一、简介
flink-streaming-platform-web系统是基于flink封装的一个可视化的web系统,用户只需在web界面进行sql配置就能完成流计算任务,主要功能包含任务配置、启/停任务、告警、日志等功能。目的是减少开发,完全实现 flink-sql 流计算任务,flink 任务支持单流、双流、单流与维表等,支持本地模式、yarn-per模式、STANDALONE模式。
支持udf、自定义连接器等,完全兼容官方连接器
目前flink版本已经升级到1.12
效果图
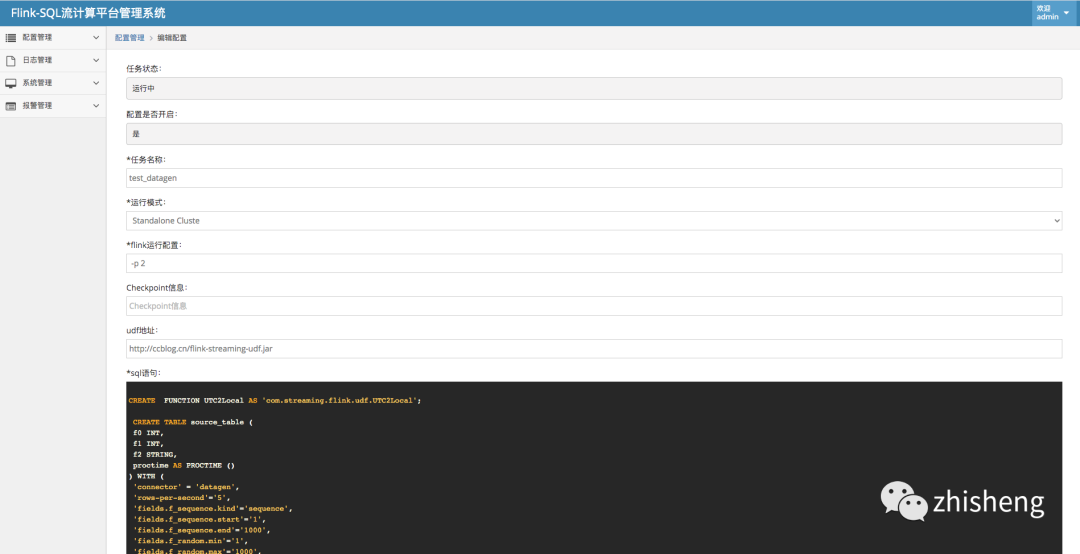
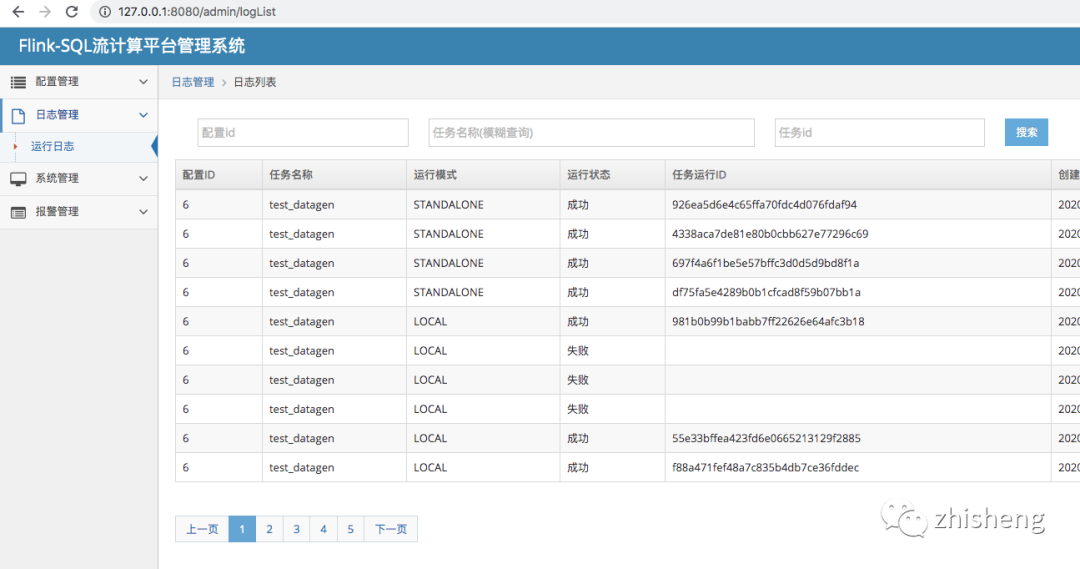
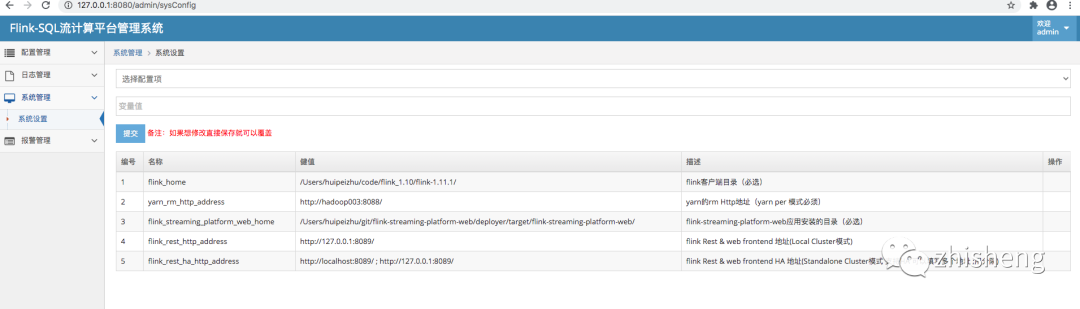
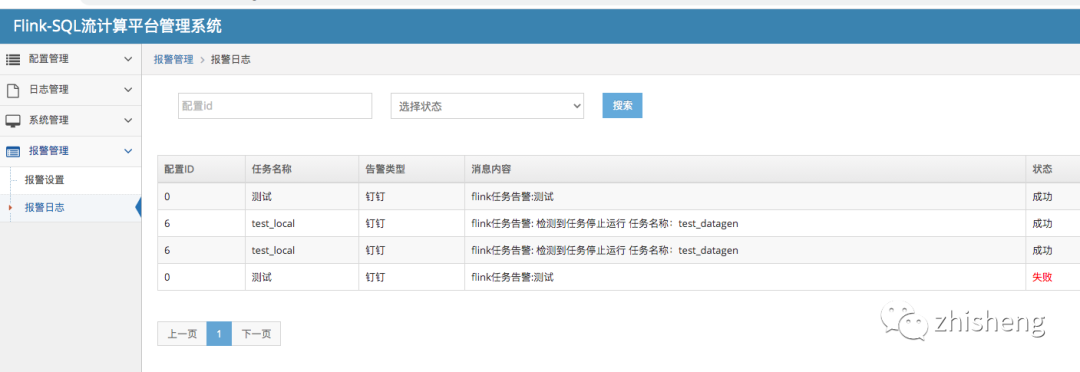
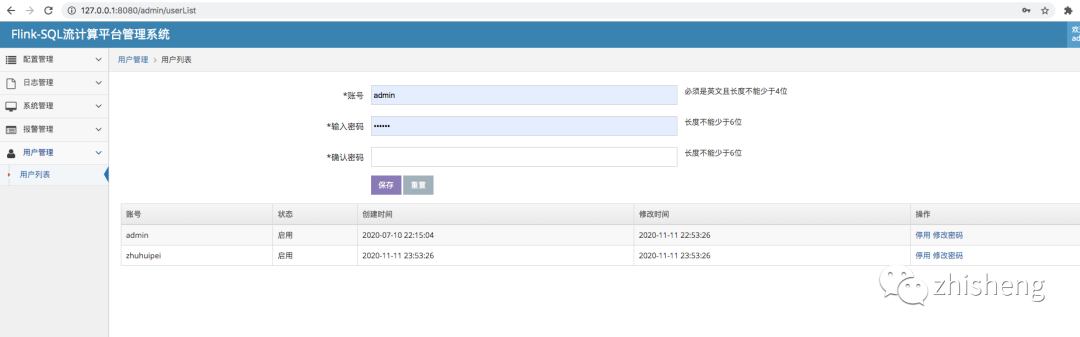
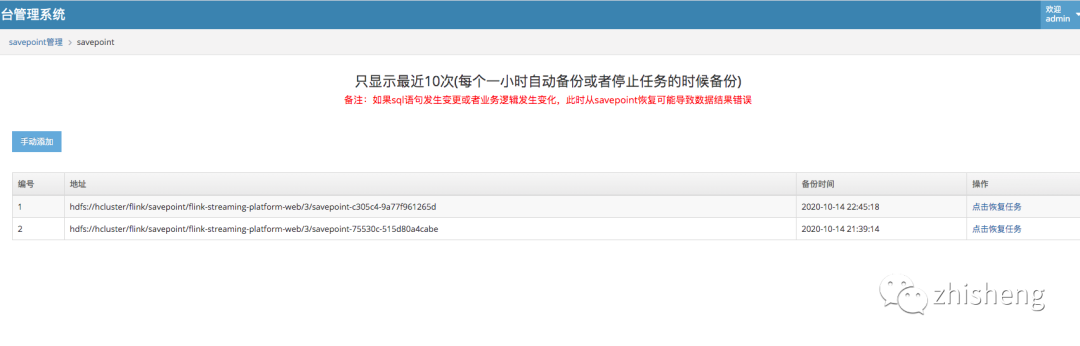
二、环境以及安装
1、环境
-
操作系统:linux (不支持win系统)
-
hadoop版本 2+
-
flink 版本 1.12.0 官方地址: https://ci.apache.org/projects/flink/flink-docs-release-1.12/
-
jdk版本 jdk1.8
-
scala版本 2.11
-
kafka版本 1.0+
-
mysql版本 5.6+
2、应用安装
1、flink客户端安装
下载对应版本
https://www.apache.org/dyn/closer.lua/flink/flink-1.12.0/flink-1.12.0-bin-scala_2.11.tgz
