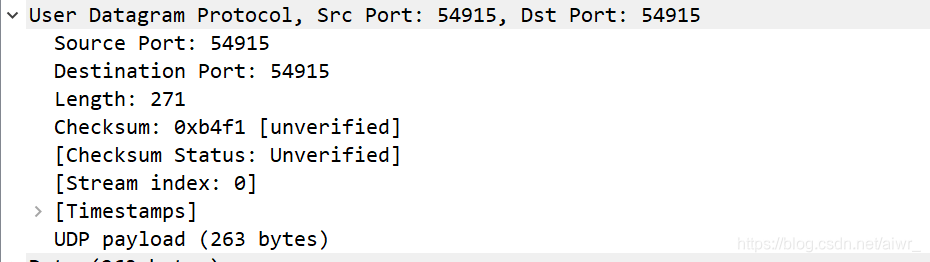
实作一 熟悉 TCP 和 UDP 段结构 用 Wireshark 任意抓包(可用 tcp 过滤),熟悉 TCP 段的结构,如:源端口、目的端口、序列号、确认号、各种标志位等字段。 用 Wireshark 任意抓包(可用 udp 过滤),熟悉 UDP 段的结构,如:源端口、目的端口、长度等。ping qige.io
tcp过滤
UDP过滤
问题
由上大家可以看到 UDP 的头部比 TCP 简单得多,但两者都有源和目的端口号。请问源和目的端口号用来干什么?
源端口和目的端口:(端口是用来指明数据的来源(应用程序)以及数据发往的目的地(同样是应用程序))字段包含了16比特的UDP协议端口号,它使得多个应用程序可以多路复用同一个传输层协议及UDP协议,仅通过端口号来区分不同的应用程序。
四、应用层
实作一 了解 DNS 解析
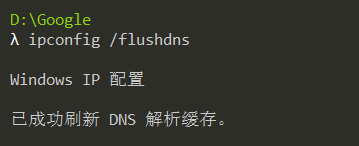
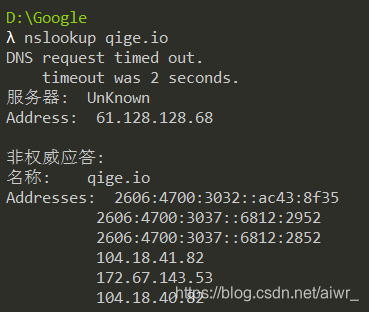
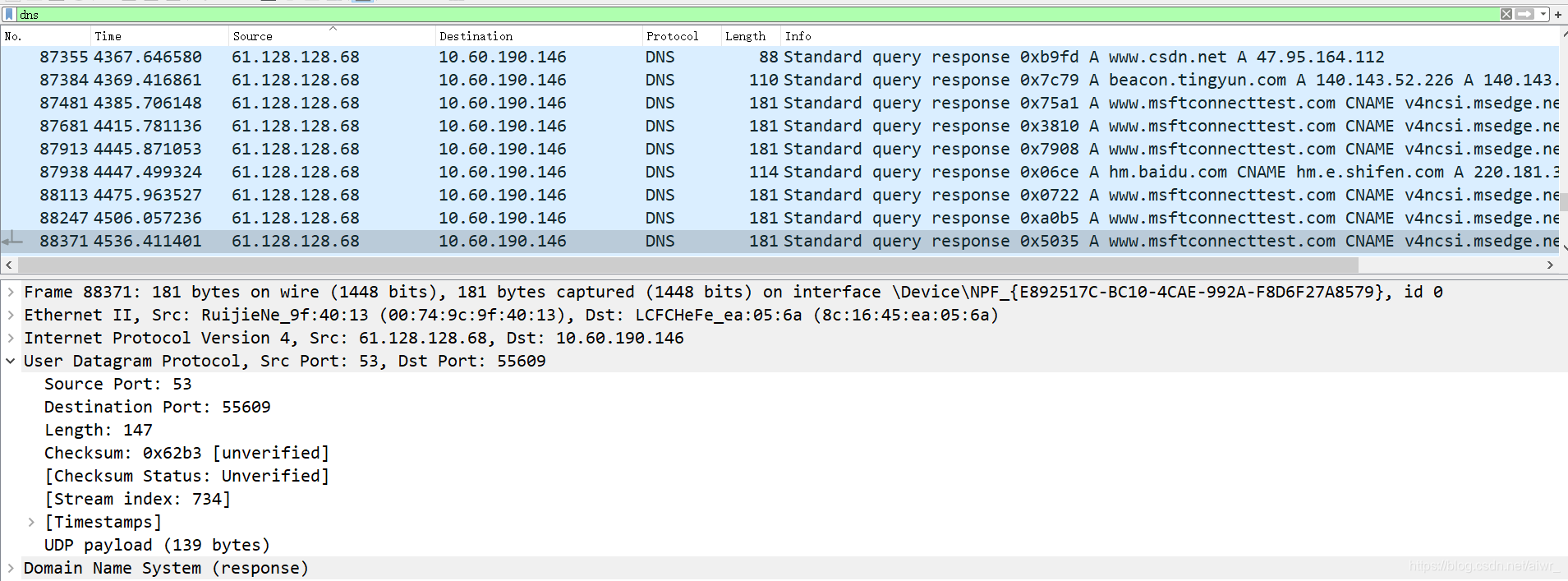
1.先使用 ipconfig /flushdns 命令清除缓存,再使用 nslookup qige.io 命令进行解析,同时用 Wireshark 任意抓包(可用 dns 过滤)。
2.你应该可以看到当前计算机使用 UDP,向默认的 DNS 服务器的 53 号端口发出了查询请求,而 DNS 服务器的 53 号端口返回了结果。
3.可了解一下 DNS 查询和应答的相关字段的含义
问题
你可能会发现对同一个站点,我们发出的 DNS 解析请求不止一个,思考一下是什么原因?
因为我们访问的网址只有一个域名,但服务器主机不唯一,每一台服务器的IP地址不同,但他们的域名都是相同的。因此发出的解析请求是分散给不同服务器。
