1、 基本环境配置
1、Kubectl debug 设置一个临时容器
2、Sidecar
3、Volume:更改目录权限,fsGroup
4、ConfigMap和Secret
K8S官网:https://kubernetes.io/docs/setup/
最新版高可用安装:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
| 主机名 |
IP地址 |
说明 |
| k8s-master01 ~ 03 |
192.168.0.106 ~ 20 |
master节点 * 3 |
| k8s-master-lb |
192.168.0.200 |
keepalived虚拟IP |
| k8s-node01 ~ 02 |
192.168.0.108 ~ 22 |
worker节点 * 2 |
VIP(虚拟IP)不要和公司内网IP重复,首先去ping一下,不通才可用。VIP需要和主机在同一个局域网内!
所有节点配置hosts,修改/etc/hosts如下:
[root@k8s-master01 ~]# cat /etc/hosts
192.168.0.100 k8s-master01
192.168.0.106 k8s-master02
192.168.0.107 k8s-master03
192.168.0.200 k8s-master-lb
192.168.0.108 k8s-node01
192.168.0.109 k8s-node02
所有节点关闭防火墙、selinux、dnsmasq、swap。服务器配置如下
systemctl disable --now firewalld
systemctl disable --now dnsmasq
#systemctl disable --now NetworkManager #CentOS8无需关闭
setenforce 0
[root@k8s-master01 ~]# cat !$
cat /etc/sysconfig/selinux
SELINUX=disabled
swapoff -a && sysctl -w vm.swappiness=0
[root@k8s-master01 ~]# vi /etc/fstab
[root@k8s-master01 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Fri Nov 1 23:02:53 2019
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
/dev/mapper/cl-root / xfs defaults 0 0
UUID=6897cd7b-9b3a-42b0-a827-57991141b297 /boot ext4 defaults 1 2
#/dev/mapper/cl-swap swap swap defaults 0 0
安装ntpdate(CentOS 7 无需安装,自带ntpdate命令)
所有节点同步时间。时间同步配置如下:
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo 'Asia/Shanghai' >/etc/timezone
ntpdate time2.aliyun.com
# 加入到crontab
*/5 * * * * ntpdate time2.aliyun.com
# 加入到开机自动同步,/etc/rc.local
ntpdate time2.aliyun.com
所有节点配置limit:
ulimit -SHn 65535Master01节点免密钥登录其他节点,安装过程中生成配置文件和证书均在Master01上操作,集群管理也在Master01上操作,阿里云或者AWS上需要单独一台kubectl服务器。密钥配置如下:
ssh-keygen -t rsa
for i in k8s-master01 k8s-master02 k8s-master03 k8s-node01 k8s-node02;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
在源码中的repo目录配置使用的是国内仓库源,将其复制到所有节点:
git clone https://github.com/dotbalo/k8s-ha-install.git
2、CentOS 7安装yum源如下
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
所有节点升级系统并重启,此处升级没有升级内核,下节会单独升级内核:
yum install wget jq psmisc vim net-tools telnet yum-utils device-mapper-persistent-data lvm2 -y
yum update -y --exclude=kernel* && reboot #CentOS7需要升级,8不需要
3、内核配置
(如果内核达到,可以不用跳过此步骤)
CentOS7 需要升级内核至4.18+
使用如下方式安装最新版内核
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
查看最新版内核yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
[root@k8s-node01 ~]# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
安装最新版:
yum --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel –y
安装完成后reboot
更改内核顺序:
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg && grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)" && reboot
开机后查看内核
[appadmin@k8s-node01 ~]$ uname -a
Linux k8s-node01 5.7.7-1.el7.elrepo.x86_64 #1 SMP Wed Jul 1 11:53:16 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux

本所有节点安装ipvsadm:
yum install ipvsadm ipset sysstat conntrack libseccomp -y所有节点配置ipvs模块,在内核4.19+版本nf_conntrack_ipv4已经改为nf_conntrack,本例安装的内核为4.18,使用nf_conntrack_ipv4即可:
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
cat /etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