然后解压
a: /flink-1.12.0/conf
1、YARN_PER模式
文件下面放入hadoop客户端配置文件
core-site.xml
yarn-site.xml
hdfs-site.xml
2、LOCAL模式
无
3、STANDALONE模式
无
以上三种模式都需要修改 flink-conf.yaml 开启 classloader.resolve-order 并且设置
classloader.resolve-order: parent-first
b: /flink-1.11.1/lib hadoop集成
下载 flink-shaded-hadoop-2-uber-${xxx}.jar 到lib
地址 https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
完毕后执行 export HADOOP_CLASSPATH=hadoop classpath
export HADOOP_CLASSPATH=hadoop classpath
2、flink-streaming-platform-web安装
a:下载最新版本 并且解压 https://github.com/zhp8341/flink-streaming-platform-web/releases/
tar -xvf flink-streaming-platform-web.tar.gz
b:执行mysql语句
mysql 版本5.6+以上
创建数据库 数据库名:flink_web
执行表语句
语句地址 https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql/flink_web.sql
c:修改数据库连接配置
/flink-streaming-platform-web/conf/application.properties
改成上面建好的mysql地址
关于数据库连接配置 需要看清楚你 useSSL=true 你的mysql是否支持
d:启动web
cd /XXXX/flink-streaming-platform-web/bin
一定要到bin目录下再执行
启动 : sh deploy.sh start
停止 : sh deploy.sh stop
日志目录地址: /XXXX/flink-streaming-platform-web/logs/
e:登录
http://${ip或者hostname}:9084/ 如 : http://hadoop003:9084/
登录号:admin 密码 123456
f:集群
如果需要集群部署模式 简单参考图
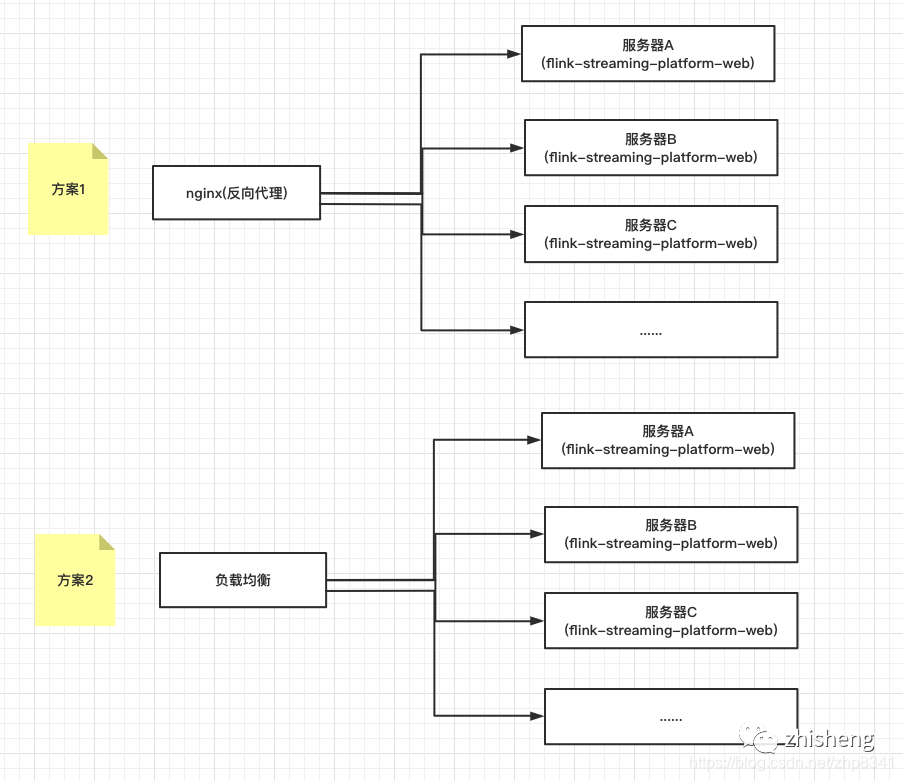
图片
备注:flink客户端必须和flink-streaming-platform-web应用部署在一起
三、功能介绍
1、新增任务配置说明
a: 任务名称(*必选)
任务名称不能超过50个字符 并且 任务名称仅能含数字,字母和下划线
b: 运行模式
YARN_PER( yarn独立模式 https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/ops/deployment/yarn_setup.html#run-a-single-flink-job-on-yarn)
STANDALONE(独立集群 https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/ops/deployment/cluster_setup.html)
LOCAL(本地集群 https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/ops/deployment/local.html )
LOCAL 需要在本地单机启动flink 服务 ./bin/start-cluster.sh
c: flink运行配置
1、YARN_PER模式
参数(和官方保持一致)但是只支持 -yD -p -yjm -yn -ytm -ys -yqu(必选)
-ys slot个数。
-yn task manager 数量。
-yjm job manager 的堆内存大小。
-ytm task manager 的堆内存大小。
-yqu yarn队列明
-p 并行度
-yD 如-yD taskmanager.heap.mb=518
详见官方文档
如: -yqu flink -yjm 1024m -ytm 2048m -p 1 -ys 1
2、LOCAL模式
无需配置
3、STANDALONE模式
-d,--detached If present, runs the job in detached
mode
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-s,--fromSavepoint <savepointPath> Path to a savepoint to restore the job
from (for example
hdfs:///flink/savepoint-1537).
