作者:
张驰 | 15 Dec 2018 | 23 min (6253 words)
有赞全链路压测实战

前言
有赞致力于成为商家服务领域里最被信任的引领者,因为被信任,所有我们更需要为商家保驾护航,保障系统的稳定性。有赞从去年开始通过全链路压测,模拟大促真实流量,串联线上全部系统,让核心系统同时达到流量峰值:
- 验证大促峰值流量下系统稳定性
- 容量规划
- 进行强弱依赖的划分
- 降级、报警、容灾、限流等演练
- ...
通过全链路压测这一手段,对线上系统进行最真实的大促演练,获取系统在大压力时的表现情况,进而准确评估线上整个系统集群的性能和容量水平,不辜负百万商家的信任。
有赞对于性能测试主要有线下单系统单接口、线上单系统以及线上全链路压测等手段,通过不同维度和颗粒度对接口、系统、集群层面进行性能测试,最终保障系统的稳定性。这里主要讲述一下,有赞全链路压测的相关设计和具体的实施。
整体设计
说到全链路压测,业内的淘宝、京东都都已有很成熟的技术,主要就是压测流量的制造、压测数据的构造、压测流量的识别以及压测数据流向的处理;直接看下有赞压测的整体设计:
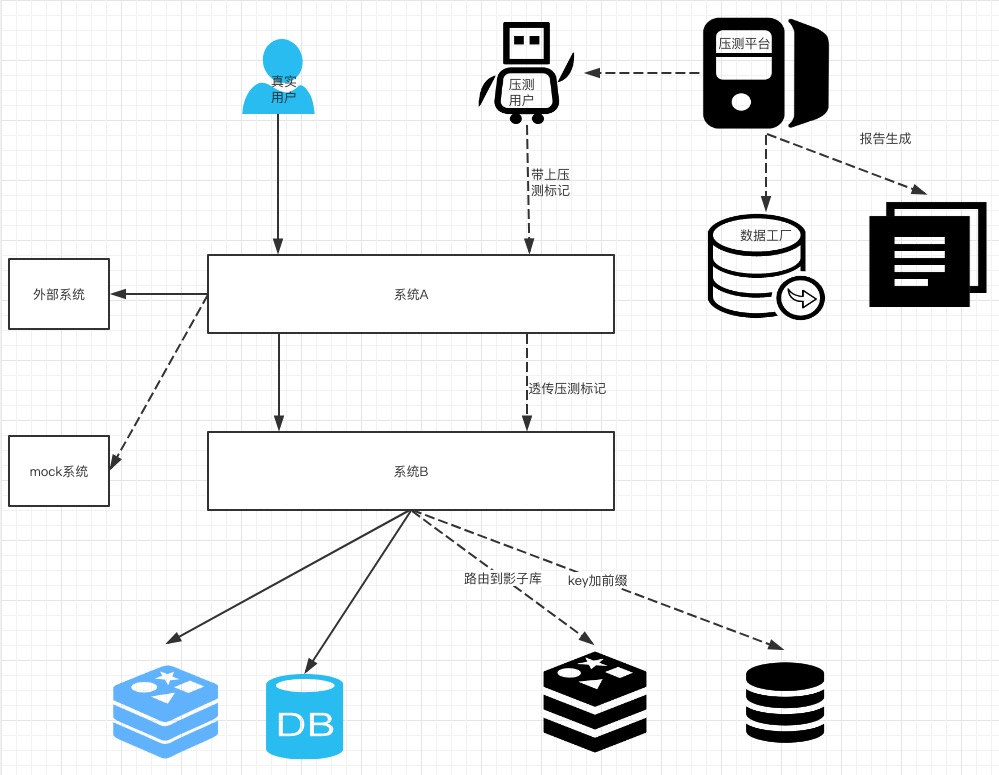
- 大流量下发器:其实就是模拟海量的用户去使用我们的系统,提供压测的流量,产生大促时的场景和流量;
- 数据工厂:构造压测链路中用户请求的数据,以及压测铺底的数据、数据清洗、脱敏等工作;
