1 Redis简介
1.1 NoSQL数据库
NoSQL数据库,Not Only SQL,非关系型数据库
- 不遵循SQL标准
- 不支持ACID
- 远超过SQL的性能
① NoSQL适用场景
性能快,容量大,扩展性高
②NoSQL不适用场景
事务,即席查询
③常见NoSQL数据库
-
Memcache(内存数据库)
不能持久化,支持类型key-value,缓存数据库
-
Redis(内存数据库)
支持持久化,支持多种数据结构的存储:list、set、hash、zset,缓存数据库
-
Mongodb(文档数据库)
文档型数据库,支持key-value类型value是json类型。
-
HBase(列式数据库)
分布式海量数据存储。
http://db-engines.com/en/ranking
1.2 Redis简介
- Redis是一个开源的key-value存储系统
- 支持String、list、set、hash、zset等类型
- 数据操作都是原子性的
- 支持各种不同方式的排序
- 数据缓存在内存
- 周期型把数据写入磁盘
- 实现了master-slave(主从同步)
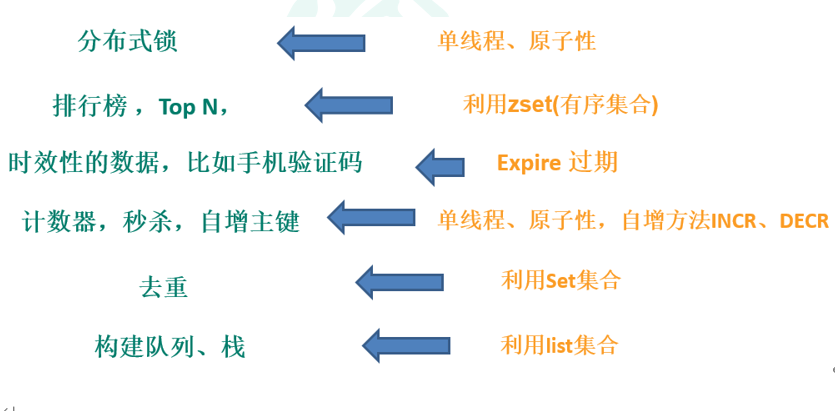
1.3 应用场景
-
配合关系型数据库做高速缓存
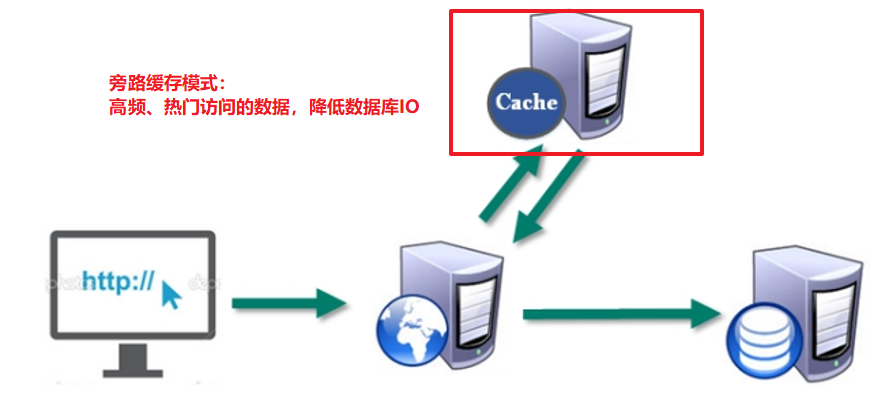
-
大数据场景:缓存数据
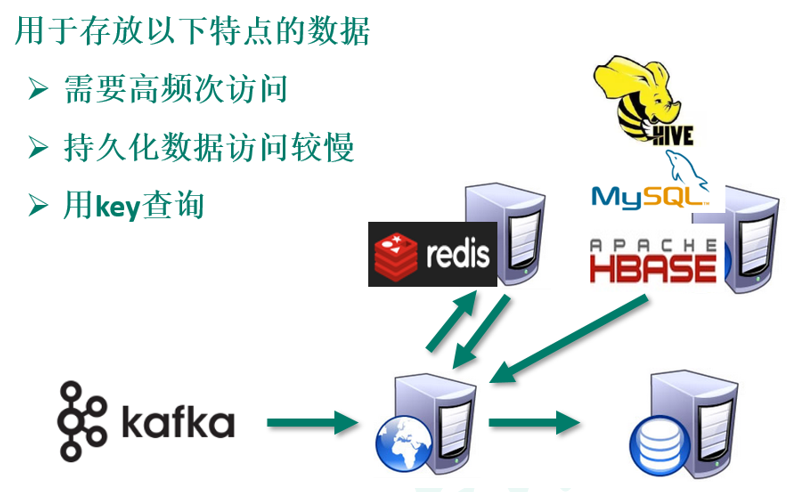
-
大数据场景:临时数据
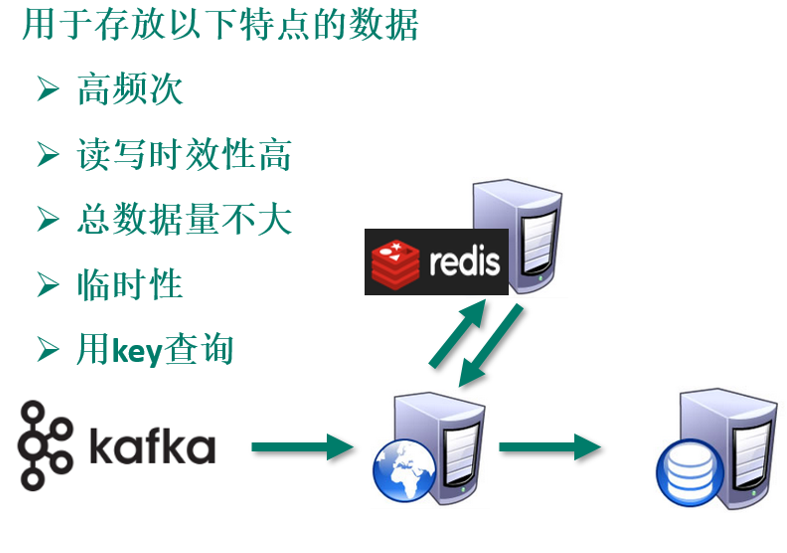
-
大数据场景:计算结果
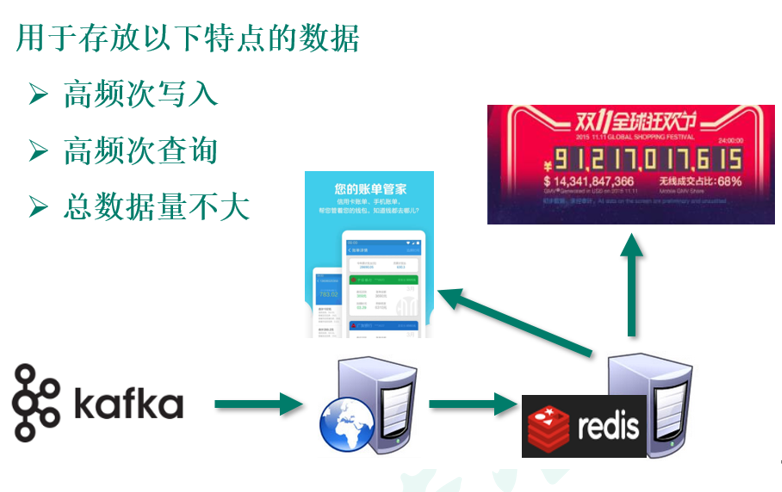
-
利用Redis解决特殊问题
1.4 Redis端口
Redis端口是6379,一个女人的故事
-
redis默认有16个数据库,类似数组的下标从0开始,默认使用0号库。
-
使用select 的方式切换数据库。
-
可以在redis.conf中配置数据库的个数:

1.5 Redis单线程+多路IO复用技术
多路IO复用是利用select、poll、epoll(不同的监控策略)
Redis是单线程的数据库
是利用了多路IO复用(linux的技术)
为什么要用单线程呢?
