知识大纲
- 熟悉基本 SQL 操作包括增删改查(insert、delete、update、select语句),排序 order,条件查询(where 子语句),限制查询结果数量(LIMIT语句)等
- 稍微高级一点的 SQL 操作(如Group by,in,join,left join,多表联合查询,别名的使用,select 子语句等)
- 索引的概念、索引的原理、索引的创建技巧
- 数据库本身的操作,建库建表,数据的导入导出
- 数据库用户权限控制(权限机制)
- MySQL的两种数据库引擎的区别
- SQL 优化技
- MySQL索引方法?索引的优化?
- InnoDB与MyISAM区别?
- 事务的ACID
- 事务的四个隔离级别
- 查询优化(从索引上优化,从SQL语言上优化)
- B-与B+树区别?
- MySQL的联合索引(又称多列索引)是什么?生效的条件?
- 分库分表
MySQL 数据库增删改查语句
查看数据库
show databases; 使用数据库
use 数据库名;创建数据库
DROP DATABASE 数据库名;创建表
create table 表名(
列名1 类型(长度) [约束],
列名2 类型(长度) [约束],
……
);
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);长度区别
int类型带长度:不影响存取值,即使设定的值超出了长度的范畴,也能存,如果没有达到设定的长度,则使用空格自动填充到设定的长度
char类型:不可变字符,设定的长度就是规定当前字段能存的数据的最大长度,若超出长度,则会报错,若没有达到长度,使用空格填充到设定的长度
varchar:可变字符,设定的长度同样是规定当前字段能存的数据的最大长度,若超出长度,则会报错,若没有达到长度,不会使用空格填充,实际多长就是多长
删除表
DROP TABLE 表名;表约束
1.非空约束 NOT NULL
2.默认值约束 DEFAULT '男'
3.唯一约束 UNIQUE
4.主键约束 PRIMARY KEY查看表结构
DESC 表名修改表
修改列名
Alter table 表名 change 列名 列名 新类型;修改列类型
Alter table 表名 modify 列名 新类型;查询表中全部信息
select * from 表名;查询表中指定列的信息
select 列1,列2 from 表名;语句的执行顺序:from—>select
数据去重
select distinct 列…. From 表名;拼接结果
select concat(列1,列2) from 表名;条件查询
select 列… from 表名 where 条件; 条件中比较运算符:( 等于:= 大于:> 大于等于:>= 小于:< 小于等于:<= 不等于:!= 或 <> )
where 列 比较运算符 值;注意:字符串、日期需使用单引号括起来
语句的执行顺序:from—>where—>select
逻辑运算符( 并且:and 或 && 或:or 非:not 或 ! )
where 条件1 逻辑运算符 条件2;
where not 条件; 范围查询
where 列 between 条件1 and 条件2; //列在这个区间的值
where 列 not between 条件1 and 条件2; //不在这个区间
where !( 列 between 条件1 and 条件2 ); //同样表示不在这个区间集合查询( 判断列的值是否在指定的集合中 )
where 列 in(值1,值2); //列中的数据是in后的值里面的
where 列 not in(值1,值2); //不是in中指定值的数据NULL值查询( 注意:列中值为null不能使用=去查询 )
where 列 is null; //查询列中值为null的数据模糊查询
%:表示0到多个字符,示例:
where 列 like '%0'; //表示以0结尾
where 列 like '0%'; //表示以0开头
where 列 like '%0%'; //表示数据中包含0_:表示一个字符,可多次使用,示例:
where 列 like '%0_'; //数据结尾第二位是0结果排序( 对查询出的结果按照一列或多列进行升序还是降序排列 升序:asc 降序:desc 注意:不能使用中文的别名排序)
where 条件 order by 列 [asc/desc]语句的执行顺序:from—>where—>select—>order by
分页查询( beginIndex:表示从第多少条数据开始 pageSize:表示每页显示的数据条数 )
where [条件] limit beginIndex,pageSize;ex:每页显示3条数据
第一页: SELECT * FROM 表名 LIMIT 0,3 --0,1,2
第二页: SELECT * FROM 表名 LIMIT 3,3 --3,4,5
第三页: SELECT * FROM 表名 LIMIT 6,3 --6,7,8
第四页: SELECT * FROM 表名 LIMIT 9,3 --9,10,11
……
第七页: SELECT * FROM 表名 LIMIT 18,3 --18,19,20
beginIndex公式:(当前页数-1)*pageSize
聚集函数( 作用于一组数据,并对一组数据返回一个值 )
COUNT:统计结果记录数,若统计的是列,列中为Null,那么count将不会计算值
MAX: 统计计算最大值
