1 SparkStreaming概述
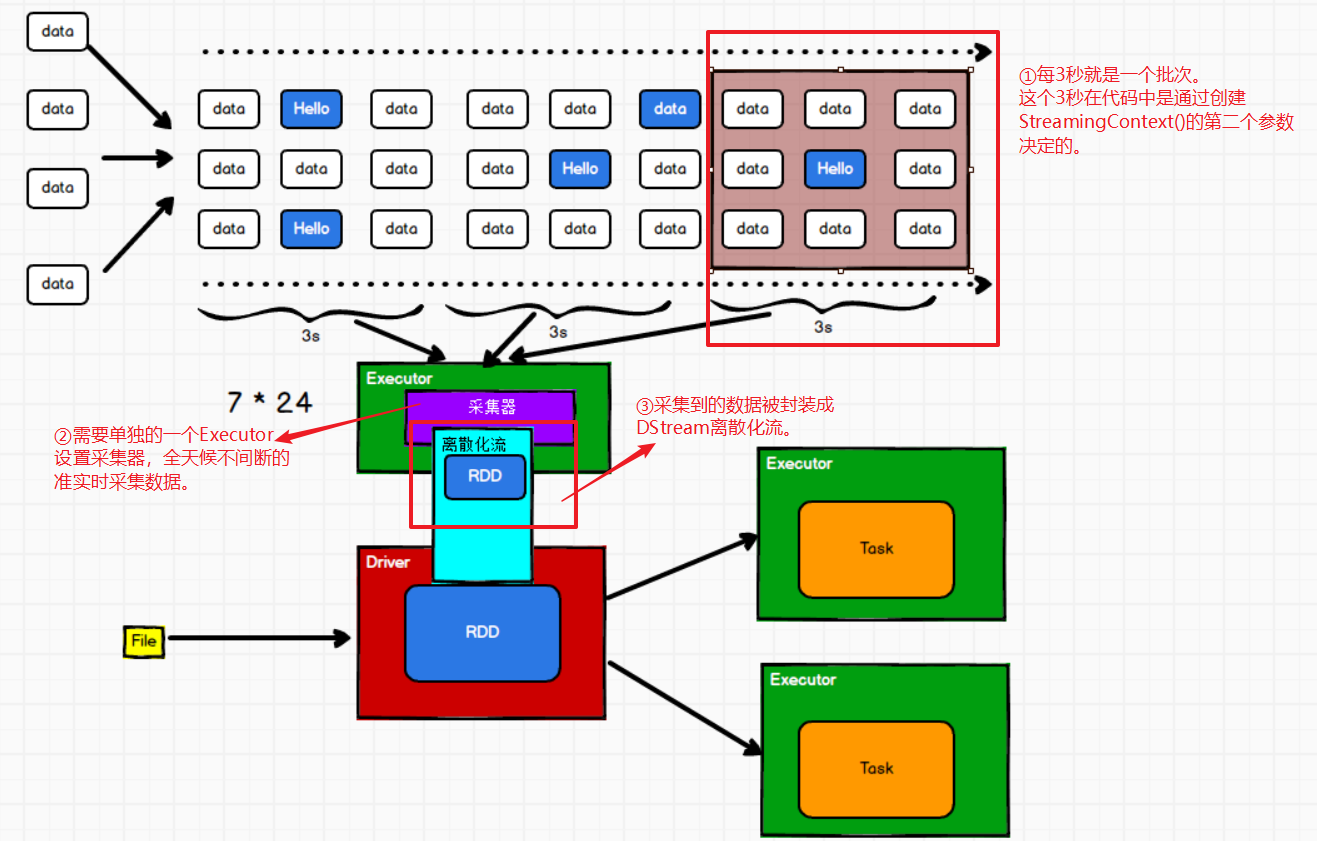
SparkStreaming是一个微批次,准实时的数据处理框架。
SparkStreaming用于流式数据处理。
1.1 流处理、批处理、实时处理、离线处理
从数据处理方式的角度:
- 流式处理:一条数据一条数据的处理,就是流处理
- 批量处理:一批数据一起处理
从数据处理延迟的角度:
- 实时处理:延迟的时间以毫秒为单位 => Flink
- 准实时处理:延迟的时间以秒、分钟为单位 => SparkStreaming
- 离线处理:延迟的时间以小时、天为单位 => MR
SparkStreaming是一个微批次、准实时的数据处理框架。
- SparkStreaming基于SparkCore进行流式数据处理的模块;
- SparkCore中的RDD没有办法进行真正的流式数据处理,其实是批量数据处理。不过是很小的批量
- SparkStreaming的目的是为了进行实时数据分析。
- SparkStreaming批量处理的数据不能太大,所以称为微批次处理。
- SparkStreaming无法真正实现实时数据处理,因为延迟比较高,但是因为一批数据量比较小,又达不到离线的范畴,所以称为准实时。
1.2 DStream
DStream(discretized stream),离散化流
和SparkCore中的RDD相似,SparkStreaming使用DStream离散化流,作为抽象表示。
DStream是随时间推移而收到的数据的序列。这些序列其实就是RDD组成的。
其实!DStream就是RDD在实时数据处理场景的一种封装。
1.3 SparkStreaming架构
①Receiver模式(早期版本)
需要一个专门的Executor去接收数据,然后发送给Driver,Driver再将数据按照分区,转换成Task分发给其他的Executor节点做计算。
扫描二维码关注公众号,回复: 12687132 查看本文章
这样会存在一个一个问题:接收数据的Executor和计算的Executor速度有所不同
- 特别是接收数据的Executor速度快于计算数据的Executor,那么采集器会有大量的数据堆积,会导致接收数据的Executor可能内存溢出
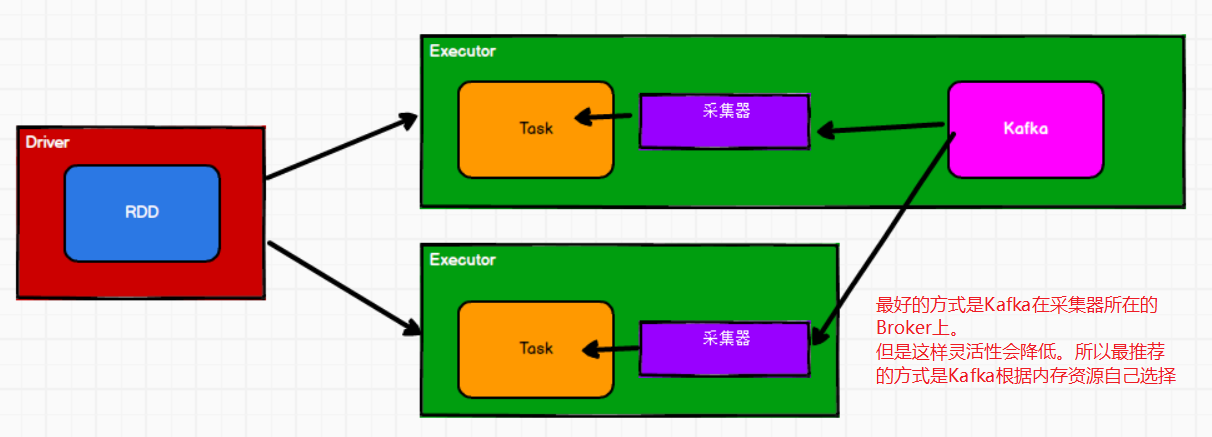
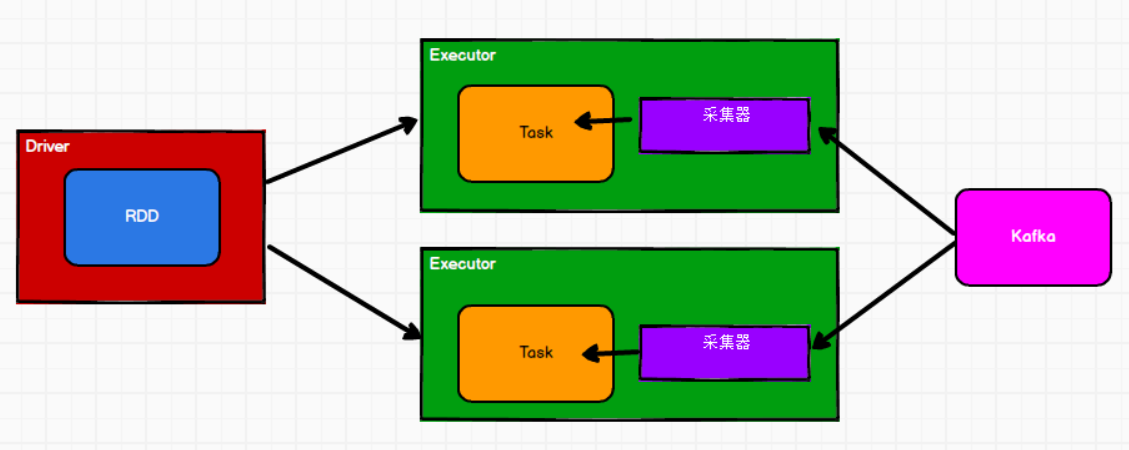
