假设现在你想写一个机器学习的 pipeline,大概抽象成三个步骤。
读取数据 -> 进行训练 -> 保存模型
要构建完整的 pipeline,需要先考虑构建每个步骤 component 的问题。
构建 pipeline 可以有几种方式,区别在于是否将 Python SDK 的代码嵌入到业务代码里。因为如果你本来就写好了一个 training 的程序,那么这时候就可以直接利用 Docker 镜像,将业务代码封装成一个镜像,无需侵入。另一种方法就是边写 training 程序的时候边把 SDK 中构建 component 的方法带上。
1 文件mnist.py
1.1 安装tensorflow
TensorFlow即可以支持CPU,也可以支持CPU+GPU。前者的环境需求简单,后者需要额外的支持。TensorFlow可以通过两种方式进行安装。一是”native” pip,二是Anaconda。
conda类似于npm或maven的包管理工具,只是conda是针对于python的。
CMD>conda --version【conda 4.7.12】
CMD>>conda info --envs查看已安装的环境变量
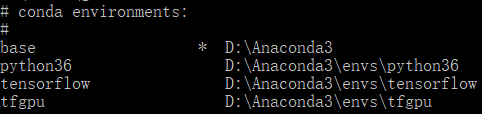
CMD>conda search --full-name python查看可安装的python版本
CMD>conda create --name [name] [dependent package list]创建环境
CMD>conda create --name python36 python=3.6.2
CMD>conda activate python36激活环境
CMD>deactivate退出环境
CMD>conda install --name python36 spyder安装spyder编译器
安装cpu版本的tensorflow。
https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/tensorflow/。
下载链接
https://mirrors.tuna.tsinghua.edu.cn/pypi/web/packages/06/1f/3940c7bb51e1b9cf6e526c84d3239830c8d46c9823a3605945f9abb22411/tensorflow-1.15.2-cp36-cp36m-win_amd64.whl#sha256=b6c57269009a641a74b3456ef7483e69143ed9762af321b0560db5a72cdcb01f
CMD>pip install tensorflow-1.15.2-cp36-cp36m-win_amd64.whl
python【3.6.2】
tensorflow【1.15.2】
import tensorflow as tf
hello=tf.constant('hello tensorflow')
sess=tf.Session()
print(sess.run(hello))
Your CPU supports instructions that this TensorFlow binary was not compiled to use:AVX2
你的CPU支持AVX扩展,但是你安装的TensorFlow版本无法编译使用。
大致的原因就是说:tensorflow觉得你电脑cpu还行,支持AVX(Advanced Vector Extensions),运算速度还可以提升,所以可以开启更好更快的模式,但是你现在用的模式相对来说可能不是那么快,所以这个其实并不是存在错误,所以如果不嫌当前的模式慢就忽略掉这个警告就好了。
要是想忽略掉这个警告也很容易,搜了一下,stack overflow上给的建议是
Just disables the warning, doesn’t enable AVX/FMA
解决办法为:
import os
os.environ[‘TF_CPP_MIN_LOG_LEVEL’] = ‘2’
这行代码是用于设置TensorFlow的日志级别的。
1.2 公网下载数据
这是一段很经典的mnist数据集训练的代码。
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
import tensorflow as tf
def train_model():
mnist = tf.keras.datasets.mnist
# 公网下载数据,数据量不大十多兆
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
if __name__ == '__main__':
train_model()
1.3 本地加载数据
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
import tensorflow as tf
import numpy as np
# 本地加载数据文件mnist.npz
def load_mnist():
path = 'mnist.npz' # 放置mnist.py的目录。
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
def train_model():
(x_train, y_train), (x_test, y_test) = load_mnist()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
if __name__ == '__main__':
train_model()
2 封装成一个component
目标:需要把这个训练过程,放在Pipeline上运行,所以将mnist.py的代码封装成一个component,然后再构架pipeline,为了方便,依然是构建一个包含一个component的pipeline。

2.1 制作镜像
#docker pull tensorflow/tensorflow:1.13.2-py3
#mkdir mytest
#cd mytest/
#vi mnist.py
#chmod a+x mnist.py
#vi Dockerfile
FROM tensorflow/tensorflow:1.13.2-py3
ADD mnist.py .
ADD mnist.npz .
ENTRYPOINT ["python", "mnist.py"]
#docker build -t mnist:v1.0 .
#docker save -o mnist-v1.0.tar mnist:v1.0
2.2 制作pipeline
import kfp
@kfp.dsl.component
def train_mnist_op():
return kfp.dsl.ContainerOp(
name='mnist',
image='mnist:v1.0')
@kfp.dsl.pipeline(
name='mnist train',
description='my first test'
)
def my_pipeline():
op = train_mnist_op()
if __name__ == '__main__':
pipeline_func = my_pipeline
pipeline_filename = pipeline_func.__name__ + '.yaml'
kfp.compiler.Compiler().compile(pipeline_func,pipeline_filename)
#创建实验
client = kfp.Client()
try:
experiment = client.create_experiment("mnist experiment")
except Exception:
experiment = client.get_experiment(experiment_name="mnist experiment")
#运行作业
run_name = pipeline_func.__name__ + ' test_run'
run_result = client.run_pipeline(experiment.id, run_name, pipeline_filename)
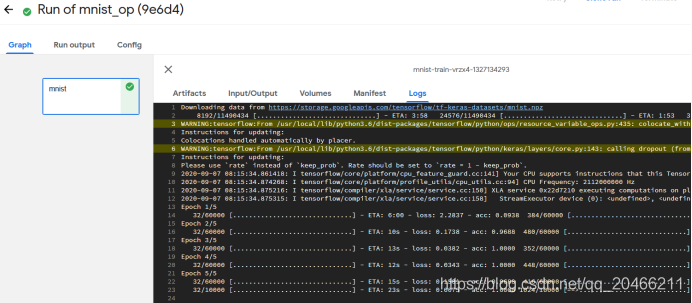 按照流程,可以创建一个非常简捷的ML Pipeline了,当然一个完整的流程,会切分成读取数据,清洗数据(Transform),训练,然后输出模型,可以按照上述流程,分别构建component,然后最终构建起自己的pipeline。
按照流程,可以创建一个非常简捷的ML Pipeline了,当然一个完整的流程,会切分成读取数据,清洗数据(Transform),训练,然后输出模型,可以按照上述流程,分别构建component,然后最终构建起自己的pipeline。
3 封装三个component
划分业务流程制作业务镜像,将实验流程分成了数据加载、模型训练、测试数据预测三个环节。
3.0 kfp.dsl.ContainerOp.add_volume()
add_volume(self, volume)
Add K8s volume to the container
Args:
volume: Kubernetes volumes
For detailed spec, check volume definition
https://github.com/kubernetes-client/python/blob/master/kubernetes/client/models/v1_volume.py
Kubernetes的volume,有着明显的生命周期——和使用它的pod生命周期一致。因此,volume生命周期就比运行在pod中的容器要长久,即使容器重启,volume上的数据依然保存着。当然,pod不再存在时,volume也就消失了。更重要的是,Kubernetes支持多种类型的volume,并且pod可以同时使用多种类型的volume。
内部实现中,volume只是一个目录,目录中可能有一些数据,pod的容器可以访问这些数据。这个目录是如何产生的,它后端基于什么存储介质,其中的数据内容是什么,这些都由使用的特定volume类型来决定。
3.1 数据加载
3.1.1 文件load_data.py
#encoding:utf8
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
import argparse
import numpy as np
# 本地加载数据文件mnist.npz
def load_data(path):
with np.load(path) as f:
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
return (x_train, y_train), (x_test, y_test)
# 进行数据转换
def transform(output_dir, file_name):
x_train_name = 'x_train.npy'
x_test_name = 'x_test.npy'
y_train_name = 'y_train.npy'
y_test_name = 'y_test.npy'
(x_train, y_train), (x_test, y_test) = load_data(output_dir + file_name)
# 注意output_dir需要添加/斜杠。
x_train, x_test = x_train / 255.0, x_test / 255.0
np.save(output_dir + x_train_name, x_train)
np.save(output_dir + x_test_name, x_test)
np.save(output_dir + y_train_name, y_train)
np.save(output_dir + y_test_name, y_test)
#将路径和文件名写入train_test_data.txt文件中
with open(output_dir + 'train_test_data.txt', 'w') as f:
f.write(output_dir + x_train_name + ',')
f.write(output_dir + x_test_name + ',')
f.write(output_dir + y_train_name + ',')
f.write(output_dir + y_test_name)
def parse_arguments():
"""Parse command line arguments."""
parser = argparse.ArgumentParser(description='Kubeflow MNIST load data')
parser.add_argument('--data_dir', type=str, required=True, help='local file dir')
parser.add_argument('--file_name', type=str, required=True, help='local file to be input')
args = parser.parse_args()
return args
def run():
args = parse_arguments()
transform(args.data_dir, args.file_name)
if __name__ == '__main__':
run()
3.1.2 Dockerfile文件
FROM tensorflow/tensorflow:1.13.2-py3
ADD load_data.py .
ENTRYPOINT ["python", "load_data.py"]
#docker build -t mnist-load_data:v1.0 .
#docker save -o mnist-load_data-v1.0.tar mnist-load_data:v1.0
#scp mnist-load_data-v1.0.tar root@myworker:/root
3.1.3 pipeline文件
#encoding:utf8
import kfp
client = kfp.Client()
from kubernetes import client as k8s_client
exp = client.create_experiment(name='mnist_experiment')
class load_dataOp(kfp.dsl.ContainerOp):
"""load raw data from tensorflow, do data transform"""
def __init__(self, data_dir, file_name):
super(load_dataOp, self).__init__(
name='load_data',
image='mnist-load_data:v1.0',
arguments=[
'--file_name', file_name,
'--data_dir', data_dir,
],
file_outputs={
'data_file': data_dir + 'train_test_data.txt'
})
@kfp.dsl.pipeline(
name='MnistStage',
description='shows how to define dsl.Condition.'
)
def MnistTest():
data_dir = '/some/path/'
file_name = 'mnist.npz'
load_data = load_dataOp(data_dir, file_name).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
kfp.compiler.Compiler().compile(MnistTest, 'mnist.tar.gz')
run = client.run_pipeline(exp.id, 'mylove', 'mnist.tar.gz')
3.2 模型训练
3.2.1 文件train.py
#encoding:utf8
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
import tensorflow as tf
import numpy as np
import argparse
def train(output_dir, data_file):
"""
all file use absolute dir
:param output_dir:
:param data_file: `train_test_data.txt` absolute dir
"""
with open(data_file, 'r') as f:
line = f.readline()
data_list = line.split(',')
with open(data_list[0], 'rb') as f:
x_train = np.load(f)
with open(data_list[2], 'rb') as f:
y_train = np.load(f)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 训练模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
# 保存模型
model_name = "model.h5"
model.save(output_dir + model_name)
with open(output_dir + 'model.txt', 'w') as f:
f.write(output_dir + model_name)
def parse_arguments():
"""Parse command line arguments."""
parser = argparse.ArgumentParser(description='Kubeflow MNIST train model script')
parser.add_argument('--data_dir', type=str, required=True, help='local file dir')
parser.add_argument('--data_file', type=str, required=True, help='a file write train and test data absolute dir')
args = parser.parse_args()
return args
def run():
args = parse_arguments()
train(args.data_dir, args.data_file)
if __name__ == '__main__':
run()
3.2.2 Dockerfile文件
FROM tensorflow/tensorflow:1.13.2-py3
ADD train.py .
ENTRYPOINT ["python", "train.py"]
#docker build -t mnist-train:v1.0 .
#docker save -o mnist-train-v1.0.tar mnist-train:v1.0
#scp mnist-train-v1.0.tar root@myworker:/root
3.2.3 pipeline文件
#encoding:utf8
import kfp
client = kfp.Client()
from kubernetes import client as k8s_client
exp = client.create_experiment(name='mnist_experiment')
class trainOp(kfp.dsl.ContainerOp):
"""train keras model"""
def __init__(self, data_dir, data_file):
super(trainOp, self).__init__(
name='train',
image='mnist-train:v1.0',
arguments=[
'--data_dir', data_dir,
'--data_file', data_file,
],
file_outputs={
'model_file': data_dir + 'model.txt'
})
@kfp.dsl.pipeline(
name='MnistStage',
description='shows how to define dsl.Condition.'
)
def MnistTest():
data_dir = '/some/path/'
data_file = data_dir + 'train_test_data.txt'
train = trainOp(data_dir, data_file).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
kfp.compiler.Compiler().compile(MnistTest, 'mnist.tar.gz')
run = client.run_pipeline(exp.id, 'mylove', 'mnist.tar.gz')
3.3 数据预测
3.3.1 文件predict.py
#encoding:utf8
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
import argparse
import numpy as np
import pandas as pd
import tensorflow as tf
def predict(output_dir, model_file, data_file):
"""
all file use absolute dir
:param output_dir:
:param model_file: `model.txt` absolute dir
:param data_file: `train_test_data.txt` absolute dir
:return:
"""
with open(model_file, 'r') as f:
line = f.readline()
model = tf.keras.models.load_model(line)
with open(data_file, 'r') as f:
line = f.readline()
data_list = line.split(',')
with open(data_list[1], 'rb') as f:
x_test = np.load(f)
with open(data_list[3], 'rb') as f:
y_test = np.load(f)
pre = model.predict(x_test)
model.evaluate(x_test, y_test)
df = pd.DataFrame(data=pre,
columns=["prob_0", "prob_1", "prob_2", "prob_3", "prob_4", "prob_5", "prob_6", "prob_7", "prob_8",
"prob_9"])
y_real = pd.DataFrame(data=y_test, columns=["real_number"])
result = pd.concat([df, y_real], axis=1)
# 预测结果写入文件result.csv中
result.to_csv(output_dir + 'result.csv')
# 预测结果的路径和文件名写入result.txt中
with open(output_dir + 'result.txt', 'w') as f:
f.write(output_dir + 'result.csv')
def parse_arguments():
"""Parse command line arguments."""
parser = argparse.ArgumentParser(description='Kubeflow MNIST predict model script')
parser.add_argument('--data_dir', type=str, required=True, help='local file dir')
parser.add_argument('--model_file', type=str, required=True, help='a file write trained model absolute dir')
parser.add_argument('--data_file', type=str, required=True, help='la file write train and test data absolute dir')
args = parser.parse_args()
return args
def run():
args = parse_arguments()
predict(args.data_dir, args.model_file, args.data_file)
if __name__ == '__main__':
run()
3.3.2 Dockerfile文件
FROM tensorflow/tensorflow:1.13.2-py3
RUN pip3 config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip3 config set install.trusted-host mirrors.aliyun.com
RUN pip3 install pandas
ADD predict.py .
ENTRYPOINT ["python", "predict.py"]
#docker build -t mnist-predict:v1.0 .
#docker save -o mnist-predict-v1.0.tar mnist-predict:v1.0
#scp mnist-predict-v1.0.tar root@myworker:/root
3.3.3 pipeline文件
#encoding:utf8
import kfp
client = kfp.Client()
from kubernetes import client as k8s_client
exp = client.create_experiment(name='mnist_experiment')
class predictOp(kfp.dsl.ContainerOp):
"""get predict by trained model"""
def __init__(self, data_dir, model_file, data_file):
super(predictOp, self).__init__(
name='predict',
image='mnist-predict:v1.0',
arguments=[
'--data_dir', data_dir,
'--model_file', model_file,
'--data_file', data_file
],
file_outputs={
'result_file': data_dir + 'result.txt'
})
@kfp.dsl.pipeline(
name='MnistStage',
description='shows how to define dsl.Condition.'
)
def MnistTest():
data_dir = '/some/path/'
data_file = data_dir + 'train_test_data.txt'
model_file = data_dir + "model.txt"
predict = predictOp(data_dir, model_file, data_file).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
kfp.compiler.Compiler().compile(MnistTest, 'mnist.tar.gz')
run = client.run_pipeline(exp.id, 'mylove', 'mnist.tar.gz')
3.4 合并pipeline
#encoding:utf8
import kfp
client = kfp.Client()
from kubernetes import client as k8s_client
exp = client.create_experiment(name='mnist_experiment')
class load_dataOp(kfp.dsl.ContainerOp):
"""load raw data from tensorflow, do data transform"""
def __init__(self, data_dir, file_name):
super(load_dataOp, self).__init__(
name='load_data',
image='mnist-load_data:v1.0',
arguments=[
'--file_name', file_name,
'--data_dir', data_dir,
],
file_outputs={
'data_file': data_dir + 'train_test_data.txt'
})
class trainOp(kfp.dsl.ContainerOp):
"""train keras model"""
def __init__(self, data_dir, data_file):
super(trainOp, self).__init__(
name='train',
image='mnist-train:v1.0',
arguments=[
'--data_dir', data_dir,
'--data_file', data_file,
],
file_outputs={
'model_file': data_dir + 'model.txt'
})
class predictOp(kfp.dsl.ContainerOp):
"""get predict by trained model"""
def __init__(self, data_dir, model_file, data_file):
super(predictOp, self).__init__(
name='predict',
image='mnist-predict:v1.0',
arguments=[
'--data_dir', data_dir,
'--model_file', model_file,
'--data_file', data_file
],
file_outputs={
'result_file': data_dir + 'result.txt'
})
@kfp.dsl.pipeline(
name='MnistStage',
description='shows how to define dsl.Condition.'
)
def MnistTest():
data_dir = '/some/path/'
file_name = 'mnist.npz'
load_data = load_dataOp(data_dir, file_name).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
train = trainOp(data_dir, load_data.file_outputs['data_file']).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
predict = predictOp(data_dir, train.file_outputs['model_file'], load_data.file_outputs['data_file']).add_volume(
k8s_client.V1Volume(name='mnist-pv',
nfs=k8s_client.V1NFSVolumeSource(
path='/some/path/',
server='mymaster'))).add_volume_mount(
k8s_client.V1VolumeMount(mount_path='/some/path/', name='mnist-pv'))
train.after(load_data)
predict.after(train)
kfp.compiler.Compiler().compile(MnistTest, 'mnist.tar.gz')
run = client.run_pipeline(exp.id, 'mylove', 'mnist.tar.gz')
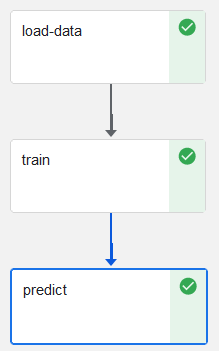
(1)需要指定运行的顺序
train.after(load_data)
predict.after(train)
(2)代码中使用argparse,可以通过rest api的方式传入路径和数据参数运行代码。
(3)代码的运行将在容器中进行,在这里使用NFS挂载k8s集群路径作为文件存储的固定地址。
(4)代码中将分割数据集的绝对路径写入train_test_data.txt ,方便后续环节引用,同时便于与后续环节构成流程关系。