MIN: 统计计算最小值
SUM: 统计计算求和
AVG: 统计计算平均值分组函数( 注意:如果要对分组后的数据进行筛选,那么必须使用having关键字,条件写在having后 )
select 聚集函数 from 表名 where [条件] group by 列 having 分组后的条件语句的执行顺序:FROM—> WHERE—>group by---->Having—>SELECT-->ORDER BY
===============================数据查询-多表===============================
交叉连接:又名笛卡尔积,使用交叉连接会产生笛卡尔积
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
select * from 表1,表2内连接:过滤为空的数据(查询的实际上是两张表数据的交集部分) 目的 ==》解决笛卡尔积现象,正确查询了需要的数据
select * from 表1,表2 where 表1.字段=表2.字段; //隐式内连接,使用where条件消除笛卡尔积
select * from 表1 [inner] join 表2 on 表1.字段=表2.字段; //显式内连接,如果是多张表,则一直在join..on后依次添加join..on即可,inner关键字可被省略外连接:左外连接、右外连接、全外连接
左外连接:以左边表为主,返回左边表中所有数据,若右表中无数据,则显示为NULL,请参考实际查询结果来理解
select * from 表1 left [outer] join 表2 on 表1.字段=表2.字段; //表1为左表,表2为右表,outer关键字可被省略右外连接:以右边表为主,返回右表中所有数据,若左表中无数据,则显示为NULL,结合实际查询结果来理解
select * from 表1 right [outer] join 表2 on 表1.字段=表2.字段; //表1为左表,表2为右表,outer关键字可被省略全外连接:返回涉及的多表中的所有数据,MYSQL中不支持该查询,仅限了解自连接:单表当作多表查询,直白的讲就是一张表中数据含有多种关系,使用多表查询的语法,来查询一张表,查询过程中一定要使用别名
多用在分类数据、省市县分类数据、权限…
select 表1.字段1,表2.字段2 from 表名 as 表1,表名 as 表2 where 表1.字段1=表2.字段2子查询:将一个查询结果作为另一个查询的对象,直白的讲就是SQL语句嵌套
select * from (select * from 表名) as 别名
select * from where 条件->条件中包含查询语句注意:1.查询结果的虚拟表必须取别名
2.字段与关键字一样,冲突时,需要给字段名加``,(Esc键下面、1的左边)
3.如果给虚拟结果表中的字段取了别名,则对虚拟结果表查询时,应该用 表别名.虚拟表字段别名
===============================插入数据===============================
insert into 表名(字段1,字段2..) values(值1,值2…); 注意: 1.如果插入的表中的主键是自增类型的,可以不用插入值
2.如果主键是非自增 ,插入的数据则是填补主键字段值空余的值
3.如果主键设置了自动递增,会从主键字段最大值开始插入数据
其他插入方式:
insert into 表名(字段1,字段2) values(值1,值2),(值1,值2); //插入多条数据【MYSQL】
insert into 表名 values(值1,值2); //针对全表所有字段进行插入操作
insert into 表名(字段) select 字段 from 表2; //查询结果插入
insert into 表名 select 字段 from 表2; //查询结果,全表插入===============================修改数据===============================
update 表 set 字段=值 where 条件; //带条件修改指定数据,否则修改全表===============================删除数据===============================
delete from 表 where 条件; //删除数据带条件指定数据,否则删除全表数据===============================数据备份===============================
在命令行窗口进行,若操作系统版本高,则使用管理员模式
导出:
mysqldump -u账户 -p密码 数据库名称>脚本文件存储地
ex: mysqldump -uroot -proot jdbcdemo> C:/shop_bak.sql
导入:
mysql -u账户 -p密码 数据库名称< 脚本文件存储地址
ex: mysql -uroot -proot jdbcdemo< C:/shop_bak.sql
使用可视化导入导出:
Navicat工具的导入和导出/Navicat工具的备份和还原
===============================数据索引===============================
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容
什么列适合建索引??