其他运行参数可通过 flink -h查看
d: Checkpoint信息
不填默认不开启checkpoint机制 参数只支持
-checkpointInterval
-checkpointingMode
-checkpointTimeout
-checkpointDir
-tolerableCheckpointFailureNumber
-asynchronousSnapshots
如: -asynchronousSnapshots true -checkpointDir hdfs://hcluster/flink/checkpoints/
(注意目前权限)
| 参数 | 值 | 说明 |
|---|---|---|
| checkpointInterval | 整数 (如 1000) | 默认每60s保存一次checkpoint 单位毫秒 |
| checkpointingMode | EXACTLY_ONCE 或者 AT_LEAST_ONCE | 一致性模式 默认EXACTLY_ONCE 单位字符 |
| checkpointTimeout | 6000 | 默认超时10 minutes 单位毫秒 |
| checkpointDir | 保存地址 如 hdfs://hcluster/flink/checkpoints/ 注意目录权限 | |
| tolerableCheckpointFailureNumber | 1 | 设置失败次数 默认一次 |
| asynchronousSnapshots | true 或者 false | 是否异步 |
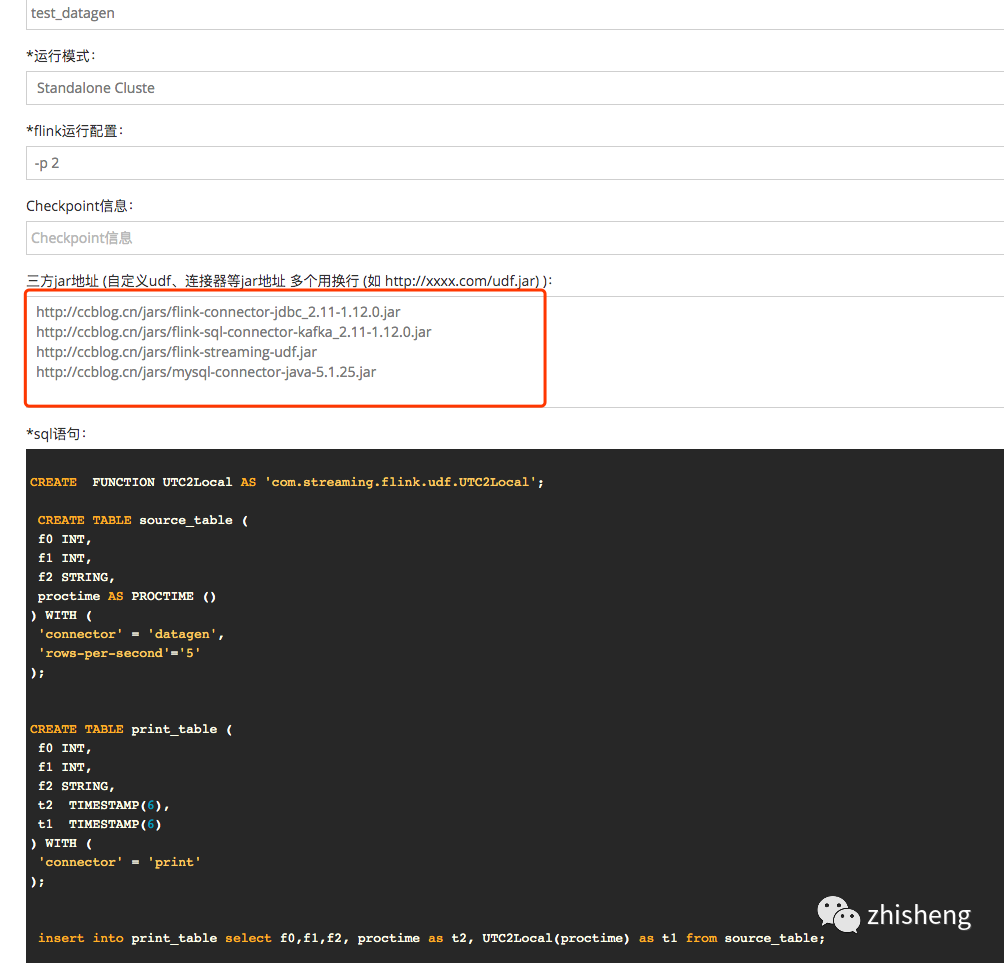
e: 三方地址
填写连接器或者udf等jar
如:
http://ccblog.cn/jars/flink-connector-jdbc_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-sql-connector-kafka_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-streaming-udf.jar
http://ccblog.cn/jars/mysql-connector-java-5.1.25.jar
地址填写后 udf可以在sql语句里面直接写
CREATE FUNCTION jsonHasKey as 'com.xx.udf.JsonHasKeyUDF';
多个url使用换行
udf 开发demo 详见 https://github.com/zhp8341/flink-streaming-udf
2、系统设置
系统设置有三个必选项
1、flink-streaming-platform-web应用安装的目录(必选)
这个是应用的安装目录
如 /root/flink-streaming-platform-web/
2、flink安装目录(必选)
--flink客户端的目录 如: /usr/local/flink-1.12.0/
3、yarn的rm Http地址
--hadoop yarn的rm Http地址 http://hadoop003:8088/
4、flink_rest_http_address
LOCAL模式使用 flink http的地址
5、flink_rest_ha_http_address
STANDALONE模式 支持HA的 可以填写多个地址 ;用分隔
