
文章目录
1. Motivation
-
two-stage 通过ROIPool方法,会造成图像信息的丢失(低分辨率以及ROIPool/Align)的对齐操作。同时它的参数量较多比较复杂。
-
现有(2019)的one-stage实例分割方法精度比不上two-stage方法。one-stage中的segmentation-based方法的bottlenecks是如何制定clustering procedures,在制定cluster的数量以及cluster的中心位置上存在难度,这就造成了proposal-based方法的效果incomparable。
-
Mask RCNN复习知识
Mask RCNN中掩码分支输出[28, 28, C],这是对于每一个proposal而言的,流程就是detect-first then segment,先根据回归和分类分支得到对应的bbox的坐标以及这个bbox的分类,然后对应到C中的某一个channel上。然后怎么运用mask的gt呢,也就是对应的pixel用1表示foreground,用0表示background,就是得到的bbox后,查看里面包含了多少gt的mask,包含的mask计算BCE loss。
在测试的时候,直接根据分类分支得到的类别C确定mask对应的某一个Channel上的mask预测值,然后设置一个阈值(论文中给出的是0.5),大于这个阈值的 m a s k [ x , y , C ] mask[x,y, C] mask[x,y,C]设置为1,否则为0,从而构建出mask。然后再根据回归的坐标得到bbox的坐标,最后得到候选框的分类、边界框以及内部的mask。
2. Contribution
作者将目前的实例分割的方法分为proposal-based方法以及segmentation-based方法。本文提出了将Embedding coupling的one-stage 实例分割模型EmbedMask,类似proposal-based方法,EmbedMask建立在检测模型的基础之上(FCOS),同时EmbedMask额外添加了Embedding 模块来产生pixel embeddings 以及 proposal embeddings,其中pixel embedings如果和proposal embeddings 属于同一个实例,那么pixel embeddings就被proposal embeddings指导,也就是pixels会被制定为相应的proposals的mask。
如图1所示,图 c代表的是pixel embedding,图b代表的是instance proposals (其中embedding proposals用不同的颜色表示)。

作者总结的贡献有2点:
-
本文提出了EmbedMask,一个新的框架,结合了proposal-based方法和segmentation-based方法,通过加入了pixel-embedding以及proposal-embedding方法,根据pixel embedding的相似性,来制定
We propose a framework that unites the proposal-based and segmentation-based methods, by introducing the concepts of proposal embedding and pixel embedding so that pixels are assigned to instance proposals according to their embedding similarity.
-
作为一个one-stage 实例分割方法,EmbedMask可以达到与Mask R-CNN comparable的精度(37.7 vs. 38.1),并且EmbedMask可以获得更高分辨率的mask以及更快的速度。
As a one-stage instance segmentation method, our method can achieve comparable scores as Mask R- CNN in the COCO benchmark, and meanwhile it provides masks with a higher quality than Mask R-CNN, running at a higher speed.
3. EmbedMask
3.1 Overview
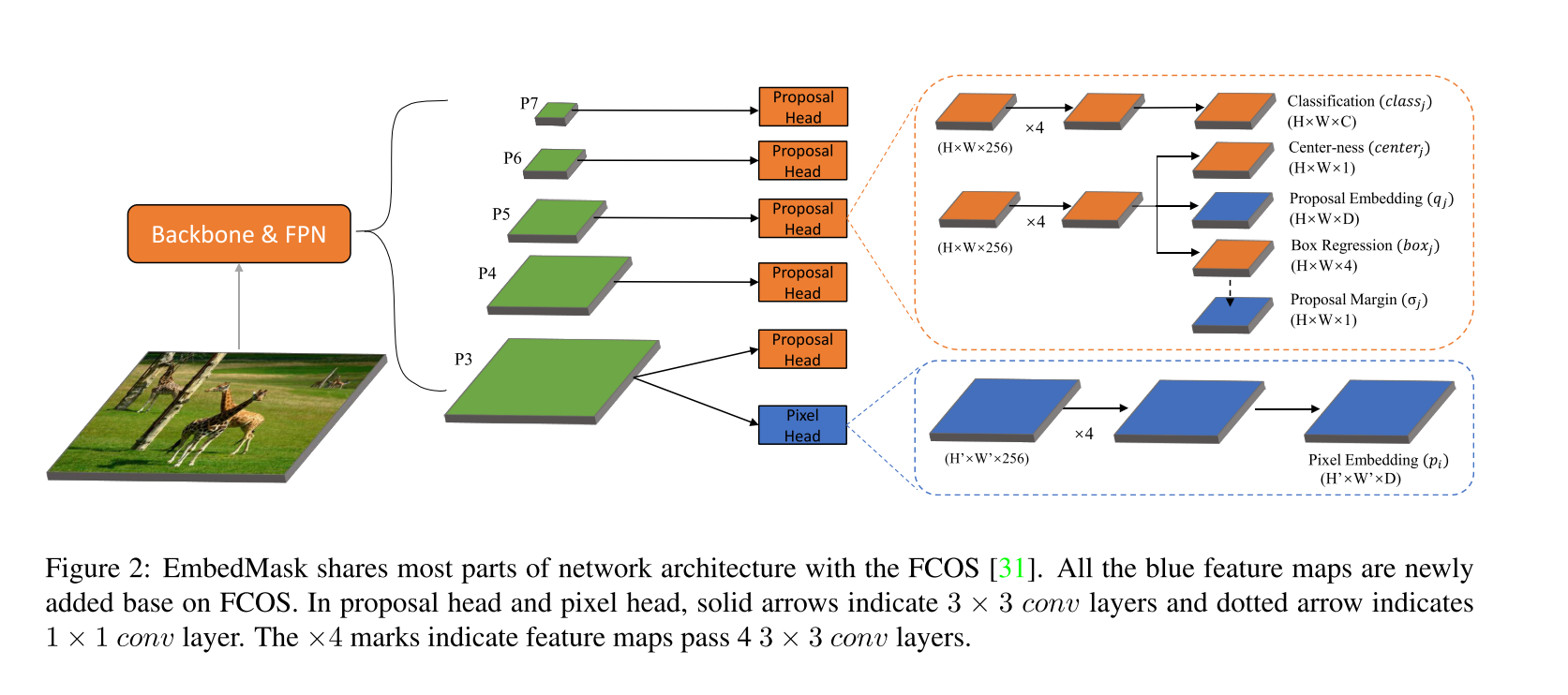
EmbedMask的网络结构,如图2所示,EmbedMask采用FCOS的架构,其中红色部分是FCOS原来的结构,蓝色部分是新加入的。EmbedMask加入了三个新的模块,分别是Proposal head中的Proposal Embedding以及Proposal Margin,以及Pixel Head中的Pixel Embedding。
- 其中Pixel Embedding特征图大小为 H × W × D H \times W \times D H×W×D,设置为p,是通过最大的FPN层P3得到了,中间是5个3x3的conv。
- Proposal bedding特征图大小为 H × W × D H \times W \times D H×W×D,设置为q,是和center-ness以及box regression共享卷积权重的。(注意根据FOCS,每个FPN层的回归、分类是共享权重的,分为2类共享的卷积核)
- Proposal Margin特征图大小为 H × W × 1 H \times W \times 1 H×W×1,设置为 σ \sigma σ,是在box regression分支后生成的。
对于proposal head,产生proposal features,对于location x j x_j xj的总的特征图 p r o p o s a l j proposal_j proposalj可以表示为一个tuple { c l a s s j , b o x j , c e n t e r j , q j , σ j } \{class_j, box_j, center_j, q_j, \sigma_j \} { classj,boxj,centerj,qj,σj}。
对于每一个porposal和每一个pixel,需要计算proposal embedding 以及pixel embedding的distance,从而来描述这个pixel是否属于某个proposal的似然,同时proposal margin对于这种似然肯定了确切的boundary来得到最后的mask。
3.2 Embedding Definition
proposal embedding代表的是obejct-level的特征,而pixel embedding代表的是pixel-level的特征。
The proposal embedding represents the object-level context features for the object instance, which is a good representation of entire instance, while the pixel embedding represents the pixel-level context features for each location on the image, which learns the relation between each pixel with corresponding instance.
相比于之前的segmentation-based方法,EmbedMask可以避免去寻找cluster centers的中心以及数量。
Proposal embeddings are used as cluster centers of instances to do pixel clustering among the pixel embeddings, so that the difficulties appeared in segmentation-based methods, such as finding the locations and counts of cluster centers, are avoided.
在inference中,对于每一个pixel x i x_i xi的pixel embedding 用 p i p_i pi表示,经过NMS后的instance proposal S k S_k Sk的proposal embedding用 Q k Q_k Qk表示。如果 x i x_i xi与proposal embedding Q k Q_k Qk的距离足够接近,那么pixel就被制定为这个instance S k S_k Sk中。作者设置了一个margin δ \delta δ,那么 S k S_k Sk的二进制掩码 M a s k k ( x i ) Mask_k(x_i) Maskk(xi)的pixel assignment可以用以下公式计算:
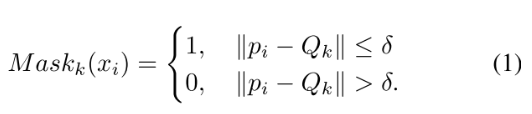
在训练中,pixel embedding和proposal embedding联合用来产生mask。 S k S_k Sk显而易见就是ground truth mask, Q k Q_k Qk作为gt instance S k S_k Sk对应的proposal embeddings,(选取正样本的规则在3.5)也就是正样本proposal embeddings的均值。因此,如果pixel x i x_i xi属于某一个instance s k s_k sk的gt mask,那么就让 p i p_i pi与 Q k Q_k Qk更近。
为了更好对于前景和背景的pixel embedding进行挑选,一种直观的想法是在hinge loss应用两种固定的margins,如公式2所示:
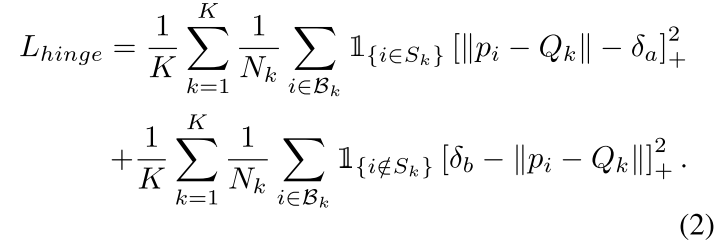
L h i n g e l o s s = ∑ i = 1 N m a x ( 0 , 1 − y i l o g y ^ ) L_{hingeloss} = \sum \limits_{i=1}^N max(0, 1-y_ilog \hat y) Lhingeloss=i=1∑Nmax(0,1−yilogy^)
其中,公式2中的变量表示如下:
-
K表示instance gt的数量。
-
B k B_k Bk代表的是对于 S k S_k Sk的需要被supervised的pixel embeddings的集合,也就是在 S k S_k Sk的bbox内部的pixel embeddings(就会呗分成了在mask内部的以及不在mask内部,即bbox内其余的background的部分)。
-
N k N_k Nk表示 B k B_k Bk中pixel embeddings的数量。 [ x ] + = m a x ( 0 , x ) [x]_+=max(0, x) [x]+=max(0,x),这一步是根据hinge loss原来公式来的。
-
I x ∈ S k \mathbb{I}_{x\in S_k} Ix∈Sk代表指示函数,如果为1代表pixel x在 S k S_k Sk的gt mask内部(注意不是gt box 而是gt mask),否则为0。
-
δ a \delta_a δa以及 δ b \delta_b δb分别代表了push和pull 策略的2个margins。
-
loss的第一项表示使得在margin δ a \delta_a δa中缩小距离,即 ∣ ∣ p i − Q k ∣ ∣ ||p_i -Q_k|| ∣∣pi−Qk∣∣,即当 ∣ ∣ p i − Q k ∣ ∣ < δ a ||p_i -Q_k||<\delta_a ∣∣pi−Qk∣∣<δa,那 [ x ] + = m a x ( 0 , ∣ ∣ p i − Q k ∣ ∣ − δ a ) = 0 [x]_+=max(0,||p_i -Q_k||-\delta_a)=0 [x]+=max(0,∣∣pi−Qk∣∣−δa)=0也就是pi与Qk之间的距离很小,那么就loss就为0。
-
第二项表示在margin δ b \delta_b δb外增大距离,即增大 ∣ ∣ p i − Q k ∣ ∣ ||p_i -Q_k|| ∣∣pi−Qk∣∣,即当 ∣ ∣ p i − Q k ∣ ∣ > δ b ||p_i -Q_k||>\delta_b ∣∣pi−Qk∣∣>δb, [ x ] + = ( δ b − ∣ ∣ p i − Q k ∣ ∣ ) = 0 [x]_+=(\delta_b-||p_i -Q_k||)=0 [x]+=(δb−∣∣pi−Qk∣∣)=0。
-
但作者发现这种固定的margins会导致3.3所示的一些问题,因此作者之后提出一个可学习的margins来取代。
3.3 Learnable Margin
作者分析了为什么fix margins不适合训练,其中有2点:
- δ b , δ a , δ \delta_b,\delta_a, \delta δb,δa,δ,前2者用于训练,后者用于测试阶段,都是人工制定的,不利于找到最优解。
- fix margins不利于多尺度的训练。大尺度的物体比较scattered稀疏,而小物体比较concentrated。
为了避免这些问题,对于所有的instance proposals,作者提出了适用于多尺度检测的margins δ j \delta_j δj,而且 δ j \delta_j δj不需要人工制定,可以从训练中直接的进行学习。通过高斯函数,可以将pixel embedding和proposal embedding之间的距离设置在 [ 0 , 1 ) [0,1) [0,1)之间,设置为公式3:
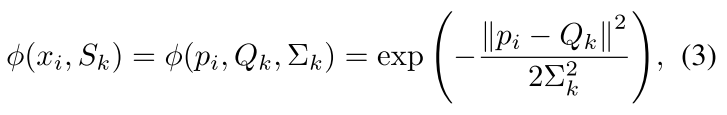
ϕ ( x i , S k ) \phi(x_i,S_k) ϕ(xi,Sk)表示pixel x i x_i xi是否属于 S k S_k Sk的mask。如果 p i p_i pi与 Q k Q_k Qk之间的距离很接近,那么公式3的output ϕ ( x i , S k ) \phi(x_i,S_k) ϕ(xi,Sk)就为1,否则为0。其中,公式3中的新变量 ∑ k \sum_k ∑k来自于 δ j \delta_j δj,来描述 Q k Q_k Qk来自于 q j q_j qj的程度, ∑ k \sum_k ∑k对于每一个instanae扮演margin的作用。这样就对于每一个instance proposal, δ j \delta_j δj就可以提供可学习的margin。
The additional introduced variant Σ k Σ_k Σk comes from σj just like how Q k Q_k Qk comes from q j q_j qj.
As what is introduced in [26], the Σ k Σ_k Σk plays a role of margin for instance S k S_k Sk.
于是二进制分类loss可以被优化为公式4:
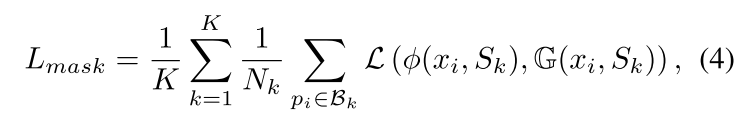
其中 L ( . ) L(.) L(.)表示二进制的分类loss,本文中使用了lovasz-hinge loss。 G ( x i , S k ) \mathbb{G}(x_i, S_k) G(xi,Sk)代表了 x i x_i xi的gt label,用于判断x是否属于某一个proposal S k S_k Sk的mask,取值为 { 0 , 1 } \{0,1\} { 0,1}。这样的损失函数就包含了2个embedding以及margin的参数,因此porposal的margin就可以被自动的学习,并且对于每一个实例来说,相比于使用hinge loss,使用公式4生成的margin更加灵活。
3.4 Smooth Loss
在训练中,Sk代表的是gt的instance,因此对于每一个instance Sk,Qk和 ∑ k \sum_k ∑k就是 q j , σ j q_j, \sigma_j qj,σj的正样本集合的均值,将这个正样本集合设置为 M k \mathcal M_k Mk,Qk以及 ∑ k \sum_k ∑k的计算方式如公式5以及6所示,其中 N k N_k Nk代表的是对于 S k S_k Sk中proposal embedding以及margin的正样本的数量。(也就是说 q j q_j qj是positive examples,而是Qk是将属于这个instance的所有的postivie examples归一化的结果)。
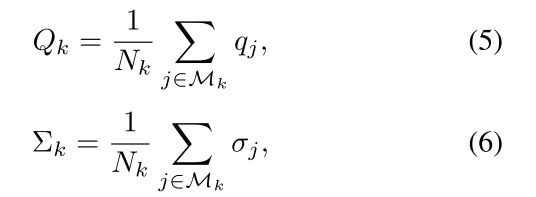
但是在测试过程中, S k S_k Sk代表的是经过NMS后留下来的instance proposal,因此 Q k Q_k Qk, ∑ k \sum_k ∑k也随之改变了。
由于在训练和测试过程中 S k S_k Sk的含义不同,因此训练和测试中的 Q k Q_k Qk以及 ∑ k \sum_k ∑k是不一样的。基于此问题,作者提出需要对训练过程进行smooth loss,来使得它们更加的接近,如公式7所示:
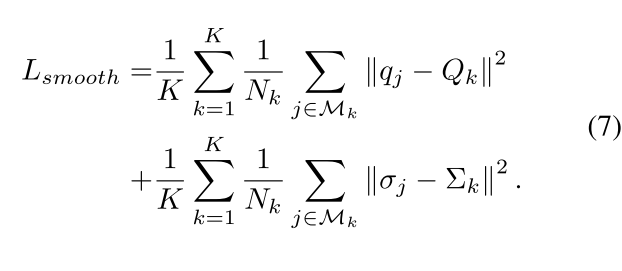
3.5 Training
-
Objective
除了FCOS中使用的回归,分类以及ctrness的loss,在EmbedMask中对掩码预测分支新加入了 L m a s k L_{mask} Lmask以及$L_{smooth}$2个损失函数,total loss由公式8所示:
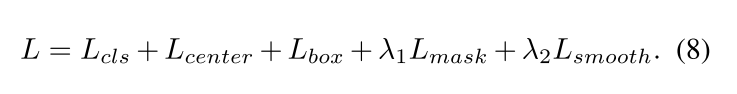
-
Training Samples for Box and Classification
在计算分类和回归时,作者定义正样本为 { b o x j , c l a s s j , c e n t e r j } \{box_j, class_j, center_j\} { boxj,classj,centerj},正样本的真实坐标要映射到原图的中心区域(其实就是后来FCOS的 center sampling),同时中心采样点的location也要在gt的mask中(这一点是不同的)。相比于原来FCOS中制定的sampling策略,EmbedMask采用的方法更加严格。
We define the positive samples as the parameters b o x j , c l a s s j , c e n t e r j {box_j, class_j, center_j} boxj,classj,centerj whose real locations mapped back to the original image locate on the center region of the ground-truth bounding box, and at the meantime the locations are in the mask of the ground-truth instances.
-
Training Samples for Proposal Embedding and Margin
使用IOU,pred box与gt box的IOU值要大于0.5
that the Intersection over Union (IoU) between the corresponding predicted b o x j box_j boxj in the sampled location and the ground-truth box for instance S k S_k Sk should be more than 0.5
-
Training Samples for Pixel Embedding
上文中提到,原来是只有属于 B k B_k Bk的pixel embeddings才用来监督 S k S_k Sk。但因为在实践中,作者发现如果稍微扩大box来增加training example,实验结果会更好。因此,作者使用手工扩大bbox的方法。
B_k represents the set of pixel embeddings that need to be supervised for the instance S_k.
3.6 Inference
给定输入的图片,首先会经过object detection procedure(FCOS)得到分类,回归以及ctrness的预测值,然后经过NMS方法,剩余的pred instances就作为instance proposals S k S_k Sk。每一个 S k S_k Sk都有bbox的坐标,以及category的得分值,proposal embedding q j q_j qj以及marigin σ j \sigma_j σj。其中proposal embedding q j q_j qj以及marigin σ j \sigma_j σj在测试中就是作为 Q k Q_k Qk以及 ∑ k \sum_k ∑k。同时,对于每张图片,获得pixel embedding p i p_i pi。对于 S k S_k Sk的pixel x i x_i xi,使用公式3来计算 x i x_i xi属于 S k S_k Sk的概率,然后将概率通过阈值转换为二进制的mask 值,也就是大于0.5的值设置为二进制mask的1,否则为0。