1 简介
Apache Drill是一个开源的,对于Hadoop和NoSQL低延迟的SQL查询引擎。

Apache Drill 实现了 Google’s Dremel.那么什么是Google’s Dremel?网络中一段描述:Dremel 是Google 的"交互式"数据分析系统。可以组建成规模上千的集群,处理PB级别的数据。MapReduce处理一个数据,需要分钟级的时间。作为MapReduce的发起人,Google开发了Dremel将处理时间缩短到秒级,作为MapReduce的有力补充。Dremel作为Google BigQuery的report引擎,获得了很大的成功。
Apache Drill是一个低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用ANSI SQL兼容语法,支持本地文件、HDFS、HBase、MongoDB等后端存储,支持Parquet、JSON、CSV、TSV、PSV等数据格式。受Google的Dremel启发,Drill满足上千节点的PB级别数据的交互式商业智能分析场景。
(1) Cilent
使用Drill,可以通过以下方式进入到Drill当中,内容如下所示:
Drill shell:使用客户端命令去操作
Drill Web Console:Web UI界面去操作相关内容
ODBC/JDBC:使用驱动接口操作
C++ API:C++的API接口
 (2)核心模块
(2)核心模块

2 下载安装
Drill可以安装在单机或者集群环境上。
网址https://drill.apache.org/。
网址https://drill.apache.org/download/。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/drill/
 # tar -xzvf apache-drill-1.16.0.tar.gz -C /usr/local/
# tar -xzvf apache-drill-1.16.0.tar.gz -C /usr/local/
#cd /usr/local/
#mv apache-drill-1.16.0/ drill
#vi /root/.bashrc
export DRILL_HOME=/usr/local/drill
export PATH=$PATH:$DRILL_HOME/bin
#source /root/.bashrc
3 单机环境运行
无需进行任何配置。
(1)启动
#sqlline -u jdbc:drill:zk=local
 apache drill> !quit退出
apache drill> !quit退出
每次出现的句子都不一样。其中,-u jdbc:drill:zk=local表示使用本机的Drill,无需启动ZooKeeper,即为本地zookeeper服务,本地不用另外配置zookeeper服务。如果是集群环境则需要配置和启动ZooKeeper并填写地址。
(2)查看drill的UI
http://10.23.241.177:8047/
 (3)点开storage页签即可查看当前支持的访问schame
(3)点开storage页签即可查看当前支持的访问schame

4 使用
4.1 本地文件
这里用的库名格式为:
dfs.`本地文件(Parquet、JSON、CSV等文件)绝对路径`
(1)Parquet格式数据
Drill的sample-data目录有Parquet格式的演示数据可供查询:
#sqlline -u jdbc:drill:zk=local
apache drill> !quit退出
apache drill> select * from dfs.`/usr/local/drill/sample-data/nation.parquet` limit 5;
apache drill> select count(*) from dfs.`/usr/local/drill/sample-data/nation.parquet` limit 5;

 Parquet格式文件需要专用工具查看、编辑,不是很方便,先使用更通用的CSV和JSON文件进行演示。
Parquet格式文件需要专用工具查看、编辑,不是很方便,先使用更通用的CSV和JSON文件进行演示。
(2)CSV格式数据
文件test.csv
1101,SteveEurich,Steve,Eurich,16,StoreT
1102,MaryPierson,Mary,Pierson,16,StoreT
1103,LeoJones,Leo,Jones,16,StoreTem
1104,NancyBeatty,Nancy,Beatty,16,StoreT
1105,ClaraMcNight,Clara,McNight,16,Store
查询
apache drill> select * from dfs.`/root/test.csv`;
 结果和之前的稍有不同,因为CSV文件没有地方存放列的列名,所以统一用columns代替,如果需要具体指定列则需要用columns[n]。
结果和之前的稍有不同,因为CSV文件没有地方存放列的列名,所以统一用columns代替,如果需要具体指定列则需要用columns[n]。
apache drill> select columns[0],columns[4] from dfs.`/root/test.csv`;

(3)JSON格式数据
文件test.json。
{
"ka1": 1,
"kb1": 1.1,
"kc1": "vc11",
"kd1": [
{
"ka2": 10,
"kb2": 10.1,
"kc2": "vc1010"
}
]
}
{
"ka1": 2,
"kb1": 2.2,
"kc1": "vc22",
"kd1": [
{
"ka2": 20,
"kb2": 20.2,
"kc2": "vc2020"
}
]
}
可以看到这个JSON文件内容是有多层嵌套的,结构比之前那个CSV文件要复杂不少,而查询嵌套数据正是Drill的优势所在。
apache drill> select * from dfs.`/root/test.json`;
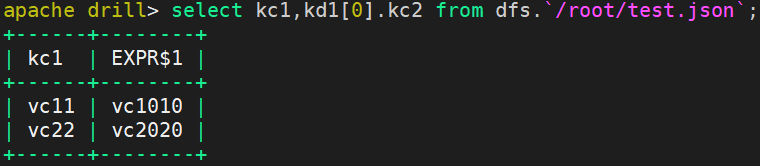
apache drill> select kc1,kd1[0].kc2 from dfs.`/root/test.json`;
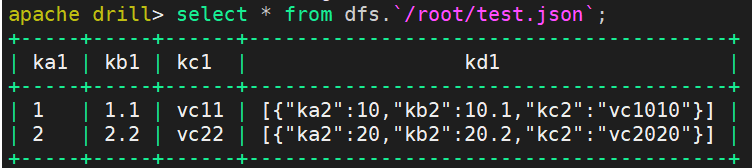 select *只查出第一层的数据,更深层的数据只以原本的JSON数据呈现出来,我们显然不应该只关心第一层的数据,具体怎么查完全随心所欲:可以通过kd1[0]来访问嵌套到第二层的这个表。
select *只查出第一层的数据,更深层的数据只以原本的JSON数据呈现出来,我们显然不应该只关心第一层的数据,具体怎么查完全随心所欲:可以通过kd1[0]来访问嵌套到第二层的这个表。
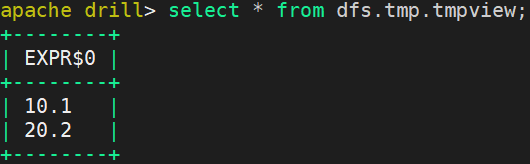
(4)创建view
apache drill> create view dfs.tmp.tmpview as select kd1[0].kb2 from dfs.`/root/test.json`;
apache drill> select * from dfs.tmp.tmpview;
4.2 hdfs
#sqlline -u jdbc:drill:zk=local
http://10.23.241.177:8047/查看drill的UI
打开storage页签,update现有dfs,并可以仿照dfs实例,添加一个访问hdfs的storage plugin 。在最底下输入新的storage plugin 名称,点击create进入下一个页面,然后输入如下信息:
hdfs
{
"type": "file",
"enabled": true,
"connection": "hdfs://pda1:9000/",
"workspaces": {
"root": {
"location": "/",
"writable": true,
"defaultInputFormat": null
}
},
"formats": {
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
"parquet": {
"type": "parquet"
}
}
}
其中“connection”: “hdfs://pda1:9000/” 是指本地的hdfs地址 。
其中“location”: “/opt/drill” 是工作空间,如要将hdfs的数据导出到另外一张表,可以将表导出到hdfs的location目录下 。
其中formats是支持的文件格式。
(1)文件test.csv
1101,SteveEurich,Steve,Eurich,16,StoreT
1102,MaryPierson,Mary,Pierson,16,StoreT
1103,LeoJones,Leo,Jones,16,StoreTem
1104,NancyBeatty,Nancy,Beatty,16,StoreT
1105,ClaraMcNight,Clara,McNight,16,Store
(2)启动hadoop集群
#start-dfs.sh
#start-yarn.sh
#hadoop fs -ls /
#hadoop fs -put /root/test.csv /上传文件
apache drill> select * from hdfs./test.csv;

可独立部署在物理机上,不必与Hadoop集群部署在一起。这里需要注意的是,物理机的内存至少留有4G空闲给Drill去使用。不然,在执行查询操作的时候会内容溢出,查询Drill的官方文档,官方给出的解释是,操作的内容都在内存中完成,不会写磁盘,除非你强制指明去写磁盘,但是,一般考虑到响应速度因素,都会在内存中完成。