压测平台负责管理压测脚本和压测请求数据,从数据工厂获取压测数据集,分发到每一个压测 agent 机器上,agent 根据压测脚本和压力目标对线上机器发起请求流量,模拟用户的查看商品-添加购物车-下单-支付等行为,线上服务集群识别出压测的流量,对于存储的读写走影子存储。这里就要说到,线上压测很重要的一点就是不能污染线上的数据,不能让买卖家有感知,比如压测后,卖家发现多了好多订单,买家发现钱少了。所以,线上服务需要能够隔离出压测的流量,存储也需要识别出压测的数据,下面看一下有赞的压测流量和压测数据存储的隔离方案。
流量识别
要想压测的流量和数据不影响线上真实的生产数据,就需要线上的集群能识别出压测的流量,只要能识别出压测请求的流量,那么流量触发的读写操作就很好统一去做隔离了,先看一下有赞压测流量的识别:
3.1 同步请求
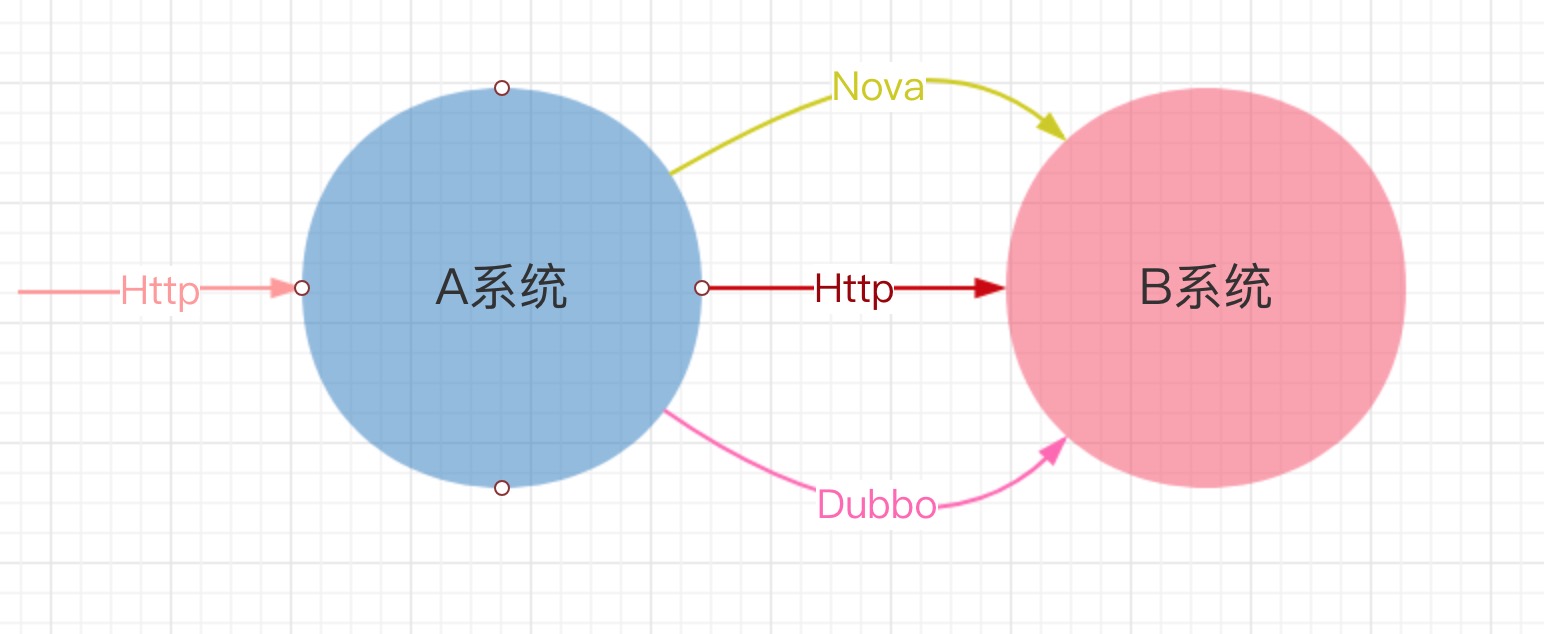
全链路压测发起的都是Http的请求,只需要要请求头上添加统一的压测请求头,具体表现形式为: Header Name:X-Service-Chain;
Header Value:{"zan_test": true}
Dubbo协议的服务调用,通过隐式参数在服务消费方和提供方进行参数的隐式传递,表现形式为:
Attachments:X-Service-Chain;
Attachments Value:{"zan_test": true}
通过在请求协议中添加压测请求的标识,在不同服务的相互调用时,一路透传下去,这样每一个服务都能识别出压测的请求流量,这样做的好处是与业务完全的解耦,只需要应用框架进行感知,对业务方代码无侵入
