Pinpoint简介
Pinpoint是一款对Java编写的大规模分布式系统的APM工具,有些人也喜欢称呼这类工具为调用链系统、分布式跟踪系统。我们知道,前端向后台发起一个查询请求,后台服务可能要调用多个服务,每个服务可能又会调用其它服务,最终将结果返回,汇总到页面上。如果某个环节发生异常,工程师很难准确定位这个问题到底是由哪个服务调用造成的,Pinpoint等相关工具的作用就是追踪每个请求的完整调用链路,收集调用链路上每个服务的性能数据,方便工程师能够快速定位问题。Github地址:https://github.com/naver/pinpoint
其架构图如下(图片来自官网):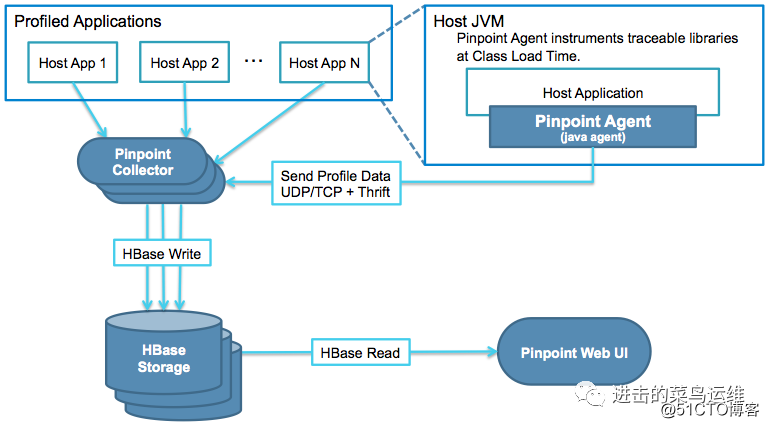
架构说明:
-
Pinpoint-Collector:收集各种性能数据
-
Pinpoint-Agent:和自己运行的应用关联起来的探针
-
Pinpoint-Web:将收集到的数据显示成WEB网页形式
- HBase Storage:收集到的数据存到HBase中
Pinpoint搭建
我们这里直接将数据存储到HDFS中,所以整体规划如下: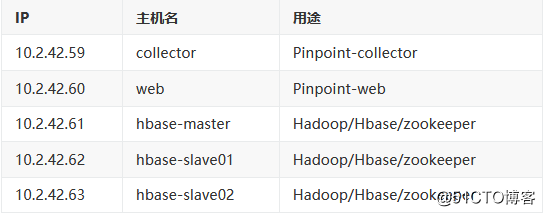
软件版本: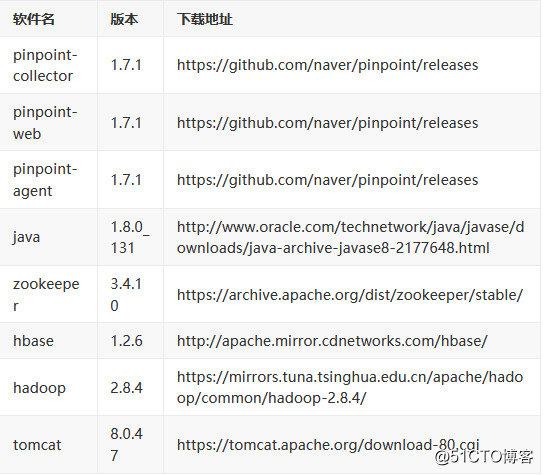
安装JDK
解压JDK到opt目录下,配置环境变量
tar xf jdk-8u131-linux-x64.tar.gz -C /optvim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH加载环境变量
source /etc/profile配置免密
配置10.2.42.61,10.2.42.62,10.2.42.63节点之间互信,可以三台同时操作。
ssh-keygen
ssh-copy-id 10.2.42.61
ssh-copy-id 10.2.42.62
ssh-copy-id 10.2.42.63如果没有ssh-copy-id,则使用下面命令安装即可
yum -y install openssh-clients配置Hosts映射
五台都需要配置hosts映射。
vim /etc/hosts
10.2.42.61 DCA-APP-COM-pinpoint-HBaseMaster
10.2.42.62 DCA-APP-COM-pinpoint-HBaseSlave01
10.2.42.63 DCA-APP-COM-pinpoint-HBaseSlave02安装zookeeper集群
解压安装包到opt目录下,三台可以同时操作。
tar xf zookeeper-3.4.10.tar.gz -C /opt/
cd /opt/zookeeper-3.4.10/conf
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=10.2.42.61:12888:13888
server.2=10.2.42.62:12888:13888
server.3=10.2.42.63:12888:13888创建数据目录
mkdir /data/zookeeper/data -p在10.2.42.61上添加竞选ID
echo 1 > /data/zookeeper/data/myid在10.2.42.62上添加竞选ID
echo 2 > /data/zookeeper/data/myid在10.2.42.63上添加竞选ID
echo 3 > /data/zookeeper/data/myid启动服务
/opt/zookeeper-3.4.10/bin/zkServer.sh start查看集群状态
[root@DCA-APP-COM-pinpoint-HBaseMaster data]# /opt/zookeeper-3.4.10/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower安装Hadoop集群

解压安装文件到opt目录下,注:没做特别说明,下面操作均在三台机器上同时操作。
tar xf hadoop-2.8.3.tar.gz -C /opt/进入hadoop配置文件目录,进行配置
cd /opt/hadoop-2.8.3/etc/hadoop配置hadoop-env.sh,指定hadoop的java运行环境
vim hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME} # 默认就是这个,所以实际上这一步可以跳过
export JAVA_HOME=/opt/jdk1.8.0_131配置core-site.xml,指定访问hadoop web界面访问