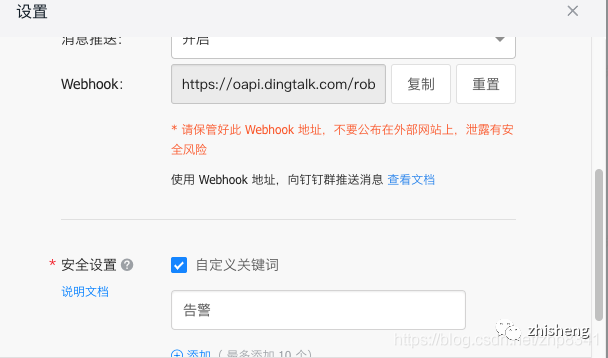
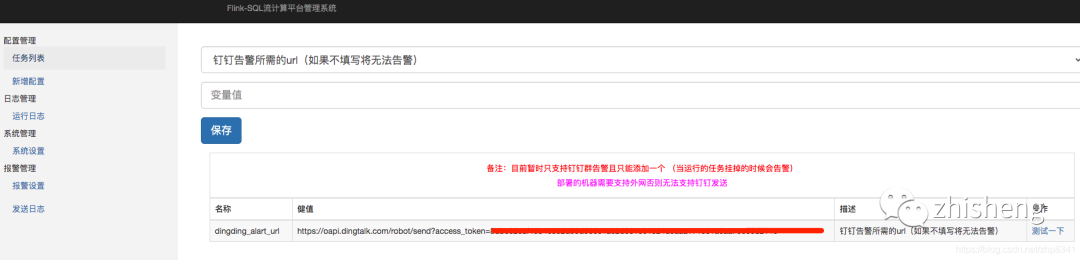
3、报警设置
报警设置用于: 当运行的任务挂掉的时候会告警
资料:钉钉报警设置官方文档:https://help.aliyun.com/knowledge_detail/106247.html
安全设置 关键词必须填写: 告警
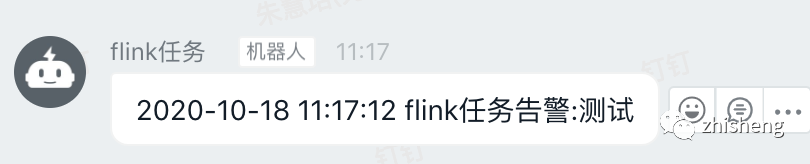
效果图
三、配置demo
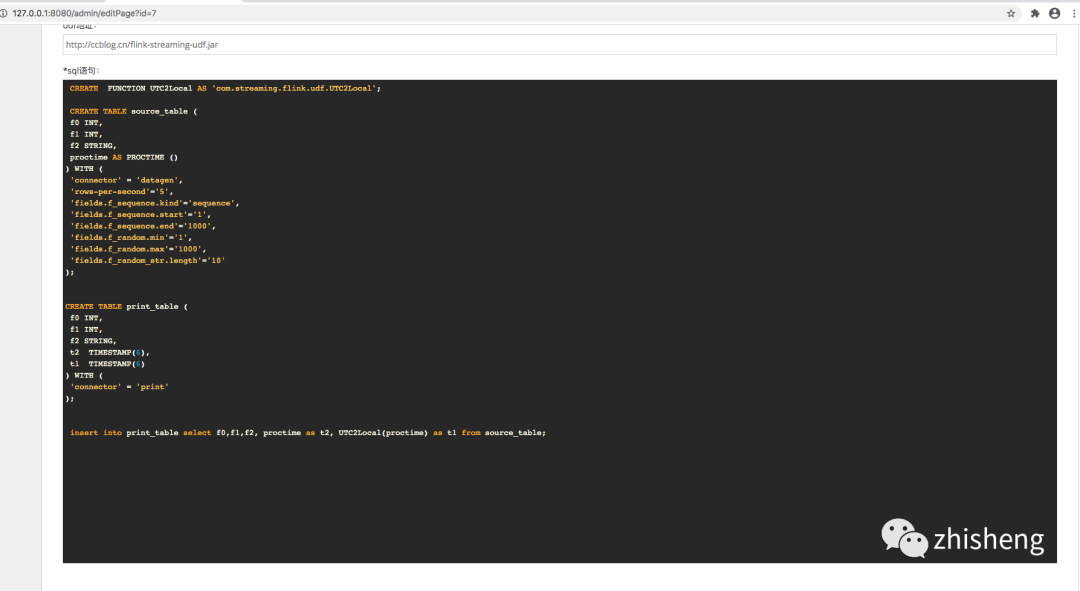
请使用一下sql进行环境测试
CREATE TABLE source_table (
f0 INT,
f1 INT,
f2 STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5'
);
CREATE TABLE print_table (
f0 INT,
f1 INT,
f2 STRING
) WITH (
'connector' = 'print'
);
insert into print_table select f0,f1,f2 from source_table;
以下语法是按照flink1.10写的 有时间重新写
demo1 单流kafka写入mysqld 参考
demo2 双流kafka写入mysql 参考
demo3 kafka和mysql维表实时关联写入mysql 参考
demo4 滚动窗口
demo5 滑动窗口
CREATE FUNCTION jsonHasKey as 'com.xx.udf.JsonHasKeyUDF';
-- 如果使用udf 函数必须配置 udf地址
create table flink_test_6 (
id BIGINT,
day_time VARCHAR,
amnount BIGINT,
proctime AS PROCTIME ()
)
with (
'connector.properties.zookeeper.connect'='hadoop001:2181',
'connector.version'='universal',
'connector.topic'='flink_test_6',
'connector.startup-mode'='earliest-offset',
'format.derive-schema'='true',
'connector.type'='kafka',
'update-mode'='append',
'connector.properties.bootstrap.servers'='hadoop003:9092',
'connector.properties.group.id'='flink_gp_test1',
'format.type'='json'
);
create table flink_test_6_dim (
id BIGINT,
coupon_amnount BIGINT
)
with (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://127.0.0.1:3306/flink_web?characterEncoding=UTF-8',
'connector.table' = 'test_dim',
'connector.username' = 'flink_web_test',
