但是
我们切割文件后,要怎么样无须再动手去完善呢?要知道一个大脚本切割下来可能有10份以上,完善每个脚本的开头和收尾,还要标记这是第几个脚本,是一件非常繁琐耗时的事情。所以,安老师绝对不允许这样的事情出现,老铁们也一样,对不对!如果能一次性切割完成,究竟能带来什么好处呢?
1)拿来主义,省事,切割完成,直接用。
2)可标记脚本个数,便于管理和安排计划。
3)降低人为编辑错误的可能性。
大纲
1. 切割程序演示
2. 使用re模块
3. "一劳永逸"切割
01
切割程序演示
1. 演示场景
本次默认Windows切割文件,演示的图片如下
1.1 原文件
文件路径 F:\python\py自动化运维\公众号\5 python切割文件\test.sql
文件首部(图一,总1416行,此sql脚本为数据库劈2016年的月分区。)
文件尾部(图二)
2 使用程序演示
使用程序将上节推文的sql文件进行切割,可以看到该程序需要输入的信息有以下内容:
1)输入文件的绝对路径
2)每个新文件所需的行数
3)文件内容首部添加的内容
4)文件尾部添加的内容
5)生成文件的路径
02
使用re模块
1 正则表达式
2 利用re库处理正则表达式
正则表达式虽然本身比较复杂,但是python使用re标准库来处理它时却非常简单。
2.1 re库演示
re模块包含了正则表达式相关的函数、标志和一个异常。若希望在re模块在匹配时忽略字符的大小写可以添加标志,flags=re.IGNORECASE
03
"一劳永逸"切割
1 高级切割代码
1# -*- coding: GB18030 -*-
2import re
3import os
4import time
5
6def splitByLineCount(qianzhuitext,houzhuitext,filenamepath, count):
7 global FILENAMELIST
8 FILENAMELIST=[]
9 filename = open(filenamepath, 'r')
10 try:
11 bufferline = []
12 num = 1
13 filename.seek(0)
14 for line in filename:
15 bufferline.append(line)
16 if len(bufferline) == count and num >=1 :
17 num = mkSubFile(qianzhuitext,houzhuitext,bufferline,filenamepath,num)
18 bufferline = []
19 if len(bufferline) != count and num >=1 :
20 num = mkSubFile(qianzhuitext,houzhuitext,bufferline,filenamepath,num)
21 finally:
22 filename.close()
23 return FILENAMELIST
24
25def mkSubFile(qianzhuitext,houzhuitext,bufferline,filenamepath,num):
26 [desfilename, typename] = os.path.splitext(filenamepath)
27 nfilename = desfilename + '_' + str(num) + typename
28 print('make file: %s' % nfilename)
29 scriptfile = open(nfilename, 'w')
30 try:
31 qianzhuitextnew = getnewqianzhui(qianzhuitext,num)
32 scriptfile.writelines(qianzhuitextnew)
33 scriptfile.writelines(bufferline)
34 scriptfile.writelines(houzhuitext)
35 return num + 1
36 finally:
37 scriptfile.close()
38 FILENAMELIST.append(nfilename)
39
40def getnewqianzhui(qianzhuitext,num):
41 global qianzhuitextnew
42 qianzhuitextnew=[]
43 f = open(r'F:\python\py自动化运维\公众号\5 python切割文件\qianzhui.txt',"w")
44 f.write(qianzhuitext)
45 f.close()
46 try:
47 fr = open(r'F:\python\py自动化运维\公众号\5 python切割文件\qianzhui.txt',"r")
48 for each in fr:
49 result = re.search(r"\.(log|sql|sh|py)",each.strip())
50 if result is not None:
51 neweach = each.replace(result.group(),"_"+str(num)+result.group())
52 qianzhuitextnew.append(neweach)
53 else:
54 neweach = each.strip() + '\n'
55 qianzhuitextnew.append(neweach)
56 fr.close()
57 return qianzhuitextnew
58
59 except Exception as e:
60 print('原因:', e)
61
62
63if __name__ == '__main__':
64 begin = time.time()
65 filenamepath = r'F:\python\py自动化运维\公众号\5 python切割文件\test.sql'
66 qianzhuitext= 'vi p_test_pmax_20190314.sh \n '\
67 'sqlplus "/ as sysdba" << EOF \n '\
68 'spool p_test_pmax_20190314.log \n '\
69 'set time on \n'\
70 'set timing on \n'\
71 'set echo on\n \n'
72 houzhuitext = '\n<< EOF \n'\
73 'exit \n'\
74 '! \n '
75 splitByLineCount(qianzhuitext,houzhuitext,filenamepath, 500)
76 end = time.time()
77 print('time is %d seconds ' % (end - begin))1.1 重点代码详解
1)执行流
qianzhuitext 每个新文件首部添加的内容
houzhuitext 每个新文件尾部添加的内容
2)第6行 splitByLineCount函数 内容详解请查看上节推文[阅读原文]
3)第25行 mkSubFile函数 内容详解请查看上节推文[阅读原文]
4)第32-34行 主要思路,在新文件内容的基础上添加前文和后文。
5)第40行 getnewqianzhui函数 需要用到qianzhuitext内容和num这两个参数,是因为要重命名脚本文件名,以及spool 新生成的log日志,这两个需要特别标记,有利于我们检查和管理。
6)第43行 打开文件记录首部内容,而不是直接使用数组,是因为首部内容可能会比较复杂,程序里首部是一个text框,text框输入什么内容,我们就应该让text框内容完全显示出来。
7)第49行 re.search(r"\.(log|sql|sh|py)",each.strip()),re.search仅仅查找匹配一次,匹配成功返回SRE_Match对象,如果匹配失败则返回None。
8)第50-52行 以"log|sql|sh|py"进行匹配。若匹配成功,则进行replace,如“.sh”被替换成“_1.sh”,并添加到新的qianzhuitextnew数组;若匹配不成功,则将该行直接写入新的qianzhuitextnew数组。
9)第59行 自定义抛出异常。
1.2 高级切割文件优缺点
优点:输入内容,“一劳永逸”。
缺点:代码还不够精简(欢迎老铁们留言完善)。
1.3 执行演示