3.2 中间件
NSQ:通过 NSQMessage 中添加 jsonExtHeader 的 KV 拓展信息,让消息可以从 Producer 透传到 Consumer 端,具体表现形式为:Key:zan_test;Value:true
Wagon:对来自影子库的 binlog 通过拓展消息命令(PUBEXT)带上压测标记{"zantest": true}
3.3 异步线程
异步调用标识透传问题,可以自行定制 Runnable 或者定制线程池再或者业务方自行定制实现。
四、数据隔离
通过流量识别的改造,各个服务都已经能够识别出压测的请求流量了,那么如何做到压测数据不污染线上数据,对于不同的存储做到压测数据和真实的隔离呢,有赞主要有客户端 Client 和 Proxy 访问代理的方式实现,下面就看一下有赞的数据隔离方案:
4.1 Proxy 访问代理隔离
针对业务方和数据存储服务间已有Proxy代理的情况,可以直接升级 Proxy 层,存储使用方完全无感知,无侵入,下面以 MySQL 为例,说明 Proxy 访问代理对于压测数据隔离的方案;
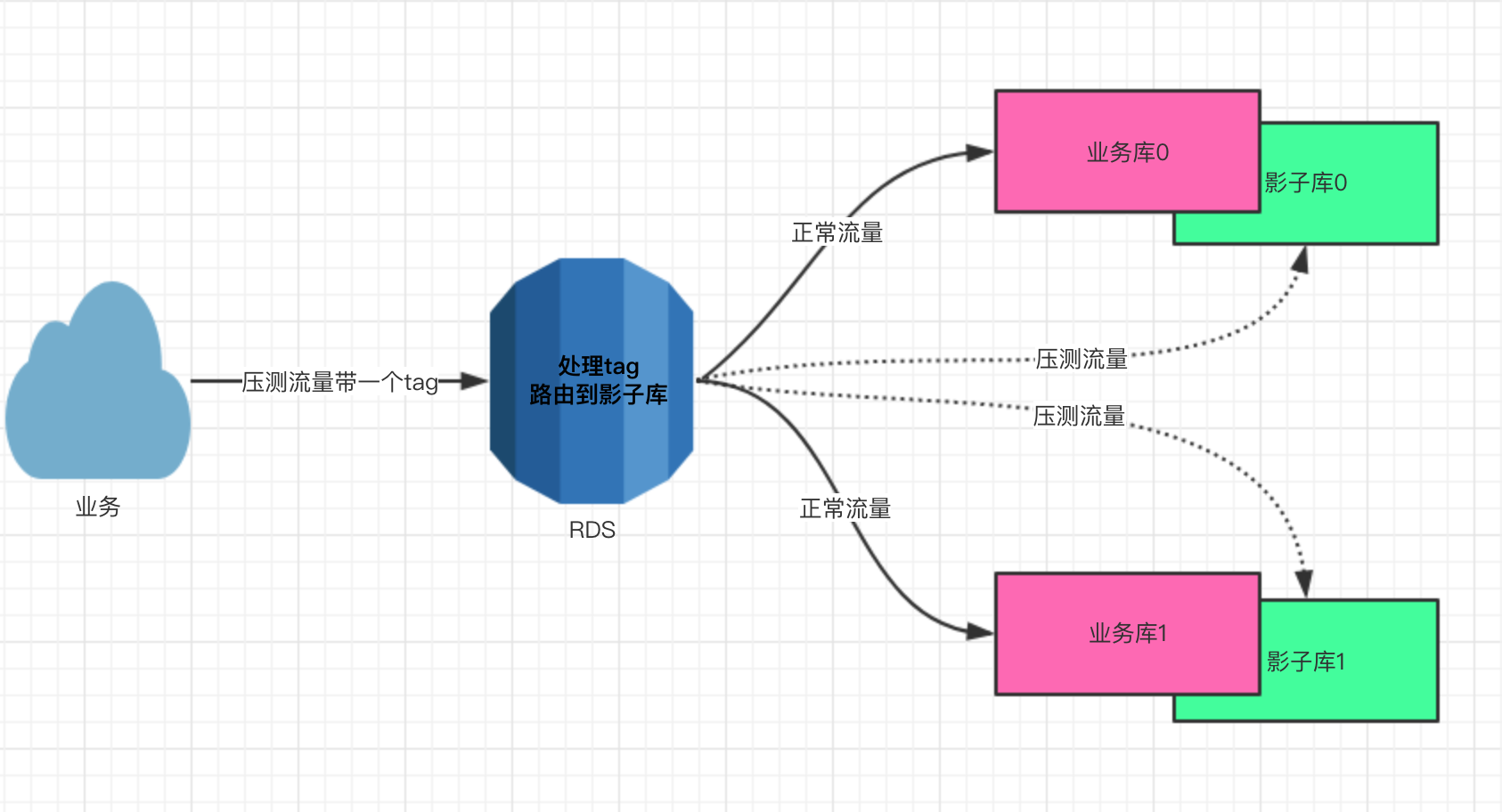
业务方应用读写DB时,统一与 RDS-Proxy (介于 MySQL 服务器与 MySQLClient 之间的中间件)交互,调用 RDS-Proxy 时会透传压测的标记,RDS 识别出压测请求后,读写 DB 表时,自动替换成对应的影子表,达到压测数据和真实的生产数据隔离的目的