'connector.password' = 'flink_web_test_123',
'connector.lookup.max-retries' = '3'
);
CREATE TABLE sync_test_3 (
day_time string,
total_gmv bigint
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://127.0.0.1:3306/flink_web?characterEncoding=UTF-8',
'connector.table' = 'sync_test_3',
'connector.username' = 'flink_web_test',
'connector.password' = 'flink_web_test_123'
);
INSERT INTO sync_test_3
SELECT
day_time,
SUM(amnount - coupon_amnount) AS total_gmv
FROM
(
SELECT
a.day_time as day_time,
a.amnount as amnount,
b.coupon_amnount as coupon_amnount
FROM
flink_test_6 as a
LEFT JOIN flink_test_6_dim FOR SYSTEM_TIME AS OF a.proctime as b
ON b.id = a.id
)
GROUP BY day_time;
官方相关预发和连接下载
请移步 https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/
四、支持flink sql官方语法
完全按照flink1.12的连接器相关的配置 详见
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/
如果需要使用到连接器请去官方下载 如:kafka 连接器 https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/kafka.html
第一种下载连接器后直接放到 flink/lib/目录下就可以使用了
1、该方案存在jar冲突可能,特别是连接器多了以后
2、在非yarn模式下每次新增jar需要重启flink集群服务器
第二种放到http的服务下填写到三方地址
公司内部建议放到内网的某个http服务
http://ccblog.cn/jars/flink-connector-jdbc_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-sql-connector-kafka_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-streaming-udf.jar
http://ccblog.cn/jars/mysql-connector-java-5.1.25.jar
多个url使用换行
自定义连接器打包的时候需要打成shade 并且解决jar的冲突
个人建议使用第二种方式,每个任务之间jar独立,如果把所有连接器放到lib 可能会和其他任务的jar冲突公用的可以放到flink/lib目录里面 如:mysql驱动 kafka连接器等
五、其他
1、由于hadoop集群环境不一样可能导致部署出现困难,整个搭建比较耗时.