1.表的主键、外键必须有索引;
2.数据量超过30000的表应该有索引;
3.经常与其他表进行连接的表,在连接字段上应该建立索引;
4.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5.索引应该建在选择性高的字段上;
6.索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
sql语句创建和删除索引:
创建索引:
CREATE INDEX 索引名称 ON 表名 (列名)删除索引:
方式一:
DROP INDEX 索引名 ON 表名 方式二:
ALTER TABLE 表名 DROP INDEX 索引名MySQL的架构
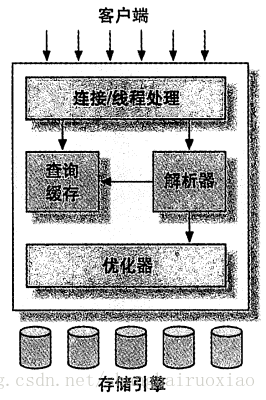
MySQL的架构分三层,最上层是采用客户端和服务端的交互模式,响应请求;中间层是核心,用于实现查询解析,缓存,优化等;第三层是存储引擎,负责数据的存储和提取。
索引方法
顺序索引(稠密索引和稀疏索引)
顺序索引的方式和操作系统内存管理的分页机制比较相似。稠密索引就是给每一个数据块建一个指针,把指针顺序摆放在一起就是索引了。稀疏索引,要求数据块本身是聚集堆放的,找到最大的小于要查询值的指针,然后循序遍历至找到目标为止。对于文件过大的时候,索引本身就很庞大,因此又建立了分级索引。
B树索引/B+树索引
B树索引,实际上是分为B树索引和B+树索引两种方法。MySQL用的B+树,MongoDB用的B树。关于B数和B+树如何索引,给大家安利两篇文章,写的通俗易懂。
- 就是Btree
- 相比磁盘IO速度,内存耗时几乎可以忽略
- 磁盘的IO和树的层高有关系
- Btree可以一直自平衡
- 应用于MongoDB

- 叶子节点包含了全部的信息
- 叶子节点形成了有序的列表
- 卫星数据指的是,索引元素所指向的数据记录,比如数据库重的某一行
- btree所有节点都有卫星数据,b+tree只有叶子节点有卫星数据
- 用b+tree可以提升性能,因为b+tree中间的节点没有卫星数据,所以磁盘页可以容纳更多的节点元素,因此相同的数据量,B+tree比btree查询IO次数更少
- 其次,btree中间节点,b+tree要找到叶子节点,b性能并不稳定
- 所有叶子节点形成有序链表,便于范围查询
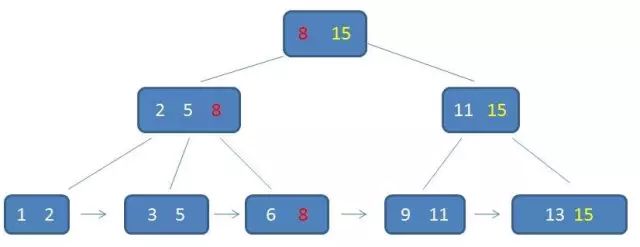
为什么选择B树?
