在大型项目中,经常需要执行数据库脚本,有些脚本特别大。如几十兆的sql文件,盲目地执行可能会导致很多的问题。如:
1)进度不可控,时间难把握。
2)脚本中间出现差错,导致后续报错,甚至跑错语句。
3)有重启工程,意外宕机,就会中断执行任务。
4)不利于检查和完善。
如果能够将这么大sql文件进行切割,分成多个小任务,每天按照计划跑,以上问题基本可以得到解决。
大纲
1. 使用os.path模块和open模块
2. 切割文件演示
01
使用os.path模块和open模块
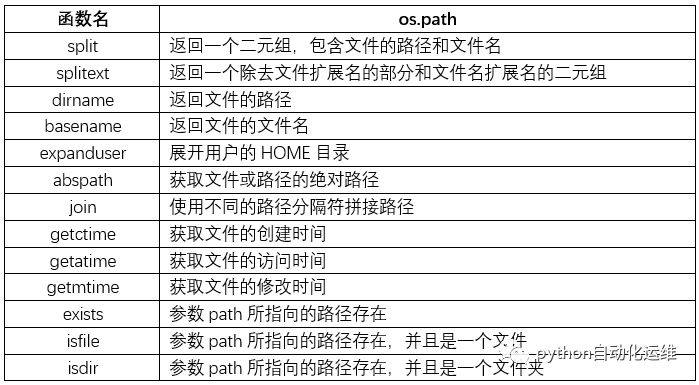
1. os.path模块
2. open模块

02
切割文件演示
1. 演示场景
本次默认Windows切割文件,演示的图片如下
1.1 原文件
文件路径 F:\python\py自动化运维\公众号\5 python切割文件\test.sql
文件首部(图一,总1416行,此sql脚本为数据库劈2016年的月分区。)
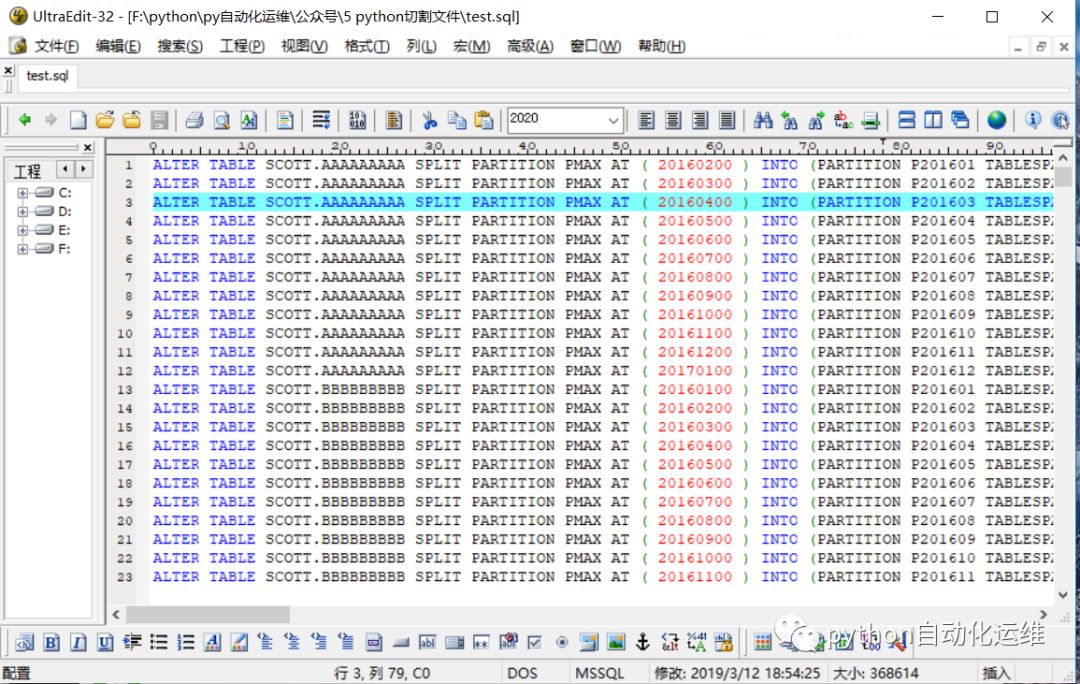
文件尾部(图二)
2. 切割文件代码
1import os
2import time
3
4def mkSubFile(bufferline, filenamepath, num):
5 [desfilename, typename] = os.path.splitext(filenamepath)
6 nfilename = desfilename + '_' + str(num) + typename
7 print('make file: %s' % nfilename)
8 scriptfile = open(nfilename, 'w')
9 try:
10 scriptfile.writelines(bufferline)
11 return num + 1
12 finally:
13 scriptfile.close()
14
15def splitByLineCount(filenamepath, count):