然后执行systemctl enable --now systemd-modules-load.service即可
检查是否加载:
[root@k8s-master01 ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
nf_conntrack_ipv4 16384 23
nf_defrag_ipv4 16384 1 nf_conntrack_ipv4
nf_conntrack 135168 10 xt_conntrack,nf_conntrack_ipv6,nf_conntrack_ipv4,nf_nat,nf_nat_ipv6,ipt_MASQUERADE,nf_nat_ipv4,xt_nat,nf_conntrack_netlink,ip_vs
开启一些k8s集群中必须的内核参数,所有节点配置k8s内核:
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
EOF
sysctl --system
所有节点配置完内核后,重启服务器,保证重启后内核依旧加载
reboot
lsmod | grep --color=auto -e ip_vs -e nf_conntrack
4、基本组件安装
本节主要安装的是集群中用到的各种组件,比如Docker-ce、Kubernetes各组件等。
4.1安装Docker组件
查看可用docker-ce版本:
yum list docker-ce.x86_64 --showduplicates | sort -r
[root@k8s-master01 k8s-ha-install]# wget https://download.docker.com/linux/centos/7/x86_64/edge/Packages/containerd.io-1.2.13-3.2.el7.x86_64.rpm
[root@k8s-master01 k8s-ha-install]# yum install containerd.io-1.2.13-3.2.el7.x86_64.rpm -y
安装指定版本的Docker:
yum -y install docker-ce-17.09.1.ce-1.el7.centos
安装最新版本的Docker
yum install docker-ce –y
[root@k8s-master01 ~]# docker -v
Docker version 19.03.13, build 4484c46d9d
温馨提示:
由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
4.2安装k8s组件:
yum list kubeadm.x86_64 --showduplicates | sort -r
所有节点安装最新版本kubeadm:
yum install kubeadm -y
所有节点安装指定版本k8s组件:
yum install -y kubeadm-1.18.5-0.x86_64 kubelet-1.18.5-0.x86_64 kubectl-1.18.5-0.x86_64
4.3启动Docker和Kubernetes
所有节点设置开机自启动Docker:
systemctl daemon-reload && systemctl enable --now docker
默认配置的pause镜像使用gcr.io仓库,国内可能无法访问,所以这里配置Kubelet使用阿里云的pause镜像:
cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=$DOCKER_CGROUPS --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.1"
EOF
设置Kubelet开机自启动:
systemctl daemon-reload
systemctl enable --now kubelet
5、高可用组件安装
5.1所有Master节点通过yum安装HAProxy和KeepAlived
yum install keepalived haproxy -y所有Master节点配置HAProxy(详细配置参考HAProxy文档,所有Master节点的HAProxy配置相同):
[root@k8s-master01 etc]# mkdir /etc/haproxy
[root@k8s-master01 etc]# vim /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-master01 192.168.0.100:6443 check
server k8s-master02 192.168.0.106:6443 check
server k8s-master03 192.168.0.107:6443 check
5.2Master01节点的配置:
[root@k8s-master01 etc]# mkdir /etc/keepalived
[root@k8s-master01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
mcast_src_ip 192.168.0.100
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.0.200
}
# track_script {
# chk_apiserver
# }
}
5.3Master02节点的配置:
[root@k8s-master02 etc]# mkdir /etc/keepalived
[root@k8s-master02 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.0.106
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.0.200
}
# track_script {
# chk_apiserver
# }
}
5.4Master03节点的配置:
[root@k8s-master03 etc]# mkdir /etc/keepalived
[root@k8s-master03 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.0.1067
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.0.200
}
# track_script {
# chk_apiserver
# }
}
5.5注意上述的健康检查是关闭的,集群建立完成后再开启:
# track_script {
# chk_apiserver
# }
5.6配置KeepAlived健康检查文件(所有Master节点)
[root@k8s-master01 keepalived]# cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 5)
