PASCAL VOC为图像识别和分类提供了一整套标准化的优秀数据集,从2005年到2012年每年都会举行一场图像识别challenge。我们可以从这里VOC数据集下载地址下载VOC数据集,主要分为两个年份:2007、2012。
下载完成后,解压,会发现文件夹的内容如下所示:
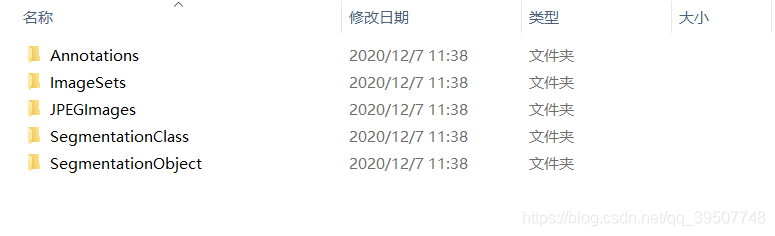
对于目标检测,我们只需要关注前三个文件夹:Annotations、ImageSets和JPEGImages即可。下面就来说一下这三个文件夹的具体内容。
VOCdevkit
——VOC2007 #文件夹的年份可以自己取,但是要与你其他文件年份一致,看下一步就明白了
————Annotations #放入所有的xml文件
————ImageSets
——————Main #放入train.txt,val.txt文件
————JPEGImages #放入所有的图片文件
①Annotations
下图是Annotations文件夹的内容:

Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。下面展示的是第一个xml的具体内容:
<?xml version="1.0"?>
-<annotation>
<folder>VOC2007</folder>
<filename>000005.jpg</filename> //图片名称
-<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>325991873</flickrid>
</source>
-<owner>
<flickrid>archintent louisville</flickrid>
<name>?</name>
</owner>
-<size> //图片尺寸
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
-<object> //图片中包含的在类别中的物体
<name>chair</name> //物体名称
<pose>Rear</pose>
<truncated>0</truncated>
<difficult>0</difficult>
-<bndbox> //该物体的bounding-box,左上角和右下角的坐标
<xmin>263</xmin>
<ymin>211</ymin>
<xmax>324</xmax>
<ymax>339</ymax>
</bndbox>
</object>
-<object>//其他物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
-<bndbox>
<xmin>165</xmin>
<ymin>264</ymin>
<xmax>253</xmax>
<ymax>372</ymax>
</bndbox>
</object>
-<object>//其他物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
-<bndbox>
<xmin>5</xmin>
<ymin>244</ymin>
<xmax>67</xmax>
<ymax>374</ymax>
</bndbox>
</object>
-<object>//其他物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
-<bndbox>
<xmin>241</xmin>
<ymin>194</ymin>
<xmax>295</xmax>
<ymax>299</ymax>
</bndbox>
</object>
-<object>//其他物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
-<bndbox>
<xmin>277</xmin>
<ymin>186</ymin>
<xmax>312</xmax>
<ymax>220</ymax>
</bndbox>
</object>
</annotation>
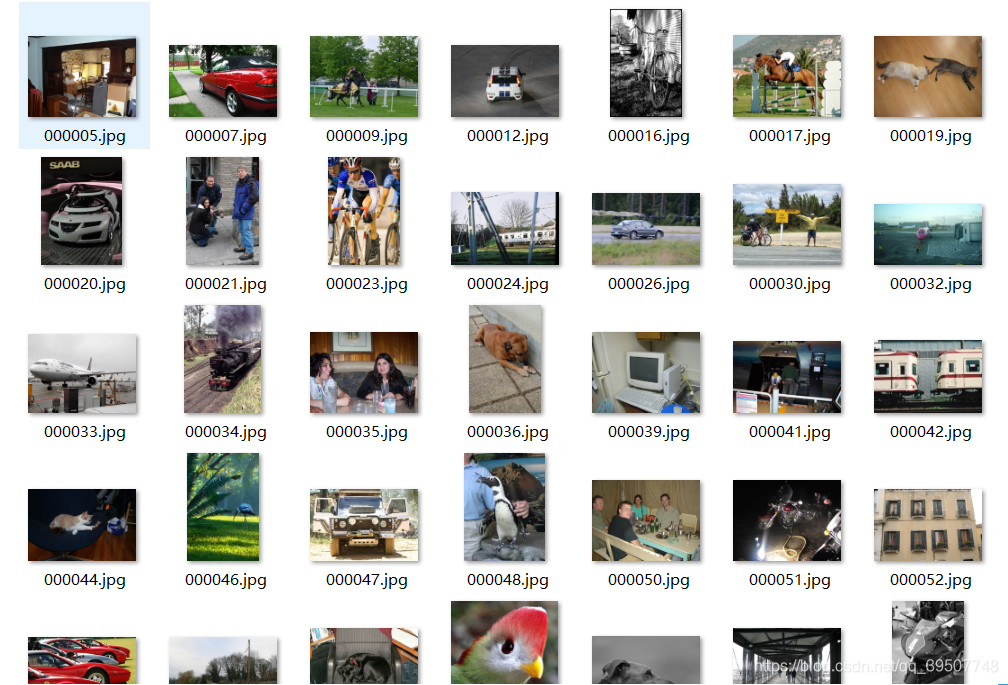
对应的是下面这张000005.jpg。XML文件中存放的是对应照片中所包含的被检测物体的坐标以及类别信息。