ElasticSearch、KV 对于压测的支持也是通过 Proxy 访问代理的方式实现的
4.2 客户端SDK隔离
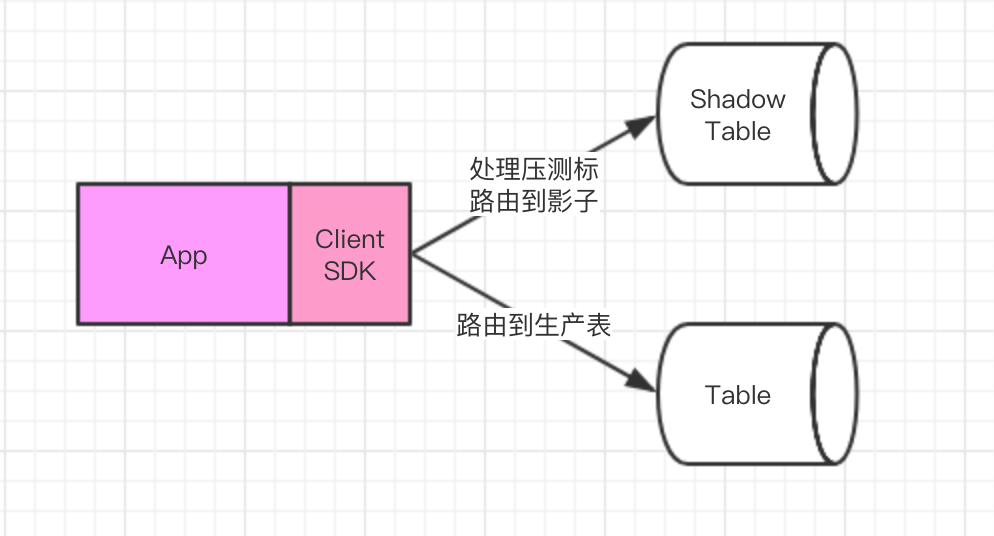
业务应用通过Client调用存储服务时,Client 会识别出压测的流量,将需要读写的 Table 自动替换为影子表,这样就可以达到影子流量,读写到影子存储的目的;
Hbase、Redis 等采用此方案实现
4.3 数据偏移隔离
推动框架、中间件升级、业务方改造,难免会有遗漏之处,所以有赞对于压测的数据统一做了偏移,确保买卖家 ID 与线上已有数据隔离开,这样即使压测数据由于某种原因写入了真实的生产库,也不会影响到线上买卖家相关的数据,让用户无感知;
这里要说一下特殊的周期扫表应用的改造,周期性扫表应用由于没有外部触发,所有无法扫描影子表的数据,如何让这样的 job 集群整体来看既扫描生产库,也扫描影子库呢? 有赞的解决思路是,部署一些新的 job 实例,它们只扫描影子库,消息处理逻辑不变;老的 job 实例保持不变(只扫生产库)
五、压测平台
有赞的全链路压测平台目前主要负责压测脚本管理、压测数据集管理、压测 job 管理和调度等,后续会有重点介绍,这里不做深入
压测的“硬件”设施基本已经齐全,下面介绍一下有赞全链路压测的具体实施流程吧
六、压测实施流程
废话不多说,直接上图:
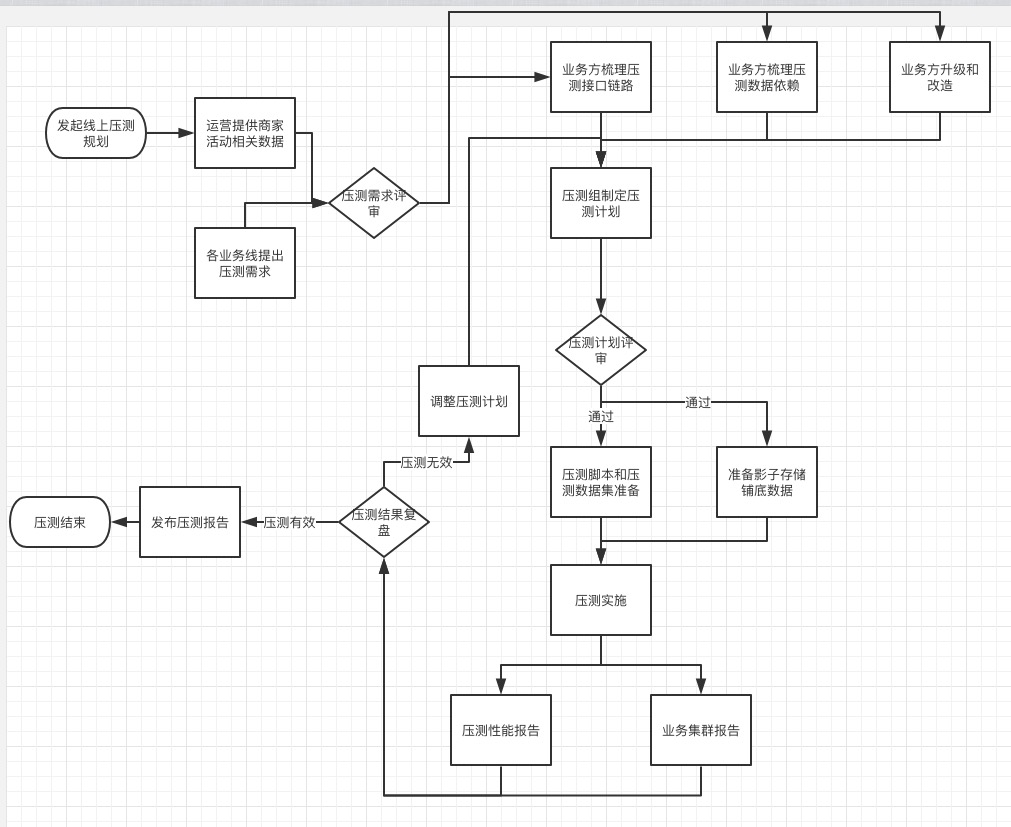
