1、什么是关系抽取
关系抽取的主要任务就是,给定一段句子文本,抽取句子中的两个实体以及实体之间的关系,以次来构成一个三元组(s,p,o),s是subject表示主实体,o为object表示客实体,p为predicate表示两实体间的关系。总的来说,(s, p, o)可以理解的“s的p是o”。 当然一个句子中可能不止两个实体,从而也不止一种关系,所以你要做的就是尽可能多的、且正确的抽取句子中的关系实体对。以中文句子为例,如下图:

上图中的抽取结果就是我们后面提供的代码的抽取结果。可能你会问实体是什么,实体一般指名词性词,如人名、地点名、时间、组织名等。这个关系种类也是由我们事先根据训练集定义好了的,本文采用的训练集共有49+1种关系,1代表没有关系的关系。
那么这种技术的实际应用在哪呢?在知识图谱的构建过程中,一般会用到实体抽取、关系抽取技术,知识图谱的就是由许多节点和边构成的,一个节点就代表一个实体、一条边就代表连接两个实体之间的关系。然后我们可以利用构建好了的知识图谱为基础搭建上层应用,如问答系统、推荐系统等。
2、关系抽取实现
关系抽取的具体实现方式,据我现在了解,有pipeline方法和end2end方法。
2.1.pipeline方法
管道式方法,这种方法就是将关系抽取拆成两个步骤,实体抽取->关系识别,因为这个过程是串联起来的,所以称为pipline方法。整个过程大致是这样的,输入一条句子文本,先用实体抽取器识别出其中的各个实体,然后对抽取出来的实体每两个进行组合在加上原文本句子作为关系识别器的输入进行两输入实体间的关系识别。 此种具体实现方法本文暂且不述。
2.2.end2end方法
端到端的抽取方法,也称为联合抽取方法。只输入一条句子即可,然后从中抽取出实体关系三元组。正如本文上面第一张图展示的那样。下面对本文提供的代码进行讲解,代码来源为github上的某开源代码,数据集为百度2019三元组抽取大赛的数据集(关系种类共50种)。本文主要讲解此代码整个模型架构以及前向传播过程。
代码地址: kg2019-baseline-pytorch
首先是数据集的预处理构建:
对文本数据进行输入的格式还不清楚的,可看看这个文章(句子文本数据如何作为机器学习(深度学习)模型的输入(pytorch))。数据集中有多条句子,同时给出了每条句子的多个三元组关系对。对于每条句子以及其中的所有关系对我们要将它们构造成如下格式:

上面只是每条句子的数据构建过程,在训练时我们都是一批批(batch)进行的,所以我们要将所有句子对应的数据分别构造成一个列表放在一起,如下:
T, S1, S2, K1, K2, O1, O2, = [], [], [], [], [], [], []
.....
......
T.append(t)
S1.append(s1)
S2.append(s2)
K1.append([k1])
K2.append([k2-1])
O1.append(o1)
O2.append(o2)
接着是整个模型的前向传播过程示意图:
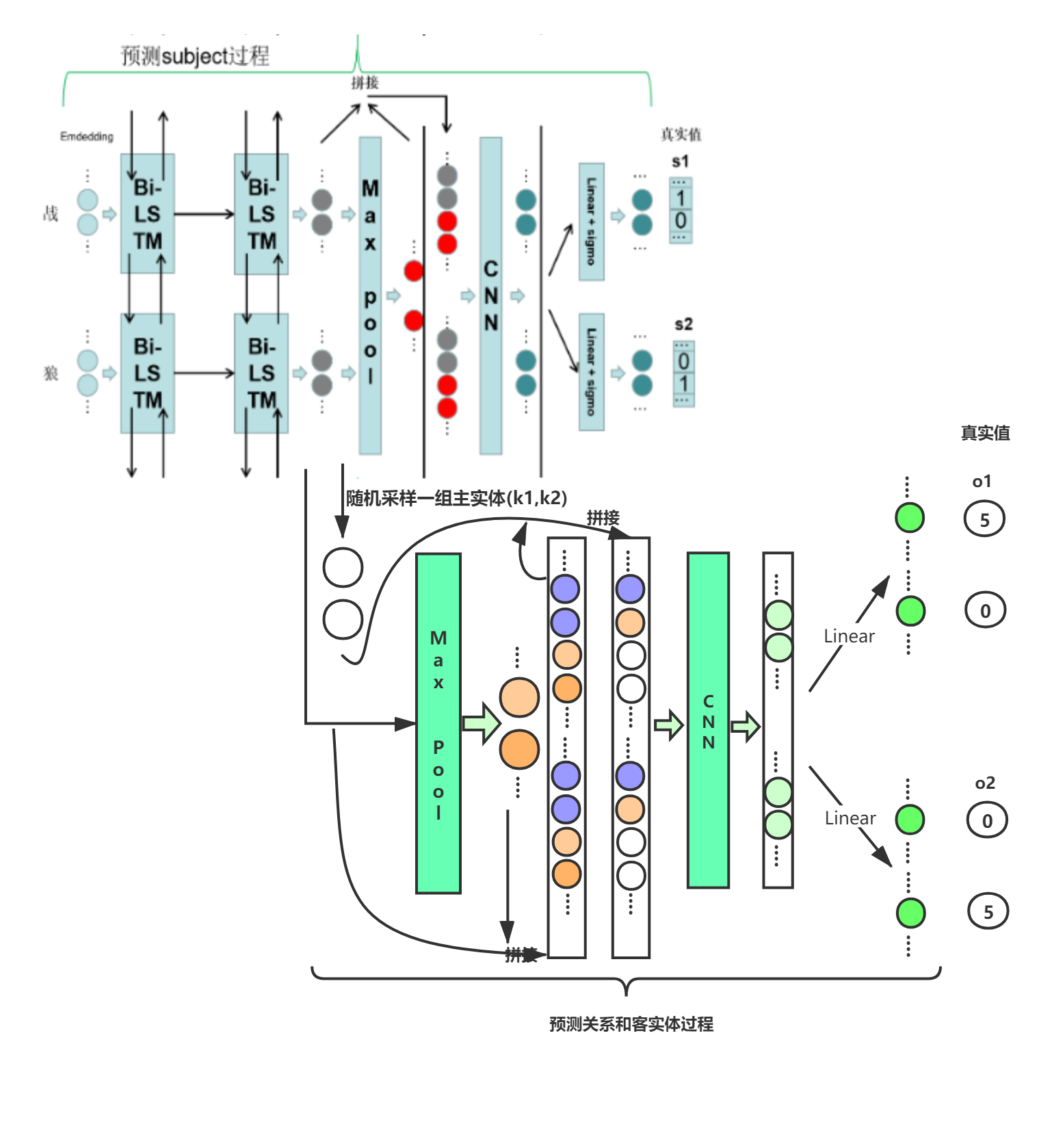
整个过程在代码实现时,分为两个子模型s_model和po_model,s_model为预测主实体的过程,po_model为预测客实体和关系的过程。但这两个模型都共用了同一个序列编码层(也就是两层Bi-Lstm后的输出编码)。此图也是根据模型代码中相应的forward函数流程进行构建的。此模型总的思路在于,先预测主实体,让后根据预测的主实体预测对应的客实体和关系。并且为了预测出多个主实体,在模型s_model的最后一层采用了sigmoid激活函数。