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.2.42.61:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>配置hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>10.2.42.61:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定namenode数据存放临时目录,自行创建 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/name</value>
</property>
<!-- 指定datanode数据存放临时目录,自行创建 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/data</value>
</property>
</configuration>配置mapred-site.xml,这是mapreduce的任务配置,可以查看以运行完的作业情况。
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>配置yarn-site.xml,datanode不需要修改这个配置文件。
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>10.2.42.61:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>10.2.42.61:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>10.2.42.61:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>10.2.42.61:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>10.2.42.61:8088</value>
</property>
</configuration>配置datanode,方便namenode调用
vim slaves
10.2.42.62
10.2.42.63创建数据目录
mkdir /data/hadoop/tmp -p
mkdir /data/hadoop/dfs/name -p
mkdir /data/hadoop/dfs/data -p格式化namenode,由于namenode
上的文件系统是 HDFS 的,所以要格式化。
/opt/hadoop-2.8.3/bin/hdfs namenode -format如下表示格式化成功。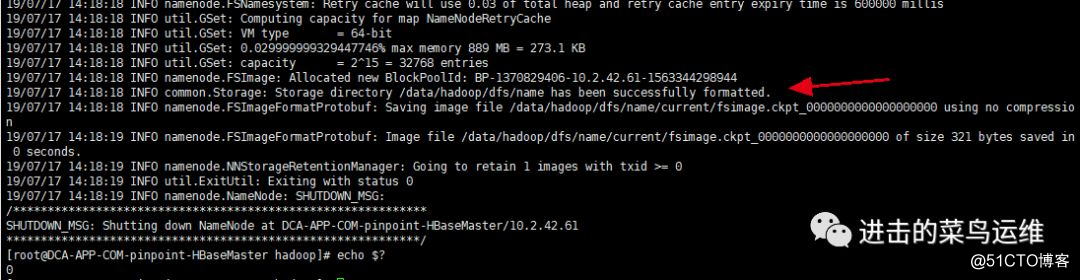
启动集群
/opt/hadoop-2.8.3/sbin/start-all.sh输出日志如下:
启动jobhistory 服务,查看 mapreduce 运行状态
/opt/hadoop-2.8.3/sbin/mr-jobhistory-daemon.sh start historyserver通过URL访问的地址
http://10.2.42.61:50070 #整个hadoop 集群
http://10.2.42.61:50090 #SecondaryNameNode的情况
http://10.2.42.61:8088 #resourcemanager的情况
http://10.2.42.61:19888 #historyserver(MapReduce历史运行情况)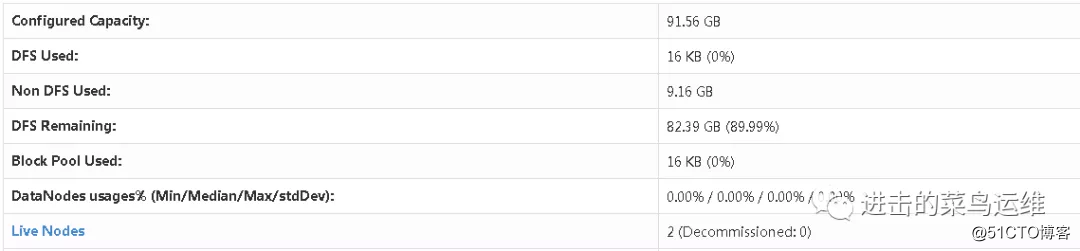
配置HBase集群
注:未做特别声明,一下操作在三个节点同时进行。
**
解压安装包到opt目录下
tar xf hbase-1.2.6-bin.tar.gz -C /opt/复制hdfs配置文件,这是为了保障hbase和hdfs两边的配置文件一致
cp /opt/hadoop-2.8.3/etc/hadoop/hdfs-site.xml /opt/hbase-1.2.6/conf/配置HBase配置文件
vim hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>10.2.42.61,10.2.42.62,10.2.42.63</value>
<description>The directory shared by RegionServers.</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/zookeeper/zkdata</value>
<description>
注意这里的zookeeper数据目录与hadoop ha的共用,也即要与 zoo.cfg 中配置的一致
Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://10.2.42.61:9000/hbase</value>
<description>The directory shared by RegionServers.