有赞全链路压测的执行流程如上图所示,下面具体看一下几个核心步骤在有赞是怎么做的。
6.1 压测计划制定
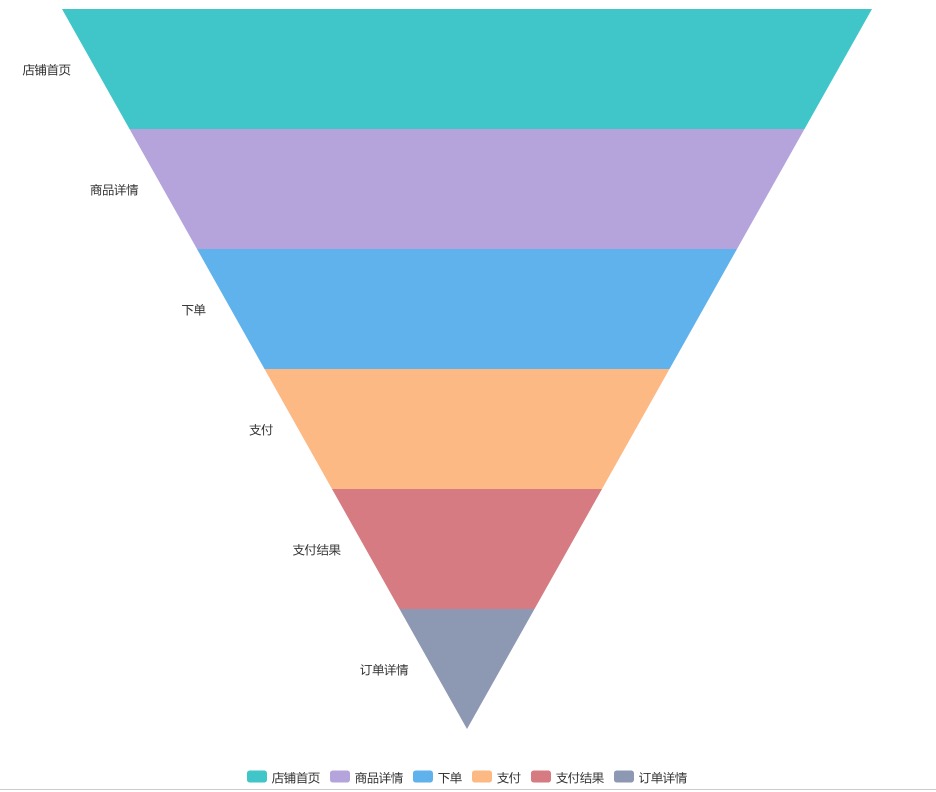
要想模拟大促时线上真实的流量情况,首先需要确认的就是压测场景、链路,压测的目录,以及压测的流量漏斗模型:
-
压测的链路:根据公司具体业务具体分析,有赞属于电商类型公司,大促时候的峰值流量基本都是由于买家的购买行为导致的,从宏观上看,这样的购买行为主要是店铺首页-商品详情页-下单-支付-支付成功,我们把这一条骨干的链路称为核心链路,其实大促时主要就是保证核心链路的稳定性
-
压测链路的漏斗模型:线上真实的场景案例是,100个人进入了商家的店铺首页,可能有50个人直接退出了,有50个人最终点击进入了商品详情页面,最终只有10个人下了单,5个人真正付款了,这就是压测链路的漏斗模型,也就是不同的接口的真实调用比例;实际的模型制定会根据近7天线上真实用户的行为数据分型分析建模,以及往期同类型活动线上的流量分布情况,构建压测链路的漏斗模型
- 压测的场景:根据运营报备的商家大促活动的计划,制定大促的压测场景(比如秒杀、抽奖等),再结合近七天线上流量的场景情况,综合确定压测的场景;
压测目标:根据运营报备的商家大促预估的PV和转换率情况,结合去年同期线上流量情况和公司业务的增长速率,取大值作为压测的目标
6.2 数据工厂
前面我们已经介绍了如何确定压测的目标、场景、链路,那么压测的数据怎么来尼,这就是数据工厂登场的时候了,下面就介绍一下有赞压测的数据工厂