(1) 对于数据库查找,索引的文件都存在磁盘上,磁盘IO的是非常消耗时间的,因此要减少磁盘IO的次数,而B数相比于二叉树,或者其变种AVL和RD-Tree的高度更低,因此磁盘IO的次数更好;
(2) B数是平衡树,查找,删除和插入是相对稳定的。
为什么选择B+树
(1) B+树所有的数据都保存在叶节点上,查找数据都必须到达叶子节点,因此其查找效率是恒定的;
(2) B+树的叶子节点有指针指向下一个叶子节点,形成了一个链表。而叶子节点间又是排序的,因此对于范围查找只需要先找到头的位置,然后遍历链表就可以了;
(3) B+树的非叶子节点不需要存储数据,只作为索引,因此B+数的阶数可以更高,故单个节点保存的数据个数会更多,使得B+树更加矮胖,因此磁盘IO的次数会更少。
哈希索引
散列索引就比较好理解了,实际就是在哈希表中保存文件的指针。所遇到的问题和哈希表中存在的问题是相同,如何选择好的哈希函数,数据过大后如果扩容,扩容的过程中有拷贝如何提高扩容的效率。当超过了装载因子后,可以新建一个更大的哈希表,但是并不一次性拷贝全部数据,而是当要插入或删除某个数据时,就将该桶中的所有数据拷贝。
哈希索引必须要匹配所有的关键词,才能使用索引,因为哈希值是由所有的关键词共同来实现的。而B+树索引,是分层索引,可以先匹配第一个关键词,再匹配第二个关键词。但是不能跨级索引,比如没有第一个关键词,直接通过第二个关键词索引。
在InnoDB引擎使用的是B+树索引,但是会自动为查询频繁的数据建立一个哈希索引,提高效率。
事务的ACID特性
- 事物:构成单一逻辑工作单元的操作集合
- ACID特性
(1) 原子性(Atomicity):一个事务是不可分割的,要么都发生,要么都不发生;
(2) 一致性(Consistency):事务开始和结束前后,数据保存一致性,A和B转账,必须保证转账前后A和B账户的总额不变;
(3) 隔离性(Isolation):多个事务并发执行,避免事务之间的干扰。一个事务在提交前所做的修改对其他事务通常是不可见的;
(4) 持久性(Durability):事务一旦提交,所做的修改就永久保存在数据库中,即使此时服务器崩溃,修改的数据也不会丢失。
隔离级别
- 未提交读:事务中的修改,即使没有提交,对其他事务也都是可见的。读取未提交的数据,称为脏读。这个级别性能并没有好太多,但是却会带来很多问题,一般很少使用。
- 已提交读:解决了脏读的问题,一个事务开始后所做的修改在提交前对其他事务是不可见的,但是不保证在一个事务中执行两次相同的查询,其结果相同,也就是所谓的不可重复读。
- 可重复读:解决了重复读的问题,可以保证在一个事务中对同一数据的查询结果是一致的。它是MySQL的默认隔离级别。但是可能会出现幻读。幻读是指对一个范围内数据进行读取时,另外 一个事务插入了新行,再次读取时发现刚插入的那行没有被改变,像产生了幻觉一样,称为幻读。解决幻读的问题,可以通过加范围锁,锁住要修改的范围行区间。
- 可串行化:对行进行加锁读,可能会导致锁超时。
由上到下隔离级别依次升高。但都不允许脏写。隔离级别越低,支持的并发就越高,而且系统的开销也更小。
MySQL执行流程

- MySQL客户端通过协议将SQL语句发送给MySQL服务器。
- 服务器会先检查查询缓存中是否有执行过这条SQL,如果命中缓存,则将结果返回,否则进入下一个环节(查询缓存默认不开启)。
- 服务器端进行SQL解析,预处理,然后由查询优化器生成对应的执行计划。
- 服务器根据查询优化器给出的执行计划,再调用存储引擎的API执行查询。
- 将结果返回给客户端,如果开启查询缓存,则会备份一份到查询缓存中。
MySQL引擎InnoDB,MyISAM区别
区别
- InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
- InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
- Innodb锁的粒度更细,支持行锁,MyISAM不支持。
如何选择
- 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB。
- 系统奔溃后,MyISAM恢复起来更困难,能否接受;
- MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
- 数据量较大(3TB以上)时不要用MyISAM,崩溃后难以恢复。