对于longAdder的应用,也是在看到concurrentHashMap源码中,统计数组中元素个数的时候,看到了Doug Lea写的一个注释,才开始去关注这个类,这里主要记录下自己对该类源码的学习笔记

longAdder核心思想
通常,在说到这个类的时候,会和atomic中原子类有关系,atomicInteger底层的话,通过unsafe中的native方法进行compareAndSwap方法去进行值的更新,同时,在atomic类中声明的value是volatile修饰,保证了可见性;这个是没问题的,但是有一个问题:如果有多个线程来对一个值进行修改的时候,同一时刻,只会有一个线程去更新成功,其他的线程会不停的cas自旋,这样的话,会消耗CPU的资源;此时:LongAdder就可以出场了,简单而言,longAdder是以空间换时间
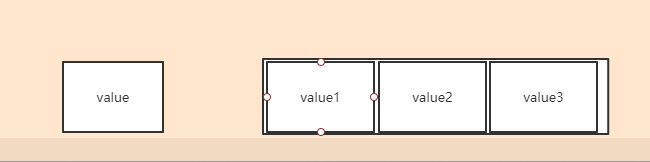
对于atomicLong来说,只有前一个value,如果多个线程对一个字段进行加1,其他线程会不停得自旋,直到当前线程对该值+1成功;
那LongAdder怎么做的呢?在多个线程对同一个变量进行+1的时候,会把对value的压力,分散到一个cell数组中,也就是图中后面的value1、value2…valueN,这样的话,虽然需要额外再维护一个数组,但是可以提高并发量,也就是所谓的以空间换时间
源码

这是longAdder的继承关系
我们来看对应的add方法
add()
/**
* Adds the given value.
*
* cells是volatile修饰的cell数组
* base:也是volatile修饰的变量,在尝试+1 的时候,其实就是对base变量进行+1
* 如果base变量+1失败,就需要将+1的操作,转移到cell数组中的某个节点对应的value
* 在获取总数的时候,就是 base + cell[0] + cell[1] + ... + cell[n]
*
* @param x the value to add
*/
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/**
* 如果cas设置base的值成功,那就无需进入,直接结束运行
* 如果cas设置失败,有可能是并发请求导致失败,就会将该线程需要 + 1的动作,放到cell中执行
*/
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
/**
* 下面这个if判断,最为重要的是最后一个cas
* 如果代码执行到最后一个cas表示,当前cells[i]位置不为null,直接cas设置cells[i]位置的值 +1
* 如果成功,结束运行
* 否则就进入longAccumulate
*
* getProbe()是根据当前线程生成的一个值,其实是为了判断当前线程 + 1的动作,需要放在数组中的哪个位置执行
*/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
/**
* 1.如果当前线程生成的值为0,就生成一个非0的hash值
*/
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
/**
* 2.如果cell数组已经初始化了,进入下面的流程进行处理
*/
if ((as = cells) != null && (n = as.length) > 0) {
/**
* 2.1 如果i位置为null
* 就调用Cell r = new Cell(x); 在进行一些列的判断之后,会将r赋值到cell数组中的i位置
*/
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) {
// Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
// Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
/**
* 2.2
*/
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
/**
* 2.3 对i位置进行+1,代码执行到这里,说明要插入的i位置对应的value不为null,需要通过cas去修改值
*/
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
/**
* 2.4 上面会进行一些判断,暂时没看懂,但是下面的逻辑是扩容,默认扩容为原来的2倍
*/
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
// Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
/**
* 3.如果cell数组为null,尚未初始化,就进入到这里进行处理
* 默认初始化的cell数组长度为2
* 然后将i位置赋值为new Cell(x)
*/
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
// Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
/**
* 4.这里应该是当前线程在初始化的时候,有其他线程已经在初始化了,此时会再次尝试对base变量进行+1,如果成功,就break
* 如果失败,就再次进入for循环
*/
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
通过上面的代码可以看到,在并发的对value进行+1的时候,是会将压力分散到cell数组中,cell数组中也有可能会发生并发的修改,在longAccumulate中会进行一系列的判断,最终会通过扩容或者对value进行+1等操作来完成最后的计数
sum()
/**
* Returns the current sum. The returned value is <em>NOT</em> an
* atomic snapshot; invocation in the absence of concurrent
* updates returns an accurate result, but concurrent updates that
* occur while the sum is being calculated might not be
* incorporated.
* 计算总和
* base + cells数组中每个节点的value值
* @return the sum
*/
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
sum()计算总和的方法就简单了,将value的值和cell数组中,每个位置的值累加即可