有赞的压测数据工厂主要负责,压测铺底数据的准备、压测请求数据块的生成;
6.3 铺底数据准备
压测准备铺底的数据,这个众所周知的,但是由于有赞压测的方案采用的是影子库的设计,所以对于铺底数据准备不得不去处理影子库的数据。直接看下铺底数据准备的流程图:
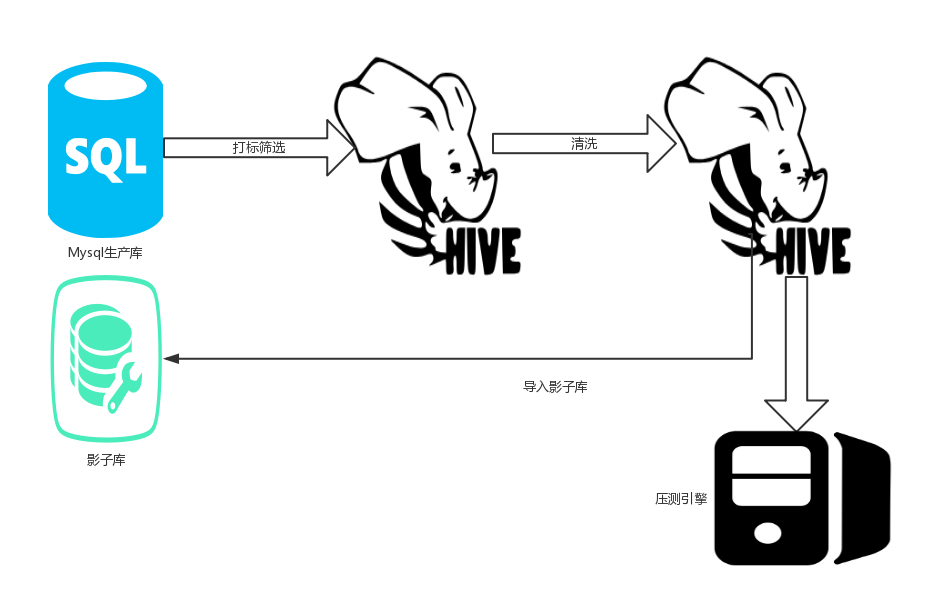
数据导入 从生产数据库按需过滤,导入压测铺底需要的数据到大数据集群的hive表中。
- 数据处理 在 hive 表中,对导入的数据进行脱敏和清洗,清洗的目的是保证压测的数据可用性,比如保证铺底商品库存最大、营销活动时间无限、店铺正常营业等。 - 数据导出 对 hive 标中已经处理完成的数据,导出到已经创建好的影子库中,需要注意的是同一实例写入数据的控制(因为影子库和生产库同实例),写入数据的 binlog 过滤。
有赞的压测数据准备目前全部在 DP 大数据平台上操作,基本完成了数据准备操作的自动化,维护了近千的数据准备 job
压测请求数据数据集
gatling 原生支持 json、csv、DB 等方式的数据源载入,我们采用的压测数据源是 json 格式的,那么如此海量的压测源数据,是通过什么方式生成和存储的尼,我们的实现还是依托于 DP 大数据平台,通过 MapReduce 任务的方式,按需生成我们压测请求需要的数据集:
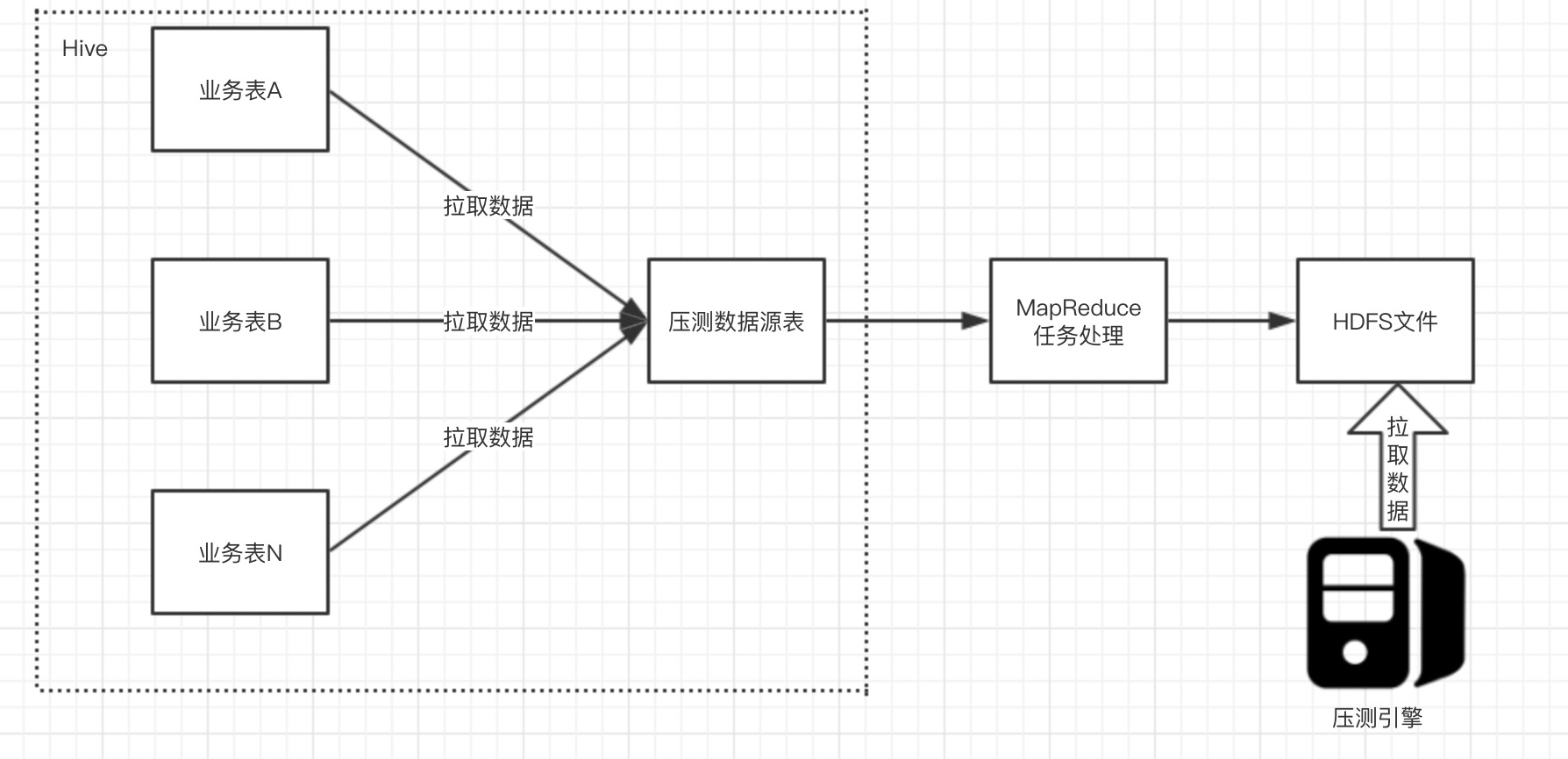
- 从各个业务线的表中获取压测场景整个链路所以接口请求需要的参数字段,存到一张创建好的压测数据源宽表中