②Direct模式
计算和采集放在一个节点上,这样就很好控制采集和计算的速率。
LocationStrategy.PreferBrokers
LocationStrategies.PreferConsistent(大多数情况使用这种情况)在所有执行程序之间,Kafka根据内存等资源,自动的选择节点。
③背压机制
背压机制(即Spark Streaming Backpressure): 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
Spark1.5版本以前版本,为了限制Receiver的数据接收速率。可以通过设置动态配置参数“spark.streaming.receiver.maxRate”的值来实现,来适配当前的处理能力,防止内存溢出,但也会引入其他问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始SparkStreaming可以动态的控制数据接收速率来适配集群处理数据的能力。
通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
2 Dstream入门
2.1 WordCount案例实操
需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数。
①添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
②编写代码
创建StreamingContext(参数1,参数2)
参数1:SparkConf对象,Spark的配置信息。
参数2:批处理的时间,需要传Duration (private val millis: Long),还可以传下面的三个:
object Milliseconds { def apply(milliseconds: Long): Duration = new Duration(milliseconds) } object Seconds { def apply(seconds: Long): Duration = new Duration(seconds * 1000) } object Minutes { def apply(minutes: Long): Duration = new Duration(minutes * 60000) }启动SparkStreamingContext
- ssc.start()启动采集器!
ssc.awaitTermination()
- 这是一个阻塞,等待采集器的结束才结束。因为SparkStreaming一直读取数据,需要一个阻塞控制。不然就不行。
object Spark02_Streaming {
def main(args: Array[String]): Unit = {
//1. 创建SparkConf对象,初始化Spark配置信息
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2. 创建StreamingContext对象
//需要两个参数,第一个是SparkConf配置,第二个参数是批处理的时间:还有Milliseconds、Seconds、Minutes
val ssc: StreamingContext = new StreamingContext(conf, Duration(3000))
//3. 通过监控端口创建DStream,读取进来的数据是一行一行的
val lineStreams: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//每一行数据做切分,形成一个个单词
val wordStreams: DStream[String] = lineStreams.flatMap(_.split(" "))
//将单词映射元组(word,1)
val wordToOneStreams: DStream[(String, Int)] = wordStreams.map((_, 1))
//4. 打印
wordToOneStreams.print()
//5. 启动SparkStreamingContext
ssc.start()
//这是一个阻塞,不然就不行
ssc.awaitTermination()
}
}
3 DStream创建(采集数据)
从2.3采集数据的结果都会返回一个DStream
3.1 从端口号采集
作用:用来监听端口
socketTextStream(参数1,参数2)
- 参数1:表示机器名
- 参数2:端口号
val lineStreams: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
3.2 从文件获取
作用:用来监听文件夹内文件内容变化
textFileStream(“参数”):参数表示:要监听的文件夹
object Spark03_Streaming_Dir {
def main(args: Array[String]): Unit = {
//初始化Spark配置
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingRDD")
//初始化SparkStreamingContext
val ssc = new StreamingContext(conf, Duration(3000))
//TODO 从文件获取数据:textFileStream(directory目录)
val dirDS: DStream[String] = ssc.textFileStream("in")
val wordDS: DStream[String] = dirDS.flatMap(_.split(" "))
val wordToOneDS: DStream[(String, Int)] = wordDS.map((_, 1))
val result = wordToOneDS.reduceByKey(_ + _)
result.print()
//开启SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
3.3 从Queue队列中获取
object Spark03_Streaming_RDD {
def main(args: Array[String]): Unit = {
//1 初始化Spark配置
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingRDD")
//2 初始化SparkStreamingContext
val ssc = new StreamingContext(conf, Duration(3000))
//TODO 3 创建RDD队列,Queue中存放 RDD[Int]
val rddQueue: mutable.Queue[RDD[Int]] = new mutable.Queue[RDD[Int]]()
//TODO 4 创建QueueInputDStream
val inputStream: InputDStream[Int] = ssc.queueStream(rddQueue)
//5 处理队列中的RDD数据
val mappedStream: DStream[(Int, Int)] = inputStream.map((_, 1))
val result: DStream[(Int, Int)] = mappedStream.reduceByKey(_ + _)
//6 打印结果
result.print()
//7 启动任务
ssc.start()
//TODO 8 循环创建并向RDD队列中放入RDD
for (i <- 1 to 5){
rddQueue += ssc.sparkContext.makeRDD(1 to 300 , 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
3.4 自定义数据源
自定义采集器步骤:
- 继承org.apache.spark.streaming.receiver.Receiver类
- 定义泛型:要采集的数据的泛型,一般采集的是String
- 给Receiver父类传递参数:StorageLevel存储的级别
- 重写方法:
- onStart用while循环生成数据,用自带的store()存储数据。
- onStop用来停止采集
object Spark03_Streaming_DIY {
def main(args: Array[String]): Unit = {
//1 初始化Spark配置
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingRDD")
//2 初始化SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(3))
//TODO 创建自定义数据采集器
val myReceiver = new MyReceiver
//TODO 使用自定义采集器
val inputStream: ReceiverInputDStream[String] = ssc.receiverStream(myReceiver)
val dataToOne: DStream[(String, Int)] = inputStream.map((_, 1))
val result: DStream[(String, Int)] = dataToOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
//1 继承Receiver
//2 定义泛型:采集数据的类型
//3 给父类传递初始参数,用于设定数据的存储级别
//4 重写方法
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY){
private var flowFlg = true
override def onStart(): Unit = {
while (flowFlg) {
//生成数据
val data = new Random().nextInt(10).toString
//存储数据
store(data)
}
}
override def onStop(): Unit = {
flowFlg = false
}
}
}
3.5 Kafka
ReceiverAPI:需要一个专门的Executor去接收数据,然后发送给其他的Executor做计算。存在的问题,接收数据的Executor和计算的Executor速度会有所不同,特别在接收数据的Executor速度大于计算的Executor速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用
DirectAPI:是由计算的Executor来主动消费Kafka的数据,速度由自身控制
核心代码
//3.定义Kafka参数 val kafkaPara: Map[String, Object] = Map[String, Object]( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", ConsumerConfig.GROUP_ID_CONFIG -> "atguigu", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer" ) //4.读取Kafka数据创建DStream val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Set("AA"), kafkaPara))
需求:通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
步骤1:导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
步骤2:首先需要使用kafka创建一个Topic
# 查看当前有哪些topic
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --list
# 创建一个新的topic
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic AA --partitions 2 --replication-factor 3
# 启动kafka的生产者生产消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic AA
步骤3:编写代码,从kafka读取数据,计算wordCount
object Spark01_Streaming_kafka {
def main(args: Array[String]): Unit = {
//1.创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark-Streaming-Kafka")
//2.创建StreamingContext
val ssc = new StreamingContext(conf, Duration(3000))
//3.定义Kafka参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
//4.读取Kafka数据创建DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("AA"), kafkaPara))
//5.将每条消息的KV取出
val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
//6.计算WordCount
valueDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
//7.开启任务
ssc.start()
ssc.awaitTermination()
}
}
步骤4:查看Kafka消费进度
bin/kafka-consumer-groups.sh --describe --bootstrap-server linux1:9092 --group atguigu

4 DStream转换
- 方法:scala中的方法
- 算子:RDD中用来区别于scala方法的 函数的新称呼
- 原语:用来区别于scala方法和RDD算子的 表示DStream的函数的新称呼
DStream的操作于RDD类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作还有特殊的原语。如:updateStateByKey()和transform()等
4.1 无状态转换操作
什么是无状态转换操作?
更通俗的来说,就是在一个时间批次内计算的值,不会和下一个批次的进行累加!
就是简单的把RDD转化操作应用到每个批次上,也就是转换DStream中的每个RDD。部分无状态转化操作:
- 注意:针对键值对的DStream转化操作(reduceByKey)要添加import StreamingContext._才能在Scala中使用。

①transform
transform有一个好处就是可以周期性的执行一段代码。也就是说每一个采集周期都会执行一次。
object Spark04_Streaming_Transform {
def main(args: Array[String]): Unit = {
//1 创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//2 创建SparkStreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
//3 从socket获取数据
val inputStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//4 转为RDD操作
val wordCountDS: DStream[(String, Int)] = inputStream.transform(rdd => {
val words: RDD[String] = rdd.flatMap(_.split(" "))
val wordToOne: RDD[(String, Int)] = words.map((_, 1))
val result: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
result
})
//5 打印
wordCountDS.print()
//6 启动
ssc.start()
ssc.awaitTermination()
}
}
object Spark04_Streaming_Transform_1 {
def main(args: Array[String]): Unit = {
//1 创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//2 创建SparkStreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
//3 从socket获取数据
val inputStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
// TODO 原语,算子,方法
// Coding => Driver端 (执行一次)
inputStream.map(
str => {
// Coding => Executor端(任务数量)
str * 2
})
// ===========================
// Coding => Driver端 (执行一次)
inputStream.transform(
rdd => {
// Coding => Driver端 (周期性执行)
rdd.map(
str => {
// Coding => Executor端 (任务数量)
str * 2
}
)
}
)
//6 启动
ssc.start()
ssc.awaitTermination()
}
}
②join
join可以将两个DStream根据相同key拼接起来。底层就是RDD的join
两个流之间的join需要两个流的批次大小一致,这样才能同时触发计算。
下面的例子是只有相同key的才会join在一起。
object Spark05_Streaming_Join {
def main(args: Array[String]): Unit = {
//创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Duration(5000))
//通过socket获取数据创建DS
val ds1: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 9999)
val ds2: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 8888)
val kv1: DStream[(String, Int)] = ds1.map((_, 1))
val kv2: DStream[(String, Int)] = ds2.map((_, 1))
val joinDS: DStream[(String, (Int, Int))] = kv1.join(kv2)
joinDS.print()
ssc.start()
ssc.awaitTermination()
}
}
4.2 有状态转换操作
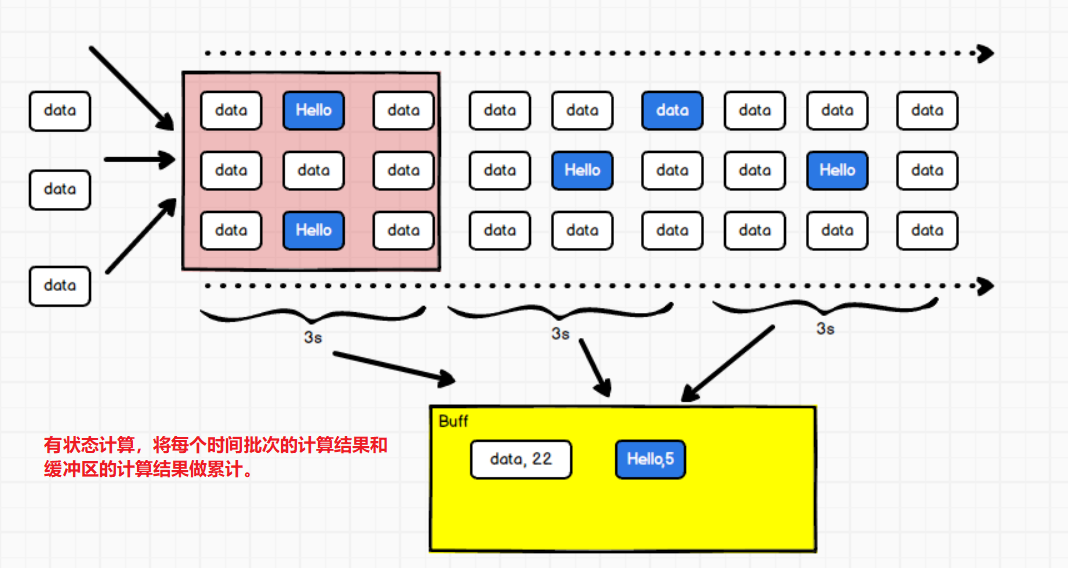
有状态转换操作:通俗来说就是,一个时间批次的计算结果会放到一个缓冲区暂存起来,会累加多个缓冲区的结果。
①UpdateStageByKey
UpdateStageByKey有状态操作,原语用来记录历史批次的值。
- 如果使用reduceByKey,因为reduceByKey是无状态的操作,所以它仅仅是计算一个批次内的数据,计算时不考虑缓冲。
- updateStageByKey就是使用设置的checkpoint作为缓冲区,将不同批次的数据和缓冲区的暂存数据进行聚合操作。

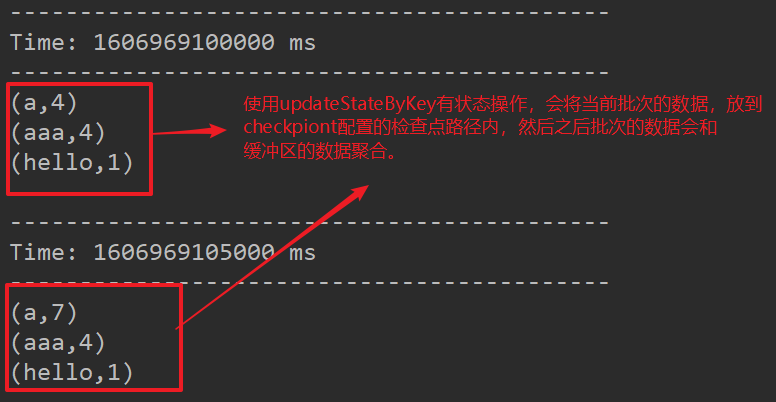
- updateStateByKey(参数1,参数2)
- 参数1:相同key的value值的集合
- 参数2:
object Spark06_Streaming_State {
def main(args: Array[String]): Unit = {
//创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Duration(5000))
//TODO 设置检查点:一般为HDFS路径
ssc.checkpoint("cp")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
val words: DStream[String] = inputDS.flatMap(_.split(" "))
val wordToOne: DStream[(String, Int)] = words.map((_, 1))
//wordToOneDS.reduceByKey(_+_) // 所谓的无状态操作,就是计算时不考虑缓冲
//val result = wordToOne.reduceByKey(_ + _)
//TODO updateStateByKey有状态数据操作
// updateStateByKey传递的参数时一个函数:
// 函数有两个参数:
// 第一个参数:表示相同key的value的集合(Seq)
// 第二个参数:表示缓冲区数据对象
//The checkpoint directory has not been set.
//有状态计算其实就是使用缓冲区进行计算,这个缓冲区其实采用的是检查点操作
val result: DStream[(String, Int)] = wordToOne.updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
val currentVal = seq.sum
val buffVal = buffer.getOrElse(0)
val newVal = currentVal + buffVal
Option(newVal)
}
)
result.print()
//启动StreamingContext
ssc.start()
ssc.awaitTermination()
}
}
连接Kafka,消费消息
需要注意的一点!!!从kafka直接获得的数据是一个InputStream流,kafka传输是以k-v传输的。要获取record的value值,在进行计算。
kafkaDStream.map(record => record.value())
object Spark06_Streaming_State_1 {
def main(args: Array[String]): Unit = {
//创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Duration(5000))
//TODO 设置检查点:一般为HDFS路径
ssc.checkpoint("cp")
//TODO 定义Kafka参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
//TODO 从kafka获取数据
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("CC"), kafkaPara)
)
//TODO !!!需要在kafka流中获取record的值。
val lines: DStream[String] = kafkaDStream.map(record => record.value())
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordToOne = words.map((_, 1))
val result: DStream[(String, Int)] = wordToOne.updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
val sum = seq.sum
val bufferVal = buffer.getOrElse(0)
val newVal = bufferVal + sum
Option(newVal)
})
result.print()
//启动StreamingContext
ssc.start()
ssc.awaitTermination()
}
}
②检查点:checkpoint
默认的检查点,所保存的路径是本地。但是一般我们都是将检查点保存到HDFS上。
那么如何设置SparkStreaming缓存的检查点为HDFS呢?
- 将Hadoop的core-site.xml和hdfs.-site.xml放到工程的resource文件夹内,编译让target内的classes内出现才行。这样再设置的检查点路径,默认是采用HDFS上的路径。
- 需要注意的是!需要设置代理访问用户。 System.setProperty(“HADOOP_USER_NAME”, “atguigu”)
object Spark06_Streaming_State_3 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp")
//kafka
val kafkaPara = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("BB"), kafkaPara)
)
//获取kafka的value值
val kafkaDS: DStream[String] = kafkaInputDStream.map(_.value())
val wordToOne: DStream[(String, Int)] = kafkaDS.map((_, 1))
val result = wordToOne.updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
val sum = seq.sum
val bufferVal = buffer.getOrElse(0)
val newVal = bufferVal + sum
Option(newVal)
}
)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
从检查点恢复数据
检查点默认的是,不会保存数据,也就是说下次SparkStreaming读取数据的时候,会从0开始updateStateByKey。
从检查点恢复数据,getActiveOrCreate(“检查点路径”, ()=> {匿名函数})
object Spark06_Streaming_State_2 {
def main(args: Array[String]): Unit = {
//设置访问HDFS的代理用户
System.setProperty("HADOOP_USER_NAME", "atguigu")
//TODO 从检查点恢复数据
val streamingContext = StreamingContext.getActiveOrCreate("cp1", () => {
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp1")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
val result = inputDS.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
val sum = seq.sum
val buffVal = buffer.getOrElse(0)
val newVal = sum + buffVal
Option(newVal)
}
)
result.print()
ssc
})
//启动SparkStreaming
streamingContext.start()
streamingContext.awaitTermination()
}
}
③窗口函数WindowOperations
- 数据的操作范围(窗口):
- 默认情况下窗口操作就是存在的,只不过默认窗口大小为一个采集周期,滑动幅度也是一个采集周期。
- 默认的窗口是随着时间的推移进行滑动的,默认值是一个采集周期。
- 默认的窗口操作不需要保存状态,只需要默认处理即可。
window(参数1,参数2)
- 参数1:表示窗口的大小,以时间为单位,一般设定为采集周期的整数倍。
- 参数2:表示窗口的滑动幅度,步长,一般设定为采集周期的整数倍,默认是采集周期的大小。
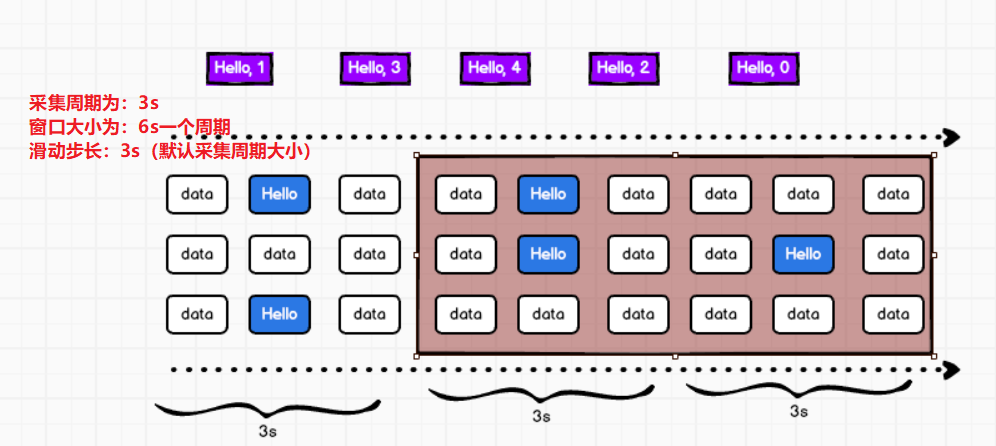
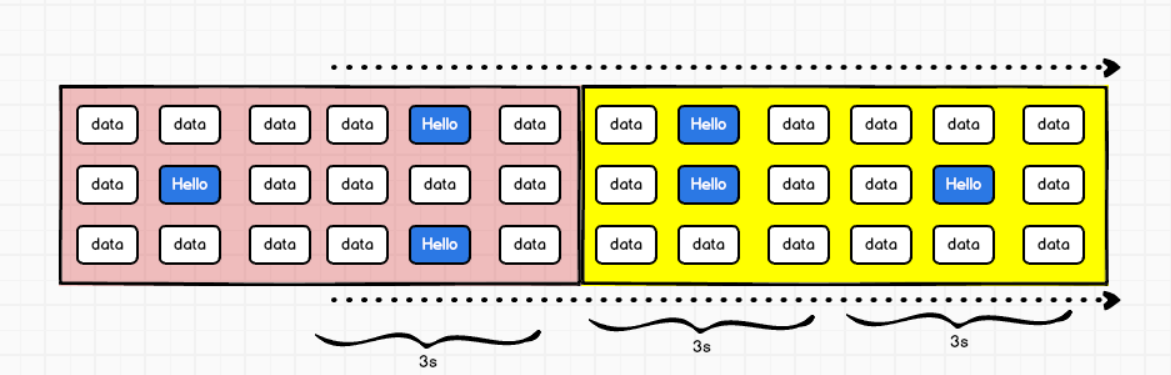
当窗口大小大于采集周期:会出现重复数据,会出现低 - 高 - 低的趋势
当窗口大小小于或不等于采集周期的整数倍,会增加复杂度。
当窗口大小等于滑动步长大小,不会出现重复数据
object Spark08_Streaming_Window {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Window")
val ssc = new StreamingContext(conf, Duration(3000))
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//无状态操作
val wordCount = inputDS.flatMap(_.split(" ")).map((_, 1))
//TODO 窗口函数
//计算前,可以设定数据的操作范围(窗口)
//窗口window方法用于进行数据的窗口计算
//默认情况下,窗口随着时间的推移进行滑动的,默认值以一个采集周期
//SparkStreaming中计算周期为窗口滑动步长
//窗口操作默认就是存在的,只不过默认范围为一个采集周期,滑动幅度为一个采集周期
//默认的窗口操作不需要状态保存,只需要默认处理即可。
//Window(参数1, 参数2)
// 参数1:表示窗口的范围,以时间为单位,一般设定为采集周期的整数倍
// 参数2:表示窗口的滑动幅度,步长,一般设定为采集周期的整数倍,默认是采集周期的大小
val windowDS = wordCount.window(Seconds(6), Seconds(6))
val result = windowDS.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
④其他窗口函数
(1)window(windowLength, slideInterval): 基于对源DStream窗化的批次进行计算返回一个新的Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
需要设置检查点。
object Spark08_Streaming_Window_1 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setMaster("local[*]").setAppName("Window")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//无状态操作
val wordCount = inputDS.flatMap(_.split(" ")).map((_, 1))
//TODO countByWindow(),返回一个滑动窗口计数流中的元素个数
// The checkpoint directory has not been set
val value: DStream[Long] = wordCount.countByWindow(Seconds(6), Seconds(6))
value.print()
ssc.start()
ssc.awaitTermination()
}
}
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
object Spark08_Streaming_Window_2 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setMaster("local[*]").setAppName("Window")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//无状态操作
val wordCount = inputDS.flatMap(_.split(" ")).map((_, 1))
//TODO reduceByWindow()
val result = wordCount.reduceByWindow((t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}, Seconds(6), Seconds(6)
)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
(4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
(5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。
object Spark08_Streaming_Window_3 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setMaster("local[*]").setAppName("Window")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//无状态操作
val wordCount = inputDS.flatMap(_.split(" ")).map((_, 1))
//TODO reduceByKeyAndWindow()
val result = wordCount.reduceByKeyAndWindow(
(x, y) => {
println(x + " + " + y)
x + y
},
(a, b) => {
println(a + " - " + b)
a - b
},
Seconds(9),
Seconds(3)
)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
5 DStream输出
与RDD的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context都不会启动。
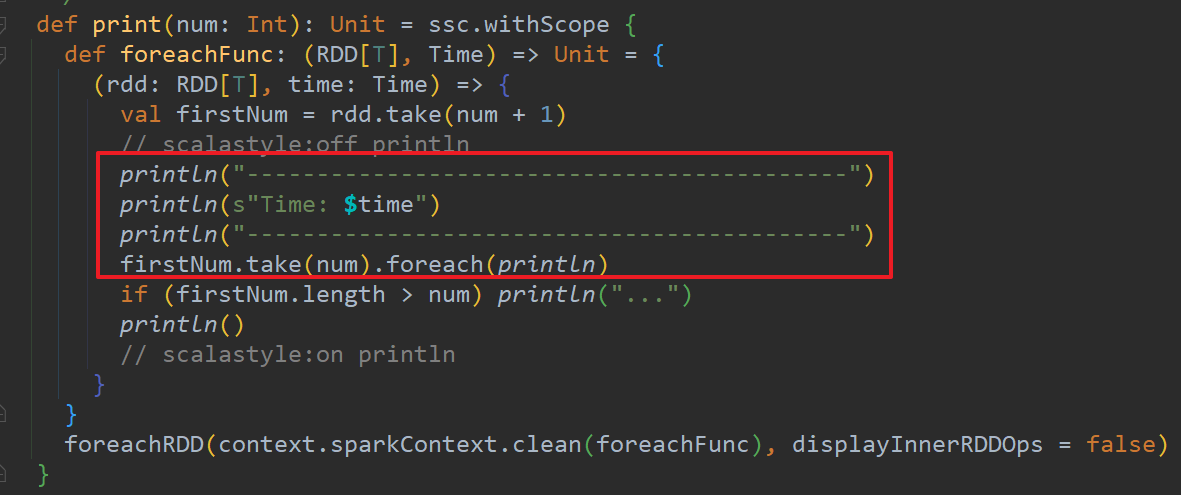
①print()