实作二 了解 HTTP 的请求和应答
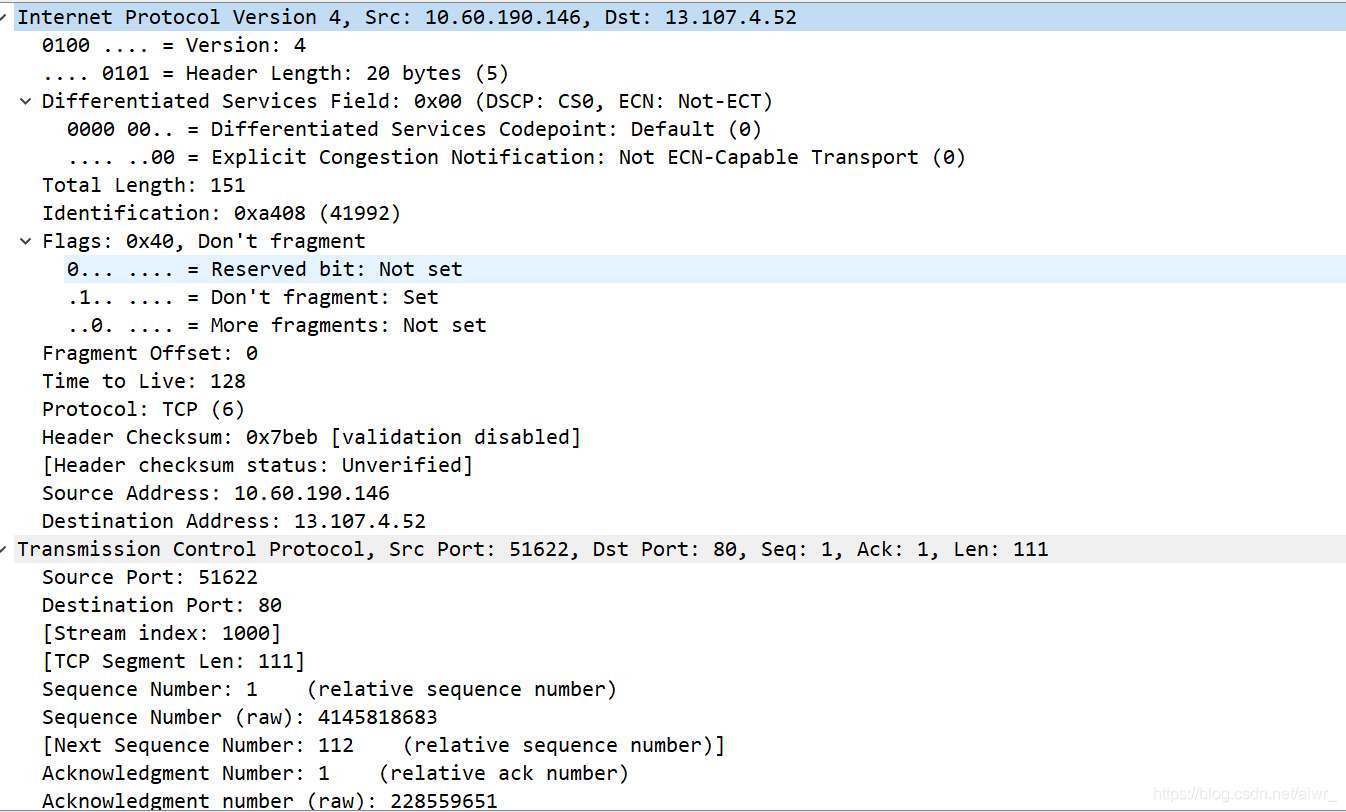
1.打开浏览器访问 qige.io 网站,用 Wireshark 抓包(可用http 过滤再加上 Follow TCP Stream),不要立即停止 Wireshark 捕获,待页面显示完毕后再多等一段时间以将释放连接的包捕获。
2.请在你捕获的包中找到 HTTP 请求包,查看请求使用的什么命令,如:GET, POST。并仔细了解请求的头部有哪些字段及其意义。
3.请在你捕获的包中找到 HTTP 应答包,查看应答的代码是什么,如:200, 304, 404 等。并仔细了解应答的头部有哪些字段及其意义。
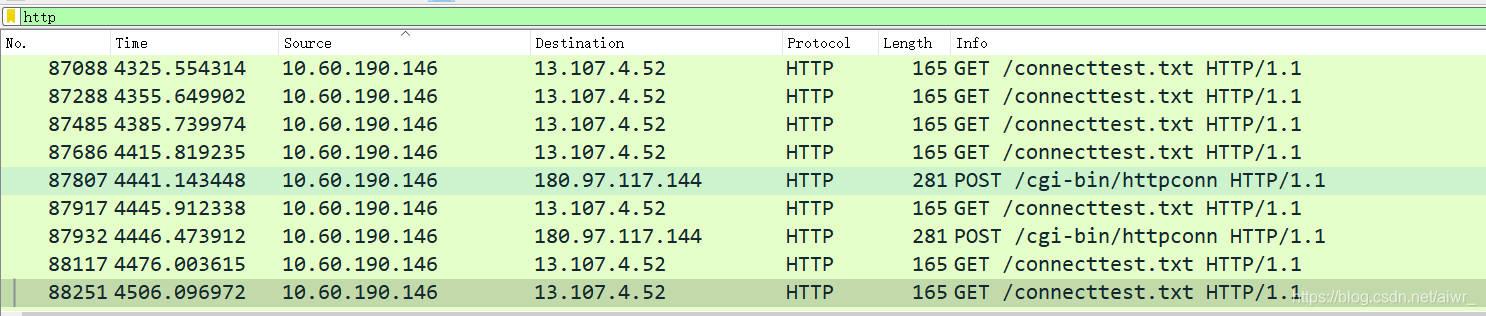
GET
POST

3.