do
check_code=$(pgrep kube-apiserver)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 5
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
5.7启动haproxy和keepalived(所有Master节点)
[root@k8s-master01 keepalived]# systemctl enable --now haproxy
[root@k8s-master01 keepalived]# systemctl enable --now keepalived
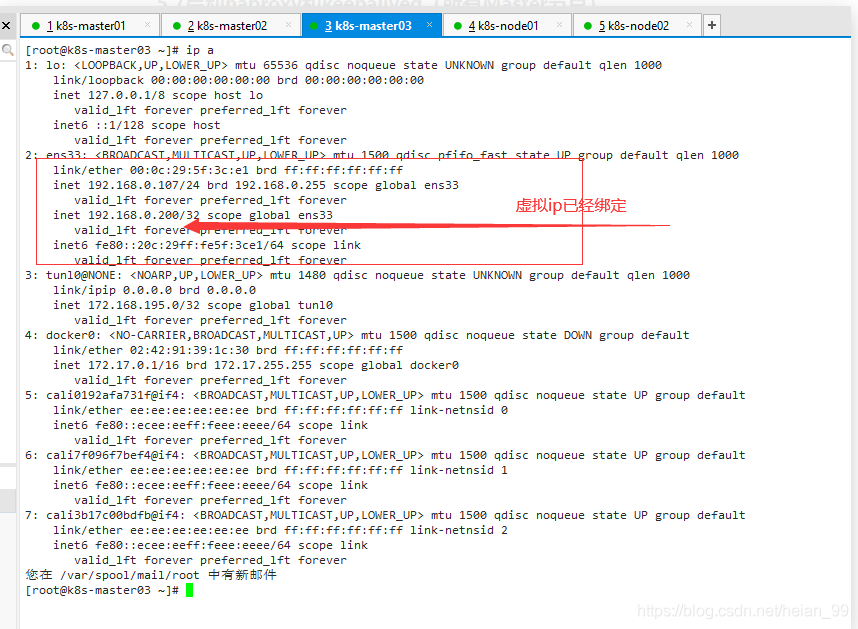
5.8配置K8S组件
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
各Master节点的kubeadm-config.yaml配置文件如下:
Master01:
daocloud.io/daocloud
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.100
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 192.168.0.200
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.0.200:16443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.18.5
networking:
dnsDomain: cluster.local
podSubnet: 172.168.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
==============================================
#如果这个镜像地址无法下载,可以替换:daocloud.io/daocloud 下载
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kubernetesVersion: v1.18.5
#注意安装的Kubernetes的版本
更新kubeadm文件,如果你使用高版本的,可以使用这条命令生成高版本的yaml文件
kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
所有Master节点提前下载镜像,可以节省初始化时间:
kubeadmconfig images pull --config /root/kubeadm-config.yaml -
所有节点设置开机自启动kubelet
systemctl enable --now kubelet
Master01节点初始化,初始化以后会在/etc/kubernetes目录下生成对应的证书和配置文件,之后其他Master节点加入Master01即可:
kubeadminit --config /root/kubeadm-config.yaml --upload-certs不用配置文件初始化:
kubeadm init --control-plane-endpoint "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" --upload-certs
如果初始化失败,重置后再次初始化,命令如下:
kubeadm reset
初始化成功以后,会产生Token值,用于其他节点加入时使用,因此要记录下初始化成功生成的token值(令牌值):
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.0.200:16443 --token 5joxsb.zo1vh747wljgzrlt \
--discovery-token-ca-cert-hash sha256:86ee9b6a65c6d8641507e9e56e66dad47cfa15b41b52a11e175c5f9588a485b8 \
--control-plane --certificate-key bc4726d06255be0cd54592e29068e32c5a49eb8fd30a691342412cf79b3d47c7
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.200:16443 --token 5joxsb.zo1vh747wljgzrlt \
--discovery-token-ca-cert-hash sha256:86ee9b6a65c6d8641507e9e56e66dad47cfa15b41b52a11e175c5f9588a485b8
5.9所有Master节点配置环境变量,用于访问Kubernetes集群:
cat <<EOF >> /root/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source /root/.bashrc
查看节点状态:
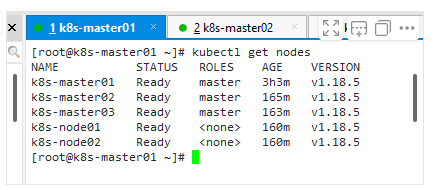
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 14m v1.12.3
采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态:
[root@k8s-master01 ~]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
coredns-777d78ff6f-kstsz 0/1 Pending 0 14m <none> <none>
coredns-777d78ff6f-rlfr5 0/1 Pending 0 14m <none> <none>
etcd-k8s-master01 1/1 Running 0 14m 192.168.0.100 k8s-master01
kube-apiserver-k8s-master01 1/1 Running 0 13m 192.168.0.100 k8s-master01
kube-controller-manager-k8s-master01 1/1 Running 0 13m 192.168.0.100 k8s-master01
kube-proxy-8d4qc 1/1 Running 0 14m 192.168.0.100 k8s-master01
kube-scheduler-k8s-master01 1/1 Running 0 13m 192.168.0.100 k8s-master01
6、Calico组件的安装
注意:如果国内用户下载Calico较慢,所有节点可以配置加速器(如果该文件有其他配置,别忘了加上去)