16 filename = open(filenamepath, 'r')
17 try:
18 bufferline = []
19 num = 1
20 filename.seek(0)
21 for line in filename:
22 bufferline.append(line)
23 if len(bufferline) == count and num >=1 :
24 num = mkSubFile(bufferline, filenamepath, num)
25 bufferline = []
26 if len(bufferline) != count and num >=1 :
27 num = mkSubFile(bufferline, filenamepath, num)
28 finally:
29 filename.close()
30
31if __name__ == '__main__':
32 begin = time.time()
33 filenamepath = r'F:\python\py自动化运维\公众号\5 python切割文件\test.sql'
34 splitByLineCount(filenamepath, 500)
35 end = time.time()
36 print('time is %d seconds ' % (end - begin))
2.1 重点代码详解
1)执行流
begin = time.time() 开始切割时间
filenamepath 需要被切割的文件路径
splitByLineCount(filenamepath, 500) 切割函数(被切割文件路径,满500行切割文件)
end = time.time() 结束切割时间
1)第5行 os.path.splitext 拆分原文件路径,得到文件名和扩展名
2)第6行 标记切割第几个文件
3)第8行 scriptfile = open(nfilename, 'w') 开始写入文件
4)第11行 return num + 1 返回num值,下次切割文件为num+1值
