import numpy as np
import pandas as pd
data = np.random.randint(1, 10, size=(10, 7))
# print(data)
index = range(data.shape[0])
columns = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'col7']
df = pd.DataFrame(data, index=index, columns=columns)
写表格
这里用df.to_excel来实现写excel表格,其中的index和header参数可以实现控制索引和列名的写入与否。
# 写入表格
df.to_excel('test.xlsx')
df.to_excel('no_index.xlsx', index=None)
df.to_excel('no_columns.xlsx', header=None)
df.to_excel('no_index_or_columns.xlsx', index=None, header=None)
test.xlsl
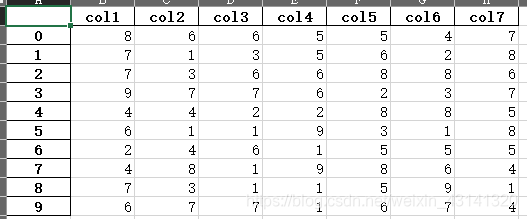
no_index.xlsx
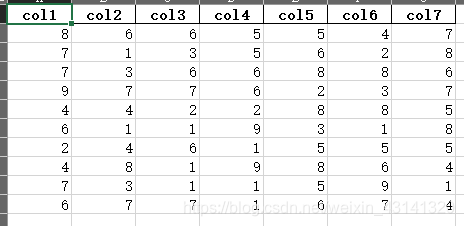
no_columns.xlsx
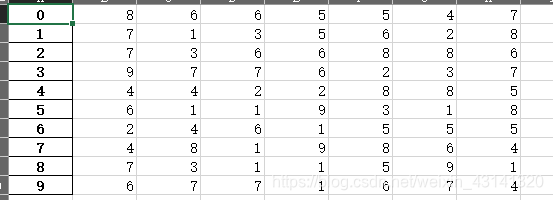
no_index_or_columns.xlsx
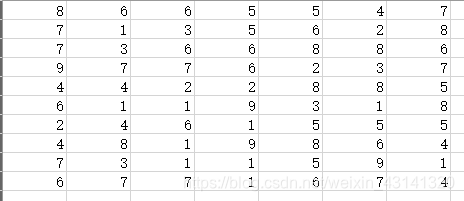
读表格数据
在读取表格的时候需要注意的是,如果表格里原有的数据没有关于列名或者index的内容,那么读取出来的数据是pandas自加index与列名以及原表格中的数据的形式;如果原表格中有关于列名或者index的内容,那么如果不做其他的操作读取出来的是在原来有index与列名的基础上再自动加上index。就像这样:
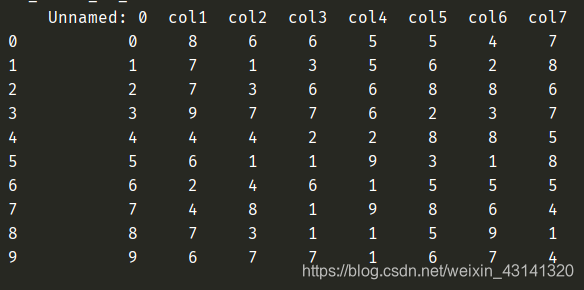
这里的unnamed:0列就是原来的index。
处理index的方法是在读取的时候选中需要的列即可,可以通过pd.iloc或者pd.loc函数来实现。
处理列名的方式是通过为pd.read_excel函数的header参数传入实参来实现的;如果表格中原来的数据没有首行列名,那么传入的header参数为None;如果有首行列名,那么传入的header参数为0。如果header不正确传入会读取出意想不到的错误数据:
现在读取test.xlsx文件,该文件中原来的数据为:
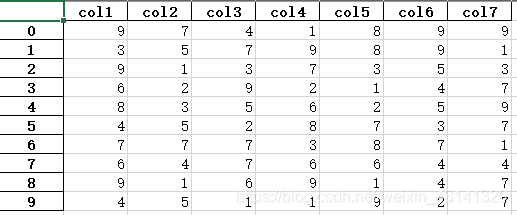
即有首行列名,那么正确的做法应该是:
data = pd.read_excel('test.xlsx', header=0)输出:
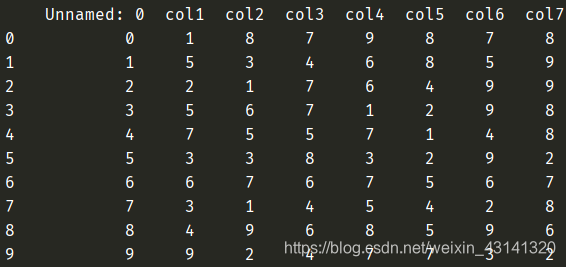
如果输入的是1:
data = pd.read_excel('test.xlsx', header=1)输出:
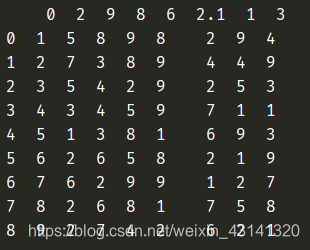
当测试的是no_columns.xlsx文件的时候:
data = pd.read_excel('no_columns.xlsx', header=None)
输出:
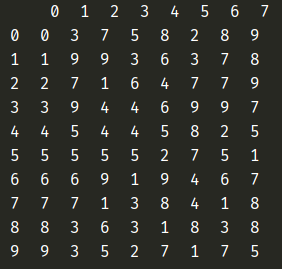
传入其他参数的时候,数据的shape[0]发生变化:
传入1时:
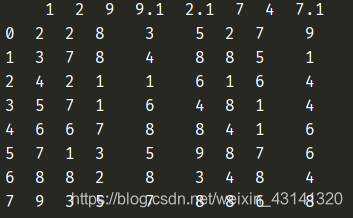
传入0时:

传入2时:
