Redis
引言:Redis是一种典型的、高性能的 key-value 数据库。Redis是使用c语言开发的,但是有一些地方是由自己构建的数据结构,比如说他的strings等等。
与传统数据库不同的是,Redis的数据是存在内存中的(我们知道传统的数据库比如说mysql他的数据是存在磁盘上的),也就是说他是内存数据库,所以读写速度非常快(Redis能读的速度是110000次/s,写的速度是81000次/s ,因此往往用于缓存方向)
Redis常用于存放热点数据。
一、分布式缓存技术
这里有必要说一下的是什么是分布式?是么是集群?
简单来讲:
集群就是多台计算机在干同一件事情;
分布式就是在这些计算机中,每一台负责不同的步骤。
分布式缓存的话,使用比较多的就是Memcached 和 Redis。分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。(ps:如果说要处理大量的文档的话,使用MongoDB是一个不错的选择)
1、Redis
- 支持持久化
- Redis可以将数据保存到磁盘中,重启的时候可以再次加载进行使用
- 支持更丰富的数据类型
- 不仅仅支持k/v,同时还提供list、set、zset、hash等数据结构的存储
- 有灾难恢复机制
- 因为redis可以将数据持久化到磁盘上
- 支持cluster集群模式
- 使用的是单线程的多路IO复用模型(Redis6.0引入了多线程IO)
- 删除策略同时使用了惰性删除和定期删除
- 支持事务(不支持 roll back)
- 有过期策略
- 在服务器内存使用完以后,可以将数据存到磁盘上
2、Memcached
- 不支持持久化:将数据全部存储于内存中
- 只支持最简单的k/v
- 没有原生的集群模式,需要用户来实现往集群中分片写入数据
- 是多线程的
- 有过期策略
- 服务器内存用完以后,直接报异常
- 设有过期策略
- 删除策略只支持惰性删除
3、缓存数据的处理流程
盗用大神一张图:
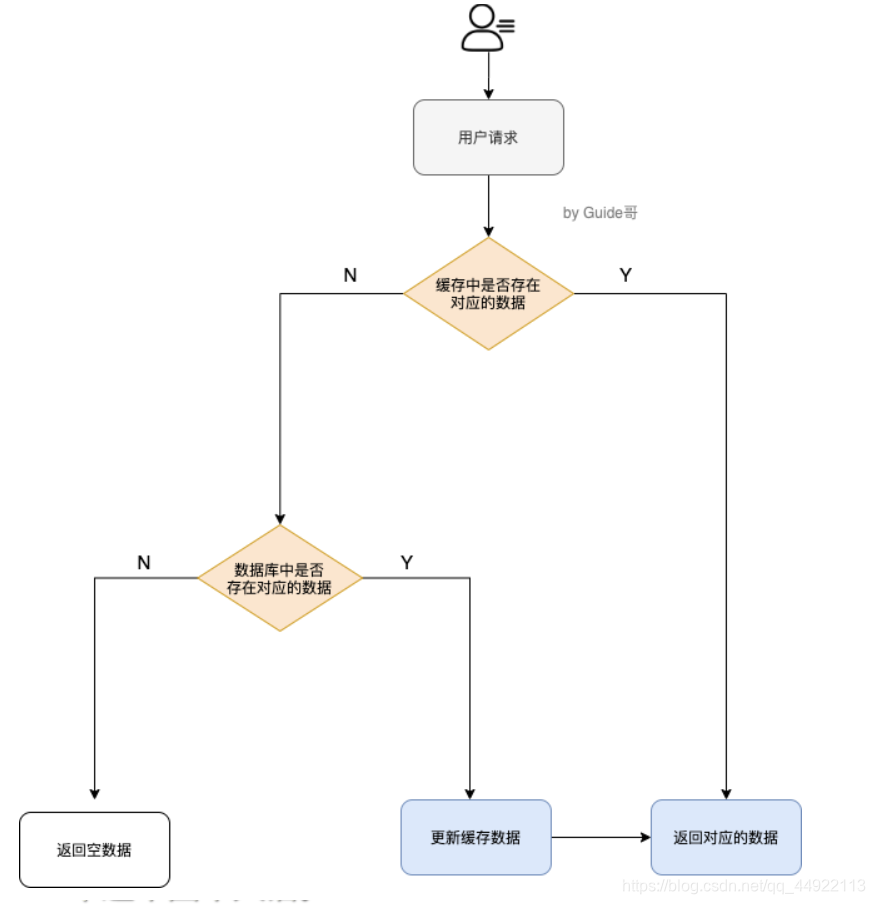
- 如果用户请求的数据在缓存中,那么直接返回就ok
- 如果发现缓存中没有,那么就去查询数据库,看是否可以查询得到
- 数据库存在,则更新到缓存中,同时返回给用户
- 如果数据库也不存在,返回空数据(注意,这块可能会出现缓存击穿问题)
4、为什么要用Redis
两点原因:高性能、高并发
- 高性能
- 假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。操作缓存就是直接操作内存,所以速度相当快。
- 高并发
- 一般像 MySQL 这类的数据库的 QPS(服务器每秒可以执行的查询次数) 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
二、Redis 常见数据结构
1、string
- string 数据结构是简单的 key-value 类型
- 不仅可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)
- 应用场景:一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等
2、list
- 一种双向链表(易于插入和删除,但是随机访问的时间复杂度比较高,双向链表可以支持反向查找和遍历,但因此带来了内存开销)
- 基于这种链式结构,应用于慢查询的场景下以及发布与订阅或者说消息队列。
3、hash
- 数组 + 链表
- 特别适合用来存储对象,比如说用户信息以及商品信息等
4、set
- 类似于Java里面的HashSet
- 应用于:放的数据不能重复以及需要获取多个数据源交集和并集等场景(比如说共同关注、共同的爱好等)
5、zset(sorted set)
- 在set的基础上增加了一个score参数,根据这个score进行排序,也就是说通过这个数据结构得到的数据是有序的
- 应用于对数据根据某个权重进行排序的场景(项目中遇到过,给答题用户进行排名的场景)
三、Redis 单线程模型
- Redis 基于 Reactor(高性能 IO 的基石) 模式来设计开发了自己的一套高效的事件处理模型,对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
- Redis 通过IO 多路复用程序 来监听来自客户端的大量连接。(I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗)
- Redis其实在4.0就支持多线程,不过只是用来对一些大键值对的删除操作
- 在Redis 6 之前不大量使用多线程的原因
- 编程简单易维护
- 引入多线程可能会引起死锁等问题,影响性能
- Redis 6 引入多线程原因
- 主要是为了提升网络I/O读写性能
- 不需要担心线程安全问题:因为Redis的多线程主要使用在网络数据的读写上,执行命令仍然是单线程顺序执行。
- 默认多线程是禁用的,如果需要修改配置文件
io-threads-do-reads yes
- 在Redis 6 之前不大量使用多线程的原因