②ImageSets
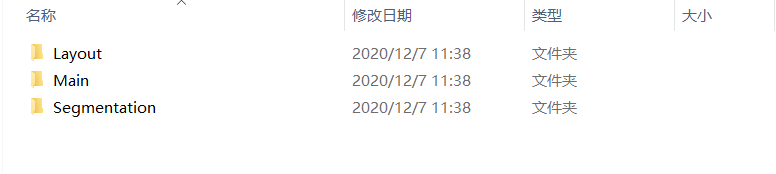
- Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
- Main下存放的是目标检测的数据,总共分为20类。
- Segmentation下存放的是可用于分割的数据。
我们其实只需要关注Main文件夹下的数据即可,如下所示:
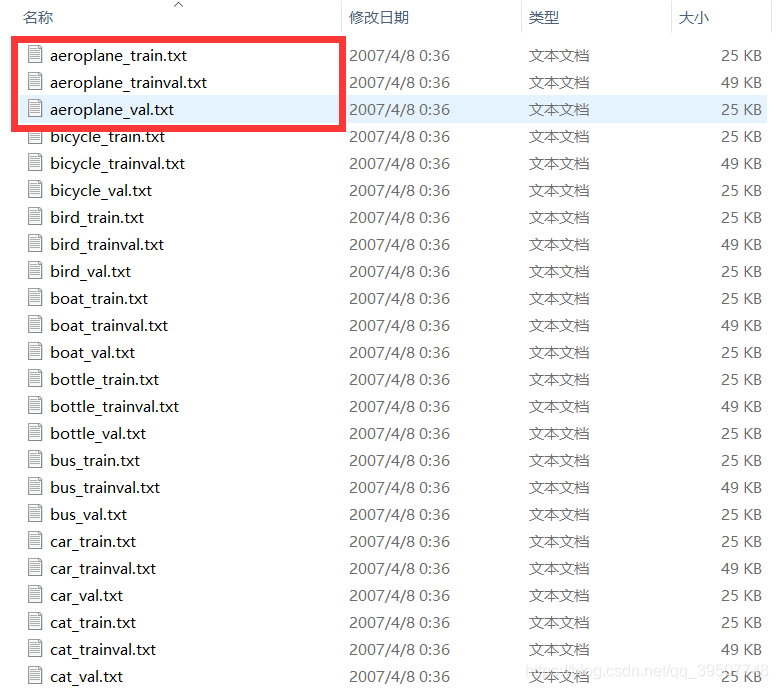
Main文件夹下包含了20个分类的***_train.txt、***_val.txt和***_trainval.txt。
打开其中一个文件的内容如下:

- 前面的数字表示的是图像的name,后面的1代表正样本,-1代表负样本。
- _train.txt中存放的是训练使用的数据,_val.txt中存放的是验证结果使用的数据,_trainval.txt将上面两个进行了合并。
- 还有三个
train.txt、val.txt、trainval.txt文件用来保存所有图片中,哪些图片是被用来训练,哪些图片是被用来验证,保存的内容只是这些图片的name,没有其他更多的信息。
③JPEGImages
JPEGImages文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。可以看到,这里的顺序以及图片的名称和XML文件是对应的。