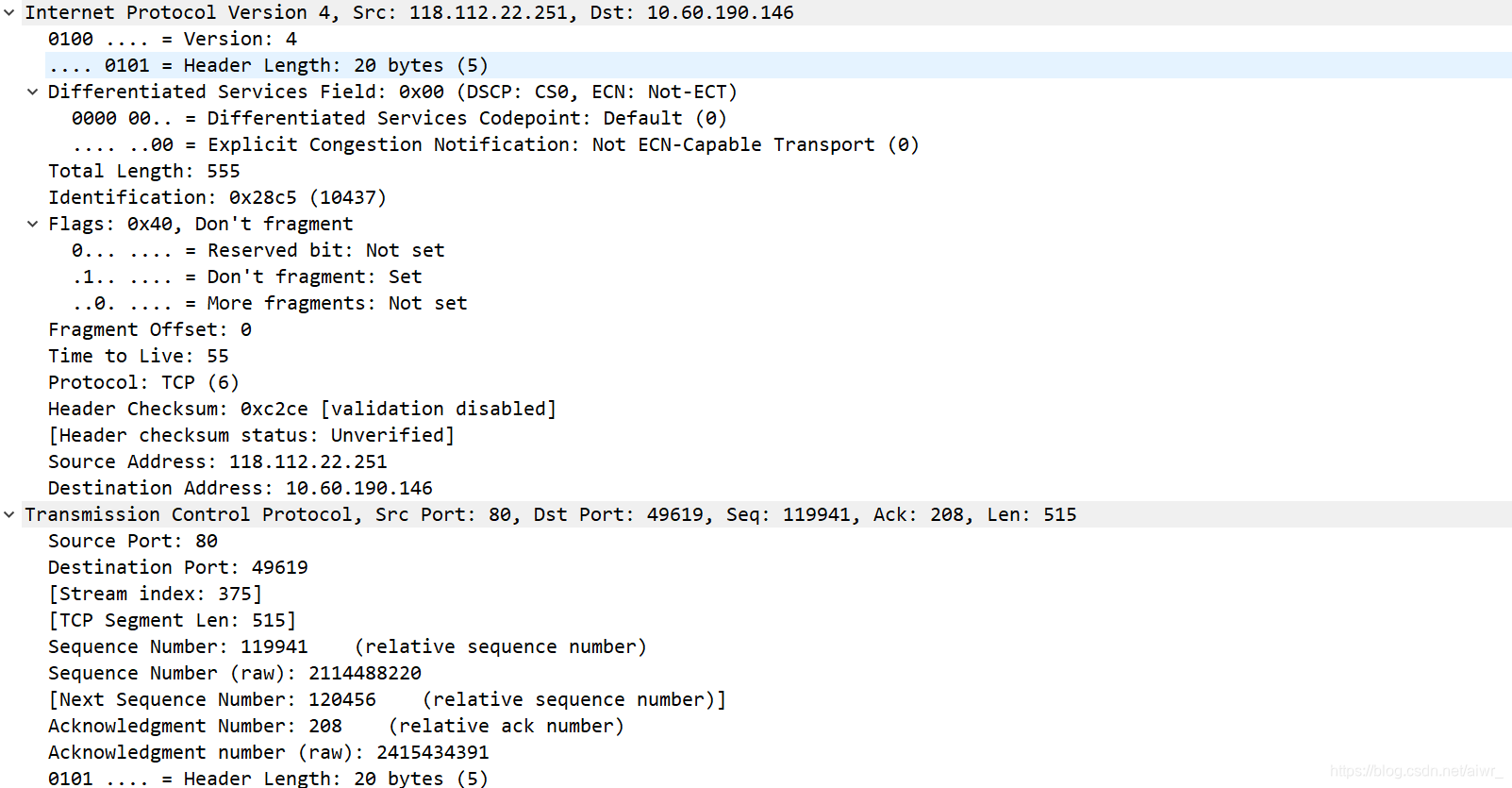
问题
刷新一次 qige.io 网站的页面同时进行抓包,你会发现不少的 304 代码的应答,这是所请求的对象没有更改的意思,让浏览器使用本地缓存的内容即可。那么服务器为什么会回答 304 应答而不是常见的 200 应答?
因为服务器告诉浏览器当前请求的资源上一次修改的时间是这个时间。浏览器第二次发送请求的时候,告诉浏览器上次请求的资源现在还在自己的缓存中,如果原来的资源没有修改,就可以不用传送应答体。服务器根据浏览器传来的时间发现和当前请求资源的修改时间一致,就应答304,表示不传应答体了,从之前的缓存里取。
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。