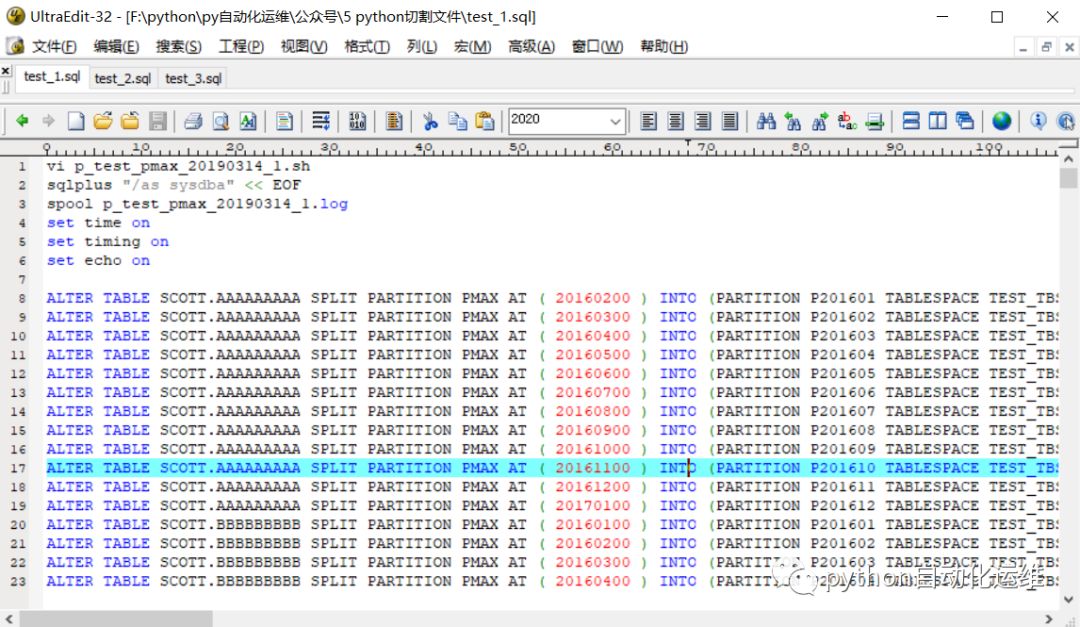
第一个脚本test_1.sql和原文件的开头一样,而且包含输入的内容,文件名和log均标记了这是第一个脚本,这是成功切割的第一步。
第一个脚本test_1.sql的尾部,添加的尾部内容正确。如此类推,test_2.sql和test_3.sql也是没有问题的。

第三个脚本test_3.sql文件的sql语句只有416行,并且包含尾部内容。整个切割过程,数据和行数并没有丢失,完美实现了一次切割,无须补刀!

总结
其实本文"一劳永逸"切割代码,已经是第三个版本了!第一个版本全部使用if判断,第二个版本增加replace函数,第三个版本改用re正则表达式。安老师觉得本文代码还有改进之处。比如,replace函数可以换成re.sub;尽量少使用全局变量等等。
定期迭代产品,可温故而知新。安老师也鼓励老铁们不妨写些坏代码,因为我们编写软件就是为了解决问题,如果编写的代码没有解决问题,一味遵循"好代码"规则,反而会作茧自缚!安老师认为,我们会进步,产品会更新,自己写出程序,实现功能,定期迭代,才是python入门的正确方式!