官网多次强调这个目录不要预先创建,hbase会自行创建,否则会做迁移操作,引发错误
至于端口,有些是8020,有些是9000,看 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 里面的配置,本实验配置的是
dfs.namenode.rpc-address.hdcluster.nn1 , dfs.namenode.rpc-address.hdcluster.nn2
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>tre</value>
<description>分布式集群配置,这里要设置为true,如果是单节点的,则设置为false
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description>
</property>
</configuration>配置regionservers文件
vim regionservers
10.2.42.62
10.2.42.63配置hbase-env.sh,由于我们是自己搭建的zookeeper,所以需要加入下面一段代码。
export HBASE_MANAGES_ZK=false启动集群
/opt/hbase-1.2.6/bin/start-hbase.sh
查看集群状态
1、通过URL查看:http://10.2.42.61:16010/master-status
2、通过命令行查看
/opt/hbase-1.2.6/bin/hbase shell
hbase(main):002:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load如果报错:ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
1、先停止HBase:/opt/hbase-1.2.6/bin/stop-hbase.sh
2、启动regionserver:/opt/hbase-1.2.6/bin/hbase-daemon.sh start regionserver
3、启动master:/opt/hbase-1.2.6/bin/hbase-daemon.sh start master
初始化HBase的PinPoint库,hbase-create.hbase是需要下载的。
地址是:https://github.com/naver/pinpoint/tree/master/hbase/scripts
/opt/hbase-1.2.6/bin/hbase shell /root/install/hbase-create.hbase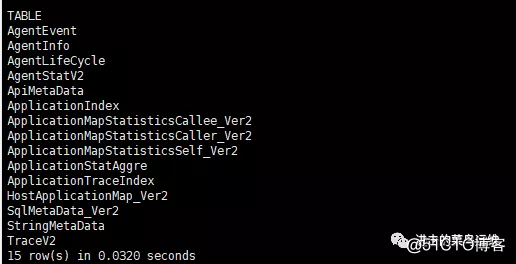
配置PinPoint-Collecter
解压war包到tomcat的webapps目录下
unzip pinpoint-collector-1.7.1.war -d /home/tomcat/apache-tomcat-8.0.47/webapps/ROOT配置文件目录/home/tomcat/apache-tomcat-8.0.47/webapps/ROOT/WEB-INF/classes
修改配置文件hbase.properties
hbase.client.host=10.2.42.61,10.2.42.62,10.2.42.63
hbase.client.port=2181
......修改配置文件pinpoint-collector.properties
cluster.enable=true
cluster.zookeeper.address=10.2.42.61,10.2.42.62,10.2.42.63
......
flink.cluster.zookeeper.address=10.2.42.61,10.2.42.62,10.2.42.63
flink.cluster.zookeeper.sessiontimeout=3000启动tomcat
/home/tomcat/apache-tomcat-8.0.47/bin/startup.sh配置PinPoint-WEB
解压对应的war包到tomcat的webapps目录
unzip pinpoint-web-1.7.1.war -d /home/tomcat/apache-tomcat-8.0.47/webapps/ROOT配置文件目录/home/tomcat/apache-tomcat-8.0.47/webapps/ROOT/WEB-INF/classes
vim hbase.properties
hbase.client.host=10.2.42.61,10.2.42.62,10.2.42.63
hbase.client.port=2181
......vim pinpoint-web.properties
cluster.enable=true
cluster.web.tcp.port=9997
cluster.zookeeper.address=10.2.42.61,10.2.42.62,10.2.42.63
cluster.zookeeper.sessiontimeout=30000
cluster.zookeeper.retry.interval=60000
.......启动tomcat
/home/tomcat/apache-tomcat-8.0.47/bin/startup.sh访问URL:http://10.2.42.60:8080/#/main
配置探针
复制pinpoint-agent-1.7.1.tar.gz到应用服务器上,解压到tomcat目录
tar xf pinpoint-agent-1.7.1.tar.gz -C /home/tomcat修改配置文件:
vim /home/tomcat/ppagent/pinpoint.config
# ip为pinpoint-collecter的服务器ip
profiler.collector.ip=10.2.42.59配置tomcat的Catalina.sh启动脚本,在脚本中加入如下代码
CATALINA_OPTS="$CATALINA_OPTS -javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=$AGENT_ID"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=$APPLICATION_NAME"如果是jar包,直接用Java启动,需要跟下面参数
java -javaagent:/home/tomcat/tmp/ppagent/pinpoint-bootstrap-1.7.1.jar -Dpinpoint.agentId=jss-spring-boot-app11201 -Dpinpoint.applicationName=jss-spring-boot-app -jar jssSpringBootDemo-0.0.1-SNAPSHOT.jar配置完后重启tomcat,然后在WEB端查看如下: