参考–写的很好
极大似然估计
概括:模型已定,参数未知。如何得到参数:通过不同的参数下,所有观测样本出现的概率之积 — 选择概率之积最大的参数
就是我们要求的参数。
极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率极大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
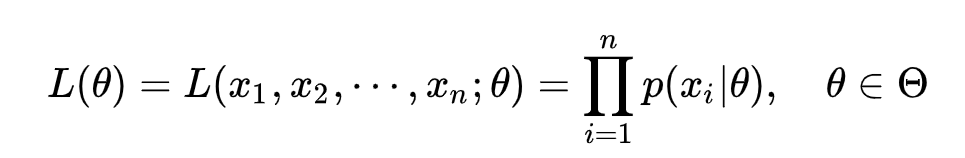
这个函数反映的是在不同的参数theata下,取得当前这个样本集的概率,那么概率越大,说明结果越倾向于这个theata。

极大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而极大似然估计是已经知道了结果,然后寻求使该结果出现的可能性极大的条件,以此作为估计值。
假如一个学校的学生男女比例为 9:1 (条件),那么你可以推出,你在这个学校里更大可能性遇到的是男生 (结果);
假如你不知道那女比例,你走在路上,碰到100个人,发现男生就有90个 (结果),这时候你可以推断这个学校的男女比例更有可能为 9:1 (条件),这就是极大似然估计。
理论:已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,通过若干次试验,观察其结果,利用结果推出参数的大概值。
求极大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为 0,得到似然方程;
(4)解似然方程,得到的参数。
在分类问题中,交叉熵的本质就是似然函数的极大化.
极大化似然函数其实就是在极小化代价函数 。

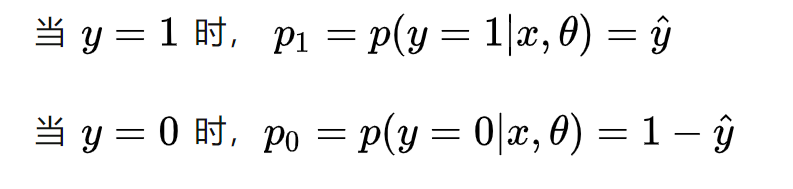

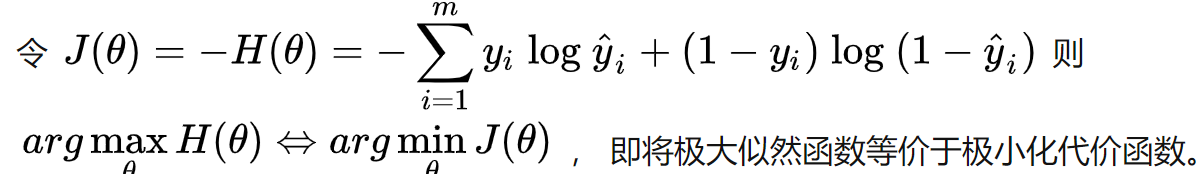
EM算法
EM算法的E步,得到Q函数;M步:参数极大化似然。
Q函数其实就是为了极大化logP(Y|C),C是模型参数,Y是观测量,通过推导得到的。
Q函数: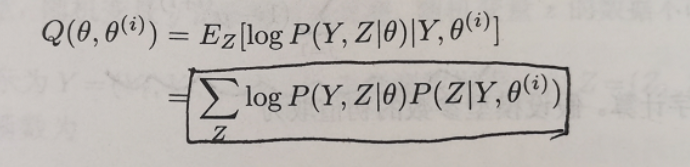
推导得到极大化Q函数等同于极大化上述目标函数L。

模型参数是在迭代中不断变化的。首先把第一个记作O0,则EM算法主要包含两步:
1、基于Ot推断隐变量Z的期望,记为Zt
2、基于已观测变量 X 和 Zt 对 参数O 做极大似然估计,记为O(t+1)–迭代
一个最直观了解 EM 算法思路的是 K-Means 算法。在 K-Means 聚类时,每个聚类簇的质心是隐含数据。我们会假设 K 个初始化质心,即 EM 算法的 E 步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即 EM 算法的 M 步。重复这个 E 步和 M 步,直到质心不再变化为止,这样就完成了 K-Means 聚类。
EM算法是在最大化目标函数时,先固定一个变量使得整体函数变为凸优化函数,求导得到最值,然后利用最优参数更新被固定的变量,进入下一个循环。
EM 算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含参数(EM 算法的 E 步),接着基于观察数据和猜测的隐含参数一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐含参数是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。我们基于当前得到的模型参数,继续猜测隐含参数(EM算法的 E 步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
另外就是参考的一个男女生身高的例子,首先
假设学校所有学生的身高服从正态分布 ![[公式]](https://img-blog.csdnimg.cn/20210115102643895.png) 。实际情况并不是这样的,男生和女生分别服从两种不同的正态分布,即男生
。实际情况并不是这样的,男生和女生分别服从两种不同的正态分布,即男生 ![[公式]](https://img-blog.csdnimg.cn/20210115102709774.png) ,女生
,女生 ![[公式]](https://img-blog.csdnimg.cn/20210115102727897.png) ,(注意:EM算法和极大似然估计的前提是一样的,都要假设数据总体的分布,如果不知道数据分布,是无法使用EM算法的)。那么该怎样评估学生的身高分布呢?
,(注意:EM算法和极大似然估计的前提是一样的,都要假设数据总体的分布,如果不知道数据分布,是无法使用EM算法的)。那么该怎样评估学生的身高分布呢?
我们要从这一堆男女中分别估计男女的身高分布,就需要首先知道是男是女,再进一步预估。—一是这个人是男的还是女的,二是男生和女生对应的身高的正态分布的参数是多少。先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解(草原上的狼和羊,相生相克)。这就是EM算法的基本思想了。
通过估计出男女的身高分布,从而可以判断一个人最可能属于男生还是女生,分成两类,再根据分好的两类计算出身高的分布,继续分两类…往复…

核心思想
EM 算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含参数(EM 算法的 E 步),接着基于观察数据和猜测的隐含参数一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐含参数是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。我们基于当前得到的模型参数,继续猜测隐含参数(EM算法的 E 步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
一个最直观了解 EM 算法思路的是 K-Means 算法。在 K-Means 聚类时,每个聚类簇的质心是隐含数据。我们会假设 K 个初始化质心,即 EM 算法的 E 步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即 EM 算法的 M 步。重复这个 E 步和 M 步,直到质心不再变化为止,这样就完成了 K-Means 聚类。
“EM的应用包括:
支持向量机的SMO算法
混合高斯模型
K-means
隐马尔可夫模型”
从公式推导可以看出,其实就是在最大化目标函数的下界。
EM算法的流程:
开始时随机初始化模型的参数。

最终,输出模型的参数。