打印DStream中每一批次数据的最开始10个元素
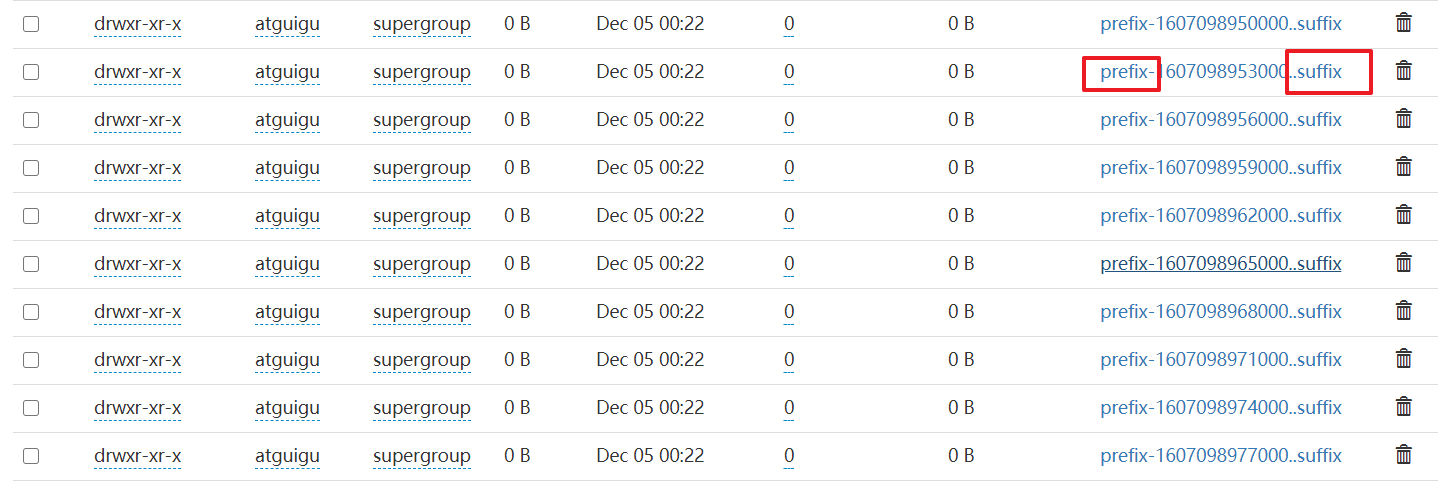
②saveAsTextFiles(prefix, [suffix])
以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”
object Spark09_Streaming_Output {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setMaster("local[*]").setAppName("Window")
val ssc = new StreamingContext(conf, Duration(3000))
ssc.checkpoint("cp")
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//无状态操作
val wordCount = inputDS.flatMap(_.split(" ")).map((_, 1))
//TODO saveAsTextFiles
wordCount.saveAsTextFiles("prefix", ".suffix")
ssc.start()
ssc.awaitTermination()
}
}
③saveAsObjectFiles(prefix, [suffix])
以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。
④saveAsHadoopFiles(prefix, [suffix])
将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API 中目前不可用
⑤foreachRDD(func)
这是最通用的输出操作,即将函数 func 用于产生于 stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。
注意:1. 连接不能写在driver层面(需要考虑序列化问题)
2. 如果写在foreache则每个RDD中的每一条数据都创建,浪费
3. foreachPartition,在分区创建(获取)
6 优雅关闭
流式任务需要7*24小时执行,但是有时涉及到代码升级需要主动停止程序,但是分布式程序,没办法做到一个个进程杀死。需要使用外部文件系统来控制内部程序关闭。
object Spark10_Streaming_Close {
def main(args: Array[String]): Unit = {
//创建SparkStreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("GraceClose")
val ssc = new StreamingContext(conf, Seconds(3))
//获取数据
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 8899)
val result = inputDS.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print()
ssc.start()
//stop()方法不能在主线程中调用
//1. 关闭需要在新的线程中执行
//2. 方法的调用机制(分布式事务)
//
// var closeFlg = false
new Thread(new Runnable {
override def run(): Unit = {
// while (true){
// if (closeFlg){
// ssc.stop()
// return
// }
// Thread.sleep(10000)
// }
while (true) {
try
Thread.sleep(5000)
catch {
case e: InterruptedException =>
e.printStackTrace()
}
//TODO 创建HDFS文件系统对象
// 注意!端口是RPC端口,不是Web端口 => 8020
// 注意!需要设置user=“atguigu”,不然就需要在首行设置代理用户
val fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "atguigu")
val state = ssc.getState()
val bool = fs.exists(new Path("hdfs://hadoop102:8020/stopSpark"))
if (bool) {
if (state == StreamingContextState.ACTIVE){
//TODO 设置优雅关闭为true
ssc.stop(stopSparkContext = true, stopGracefully = true)
System.exit(0)
}
}
}
}
}).start()
//
ssc.awaitTermination()
}
}