5)第18行 bufferline = [],新建数组,记录读取行数值
6)第19行 num = 1,第一个切割文件
7)第20行 filename.seek(0),确保指针在第一行的起始位置
8)第21行 for line in filename 读取文件的每一行
9)第22行 bufferline.append(line) bufferline数组添加读取的每一行数据
10)第23行 if len(bufferline) == count and num >=1,如果满足count值,就切割一个文件出来,并把bufferline数组清空,下次再重新开始记录
11)第24行 mkSubFile函数,满足count值,切割文件
12)第26 行 bufferline不满足count值,退出For循环,此时bufferline有存数据
13)第27行 mkSubFile函数,文件剩下的行数,不满足count值,切割文件
2.2 切割文件优缺点
优点:短时间内精准切割文件。
缺点:不能自动生成后台可执行脚本,需要手工"添油加醋",仍然需要大量时间。
2.3 执行演示
由图可见,原文件不到1s就被切割成3个文件,请老铁们放心,此时原文件还是存在的。根据安老师的实战经验,10万行的脚本,精准切割5000行,也不需要1分钟,是不是非常高效呢?

第一个脚本test_1.sql和原文件的开头一样,这是成功切割的第一步。
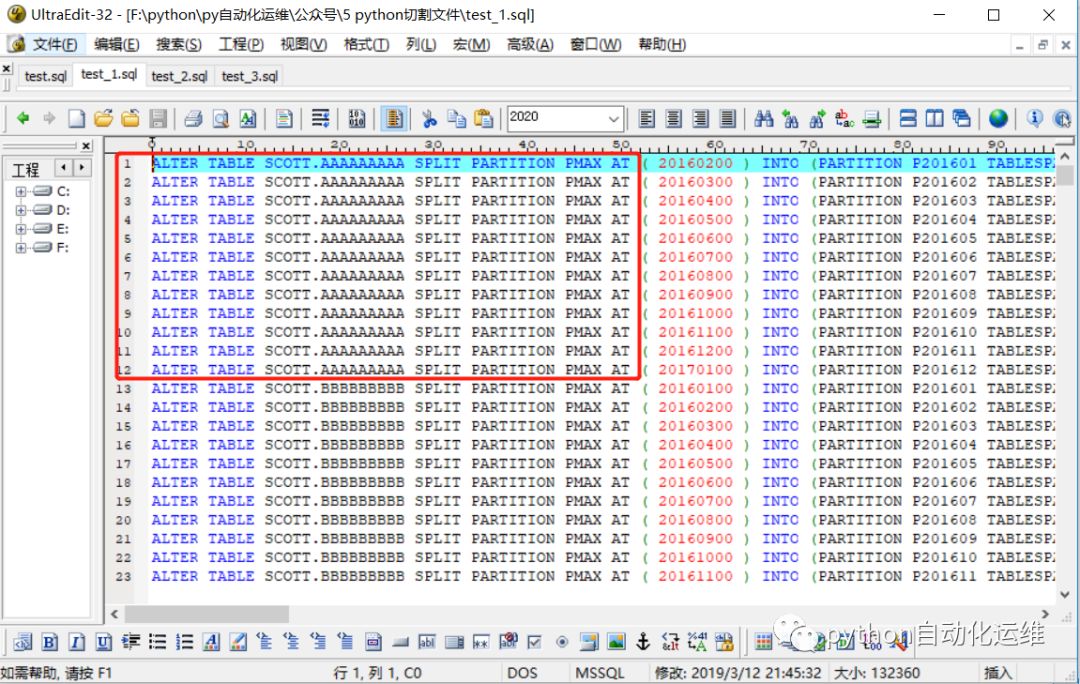
第一个脚本test_1.sql的尾部。
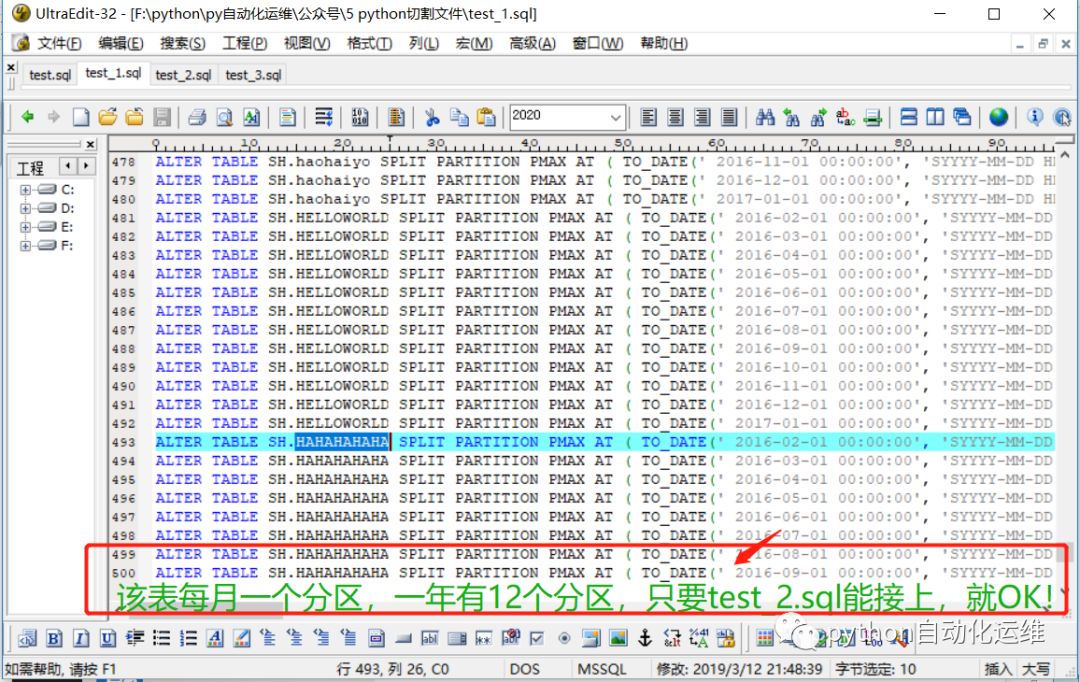
第二个脚本test_2.sql的文件内容首部成功衔接test_1.sql的尾部。

第三个脚本test_3.sql的文件行数只有416行,根据推算,这是正确的!整个切割过程,数据和行数并没有丢失,这很成功!

总结
python切割文件其实网上有很多的代码,安老师也是从网上找了一些资料,通过自己的实战经验,用了30行左右的代码实现了这个功能!如果老铁们有更简便的代码,欢迎讨论,非常期待。