- 编写 MapReduce 任务代码,读取压测数据源宽表数据,按压测的接口请求参数情况,生成目标 json 格式的压测请求数据块文件到 HDFS
- 压测时,压测引擎自动从 HDFS 上拉取压测的请求数据块
MapReduce 生成的数据集 json 示例:

6.4 压测脚本准备
6.4.1 梳理压测请求和参数
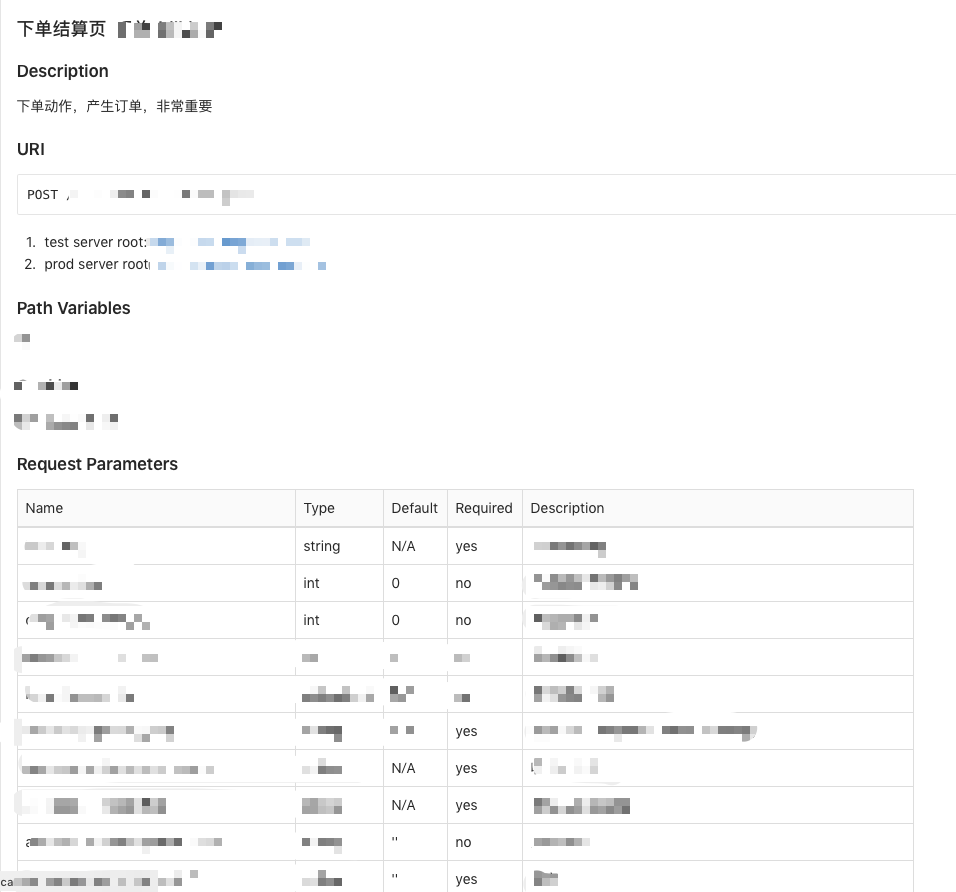
压测就要知道压测的具体接口和接口参数,所以我们采用统一的 RESTful 风格规范,让各个业务方的人员提交压测接口的 API 文档,这样压测脚本编写人员就能根据这份 API 快速写出压测的脚本,以及接口的预期结果等
6.4.2 控制漏斗转化率
有赞的压测引擎用的是公司二次封装的 gatling,原生就支持漏斗比例的控制,直接看例子
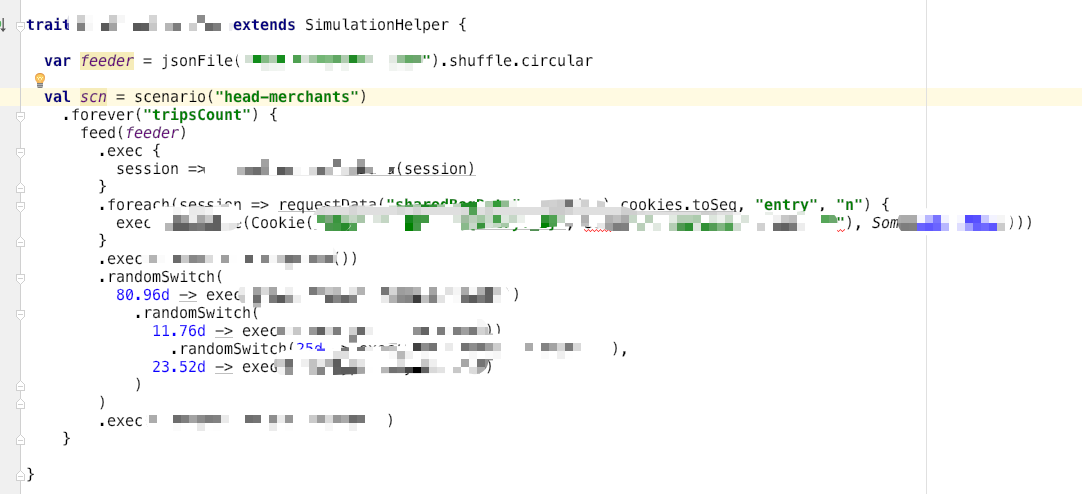
6.4.3 不同场景的配比
对不同的压测场景链路按模块编写压测脚本,这样的好处就是需要不同场景混合压测时,只需要在 setUp 时,按需把不同的场景组合到一起即可;需要单独压测某一个场景时,setUp 中只留一个场景就好,做到一次编写,处处可压。
6.5 压测执行
压测的铺底数据、压测脚本、压测请求的数据集都已经介绍完了,可谓是万事俱备只欠东风,那这个东风就是我们自建的压测平台 maxim,这里不对压测平台的设计展开介绍,展示一下 maxim 在压测执行过程中所承担的工作。