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
]
}
systemctl daemon-reload
systemctl restart docker
Calico:https://www.projectcalico.org/
https://docs.projectcalico.org/getting-started/kubernetes/self-managed-onprem/onpremises
curl https://docs.projectcalico.org/manifests/calico.yaml -O
- name: CALICO_IPV4POOL_CIDR
value: "172.168.0.0/16"
kubectl apply -f calico.yaml
7、高可用Master
[root@k8s-master01 ~]# kubectl get secret -n kube-system
[root@k8s-master01 ~]# kubectl get secret -n kube-system bootstrap-token-7t2weq -oyaml Token过期后生成新的token:
Node节点生成
kubeadm token create --print-join-command
Master需要生成--certificate-key
kubeadm init phase upload-certs --upload-certs
kubeadm join 192.168.0.200:16443 --token 9zp1xe.h5kpi1b9kd5blk76 --discovery-token-ca-cert-hash sha256:6ba6e5205ac27e39e03d3b89a639ef70f6503fb877b1cf8a332b399549471740 \
--control-plane --certificate-key 309f945f612dd7f0d830b11868edd5135e6cf358ed503107eb645dc8d7c84405
8、Node节点的配置
Node节点上主要部署公司的一些业务应用,生产环境中不建议Master节点部署系统组件之外的其他Pod,测试环境可以允许Master节点部署Pod以节省系统资源。
kubeadm join 192.168.0.200:16443 --token 9zp1xe.h5kpi1b9kd5blk76 --discovery-token-ca-cert-hash sha256:6ba6e5205ac27e39e03d3b89a639ef70f6503fb877b1cf8a332b399549471740
9、 Metrics部署
在新版的Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
Heapster更改metrics的部署文件证书,将metrics-server-3.6.1/metrics-server-deployment.yaml的front-proxy-ca.pem改为front-proxy-ca.crt

将Master01节点的front-proxy-ca.crt复制到所有Node节点
scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node01:/etc/kubernetes/pki/front-proxy-ca.crt
scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node(其他节点自行拷贝):/etc/kubernetes/pki/front-proxy-ca.crt
安装metrics server
kubectl create -f metrics-server-3.6.1/
10、Dashboard部署
官方GitHub:https://github.com/kubernetes/dashboard
Dashboard用于展示集群中的各类资源,同时也可以通过Dashboard实时查看Pod的日志和在容器中执行一些命令等。
可以在官方dashboard查看到最新版dashboard
kubectl apply –f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.4/aio/deploy/recommended.yaml
[root@k8s-master01 ]# kubectl get svc -n kubernetes-dashboard
[root@k8s-master01]# kubectl edit svc kubernetes-dashboard -n !$

在谷歌浏览器(Chrome)启动文件中加入启动参数,用于解决无法访问Dashboard的问题
--test-type--ignore-certificate-errors
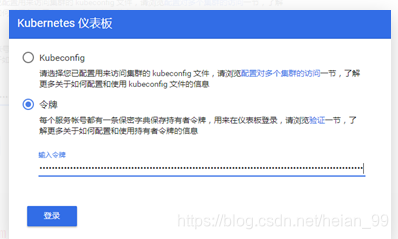
访问Dashboard:https://192.168.0.200:30000,选择登录方式为令牌(即token方式)
vim admin.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
kubectl apply -f admin.yaml
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')

将token值输入到令牌后,单击登录即可访问Dashboard

将Kube-proxy改为ipvs模式,因为在初始化集群的时候注释了ipvs配置,所以需要自行修改一下:
kubectl edit cm kube-proxy -n kube-system
mode: “ipvs”
更新Kube-Proxy的Pod:
kubectl patch daemonset kube-proxy -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"date\":\"`date +'%s'`\"}}}}}" -n kube-system
验证Kube-Proxy模式
[root@k8s-master01 1.1.1]# curl 127.0.0.1:10249/proxyMode
ipvs

[root@k8s-master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 5h50m v1.18.5
k8s-master02 Ready master 5h31m v1.18.5
k8s-master03 Ready master 5h30m v1.18.5
k8s-node01 Ready <none> 5h26m v1.18.5
k8s-node02 Ready <none> 5h26m v1.18.5