2、由于es 、hbase等版本不一样可能需要下载源码重新选择对应版本 源码地址 https://github.com/zhp8341/flink-streaming-platform-web
六、问题
1、
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Could not build the program from JAR file.
Use the help option (-h or --help) to get help on the command.
解决
export HADOOP_HOME=/etc/hadoop
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile
最好配置成全局变量
2
2020-10-02 14:48:22,060 ERROR com.flink.streaming.core.JobApplication - 任务执行失败:
java.lang.IllegalStateException: Unable to instantiate java compiler
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:434)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.load3(JaninoRelMetadataProvider.java:375)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.lambda$static$0(JaninoRelMetadataProvider.java:109)
at org.apache.flink.calcite.shaded.com.google.common.cache.CacheLoader$FunctionToCacheLoader.load(CacheLoader.java:149)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3542)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.loadSync(LocalCache.java:2323)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2286)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2201)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache.get(LocalCache.java:3953)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache.getOrLoad(LocalCache.java:3957)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$LocalLoadingCache.get(LocalCache.java:4875)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.create(JaninoRelMetadataProvider.java:475)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.revise(JaninoRelMetadataProvider.java:488)
at org.apache.calcite.rel.metadata.RelMetadataQuery.revise(RelMetadataQuery.java:193)
at org.apache.calcite.rel.metadata.RelMetadataQuery.getPulledUpPredicates(RelMetadataQuery.java:797)
at org.apache.calcite.rel.rules.ReduceExpressionsRule$ProjectReduceExpressionsRule.onMatch(ReduceExpressionsRule.java:298)
at org.apache.calcite.plan.AbstractRelOptPlanner.fireRule(AbstractRelOptPlanner.java:319)
at org.apache.calcite.plan.hep.HepPlanner.applyRule(HepPlanner.java:560)
at org.apache.calcite.plan.hep.HepPlanner.applyRules(HepPlanner.java:419)
at org.apache.calcite.plan.hep.HepPlanner.executeInstruction(HepPlanner.java:256)
at org.apache.calcite.plan.hep.HepInstruction$RuleInstance.execute(HepInstruction.java:127)
at org.apache.calcite.plan.hep.HepPlanner.executeProgram(HepPlanner.java:215)
at org.apache.calcite.plan.hep.HepPlanner.findBestExp(HepPlanner.java:202)
at org.apache.flink.table.planner.plan.optimize.program.FlinkHepProgram.optimize(FlinkHepProgram.scala:69)
at org.apache.flink.table.planner.plan.optimize.program.FlinkHepRuleSetProgram.optimize(FlinkHepRuleSetProgram.scala:87)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:62)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:58)
at scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
at scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableOnce$class.foldLeft(TraversableOnce.scala:157)
at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:57)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizer.optimizeTree(StreamCommonSubGraphBasedOptimizer.scala:170)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizer.doOptimize(StreamCommonSubGraphBasedOptimizer.scala:90)
at org.apache.flink.table.planner.plan.optimize.CommonSubGraphBasedOptimizer.optimize(CommonSubGraphBasedOptimizer.scala:77)
at org.apache.flink.table.planner.delegation.PlannerBase.optimize(PlannerBase.scala:248)
at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:151)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:682)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.sqlUpdate(TableEnvironmentImpl.java:495)
at com.flink.streaming.core.JobApplication.callDml(JobApplication.java:138)
at com.flink.streaming.core.JobApplication.main(JobApplication.java:85)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:321)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:205)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:138)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:664)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:895)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:968)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:968)
Caused by: java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
at org.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129)
at org.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:432)
... 60 more
conf/flink-conf.yaml
配置里面 设置 classloader.resolve-order: parent-first
主要日志目录
1、web系统日志
/{安装目录}/flink-streaming-platform-web/logs/
2 、flink客户端命令
${FLINK_HOME}/log/flink-${USER}-client-.log
七、RoadMap
-
支持除官方以外的连接器 如:阿里云的sls
-
任务告警自动拉起
-
支持Application模式
-
完善文档