maxim平台主要的功能模块有:
-
测试脚本:负责测试脚本的管理
-
数据集:负责压测请求数据集的管理,目前主要有两种数据集上传模式:直接上传数据包和 hadoop 集群数据源路径上传。第二种上传模式,只需要填写数据源所在的 hadoop 集群的路径,maxim 平台会自动去所在路径获取压测数据集文件
-
测试 job:负责测试任务的管理,指定压测 job 的脚本和脚本入口,以及压测数据集等
-
压测注入器:负责展示压测注入机器的相关信息
-
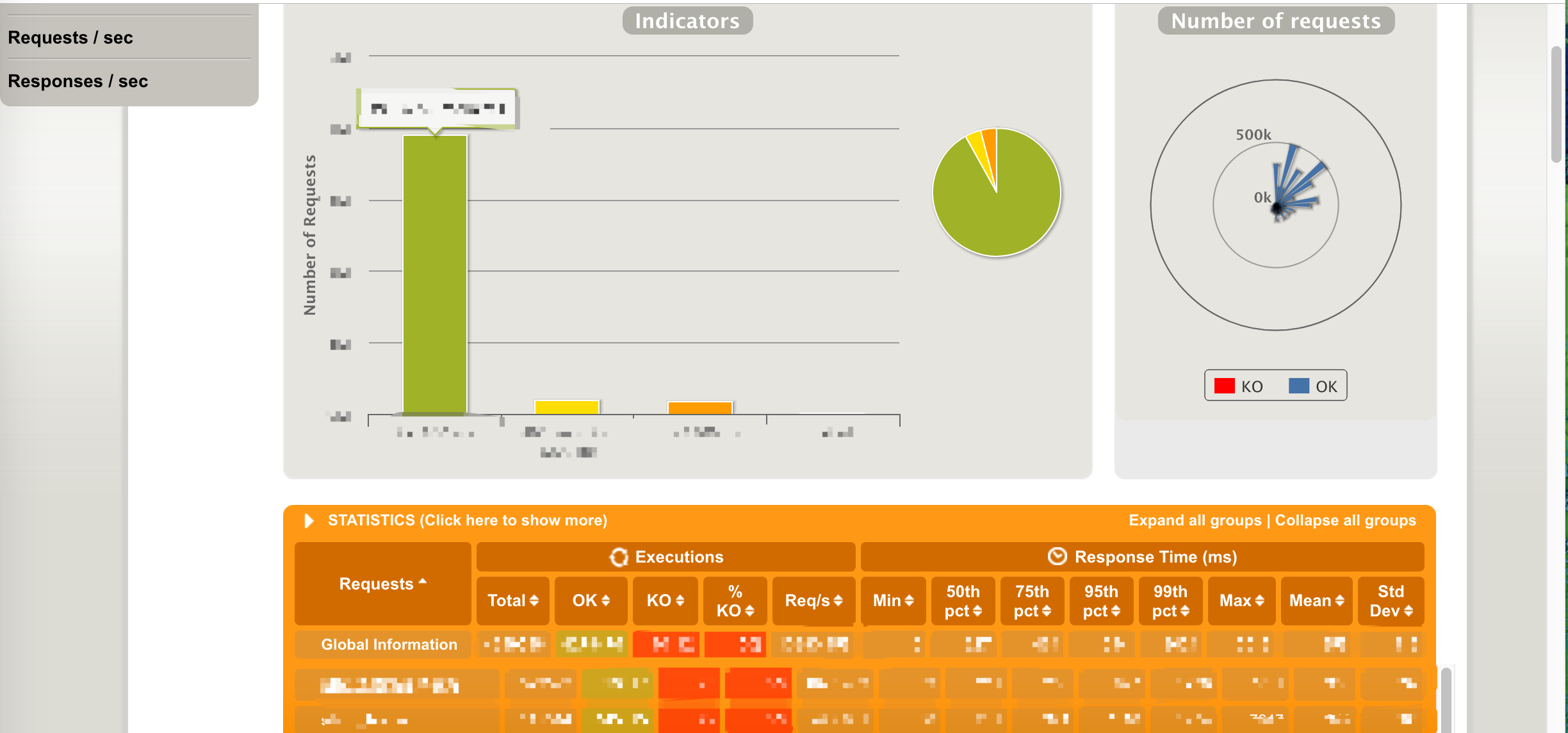
压测报告生成:压测报告的生成,直接用的 gatling 原生的报告生成功能
maxim 平台压测结果报告
下面看一下压测执行的页面功能:
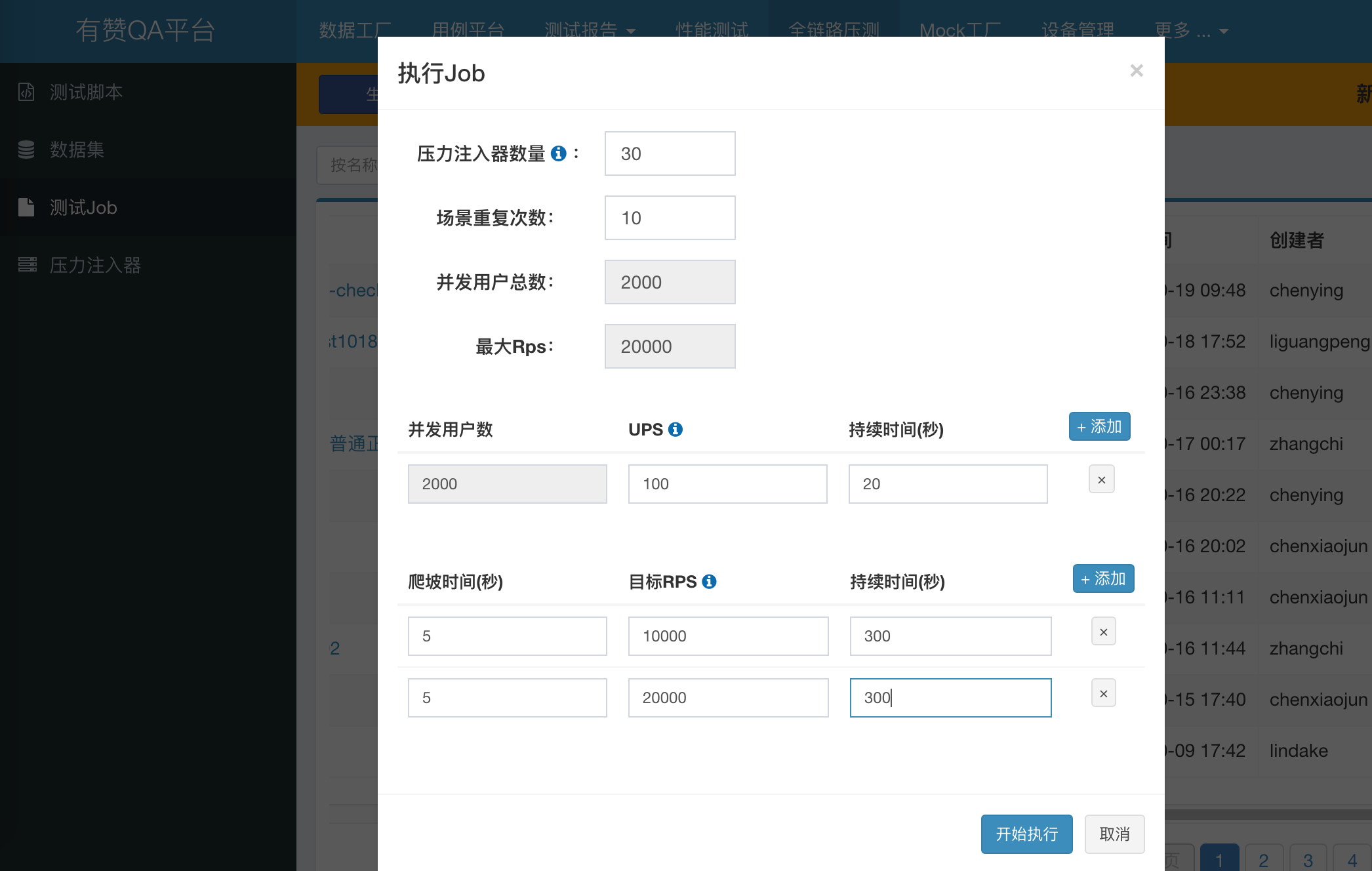
- 压力注入器数量:指定本次压测执行,需要多少台压测机去执行
- 重复场景测试:一个虚拟用户重复几次压测场景
- 并发用户数:可执行压测时,按需填写需要的每秒加载的并发用户数和持续时间,无需每次变更压测脚本
- 目标 RPS:可执行压测时,按需填写压测的目标 RPS,爬坡时间,目标持续时间,达到限流的作用,可同时指定多个目标 RPS,达到分梯度压测的目的;
七、最后
到这里有赞全链路压测方案已经介绍完了,因为篇幅的原因还有很多实施细节部分并没有完整表述,同时有赞的全链路压测也才初具雏形,欢迎有兴趣的同学联系我们一起探讨,有表述错误的地方也欢迎大家联系我们纠正。