单线程结构简单,不用考虑多线程并发的问题。
有很多业务,就需要单线程,秒杀和锁的问题,都需要单线程。
6.x版本的Redis支持多线程
并不是计算支持多线程,而是把计算和接受发送数据分成了两个部分:
- IO分发:收发数据支持多线程(默认关闭的)
- 处理:计算还是单线程计算
为什么只有Redis采用单线程+多路复用呢?
redis内存数据库,并且计算特别简单,仅仅是处理k-v类型的数据,这样就很少会串行计算的时候会在中间阻塞住。
而mysql这种的数据库,计算sql特别的复杂。
①串行
把老师比作CPU,一个老师挨个学生去辅导,1号学生完了,然后辅导2号学生。。。
②多线程+锁
多个老师相当于多个CPU,每个老师对应辅导一个学生。相当于多个CPU同时并行执行。但是会存在一个问题,当老师想用同一台电脑的时候,电脑就相当于共享资源。就需要锁去防止多线程抢占共享资源出现的问题。
③单线程+多路IO复用
一个老师相当于一个CPU,当学生有问题就举手,老师就过去解决问题,指导完其他学生举手,老师就可以去其他同学那里处理问题。CPU频繁来回的切换。
切换有很多IO多路复用的算法:不同的监控策略
- select是谁有问题谁举手,然后CPU会都问一遍谁也有这个问题,都去解决这个问题。
- poll和epoll是谁有问题谁举手,只解决举手的同学的问题。
④Redis6.x版本
一个老师相当于CPU,当有前排学生和后排学生都举手的时候,前后来回跑就很消耗资源。这个时候再来一个助教,仅仅做IO收发数据,还是靠这一个老师去处理问题。
就相当于IO收发数据是多线程了,但是计算处理还是单线程。
2 Redis部署安装
2.1 安装版本
Redis官方网站:http://redis.io
Redis中文官方网站: http://www.Redis.net.cn
安装版本:6.0.8 for Linux(redis-6.0.8.tar.gz)
2.2 安装步骤
步骤1:下载安装最新的gcc编译器
- 安装C语言的编译环境
[atguigu@hadoop103 ~]$ sudo yum install centos-release-scl scl-utils-build
[atguigu@hadoop103 ~]$ sudo yum install -y devtoolset-8-toolchain
[atguigu@hadoop103 ~]$ sudo scl enable devtoolset-8 bash
- 测试gcc版本
[root@hadoop103 atguigu]# sudo gcc --version

步骤2:将redis安装包放到/opt/software
步骤3:解压安装包到/opt/module文件下
[root@hadoop103 software]# tar -zxvf redis-6.0.8.tar.gz -C /opt/module/
步骤4:进入到redis-6.0.8目录执行make命令(编译)
[root@hadoop103 redis-6.0.8]# make
步骤5:编译完成后,安装,执行make install命令
[root@hadoop103 redis-6.0.8]# make install
备注1:如果make报错—Jemalloc/jemalloc.h:没有那个文件。需要运行:
make distclean
然后再redis-6.0.8目录下再次执行make命令。
make
跳过make test,继续执行
make install
备注2:安装目录:
/usr/local/bin
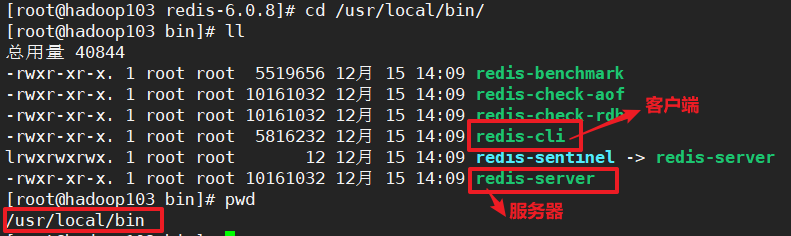
redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何
redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用,哨兵
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口
2.3 启动redis
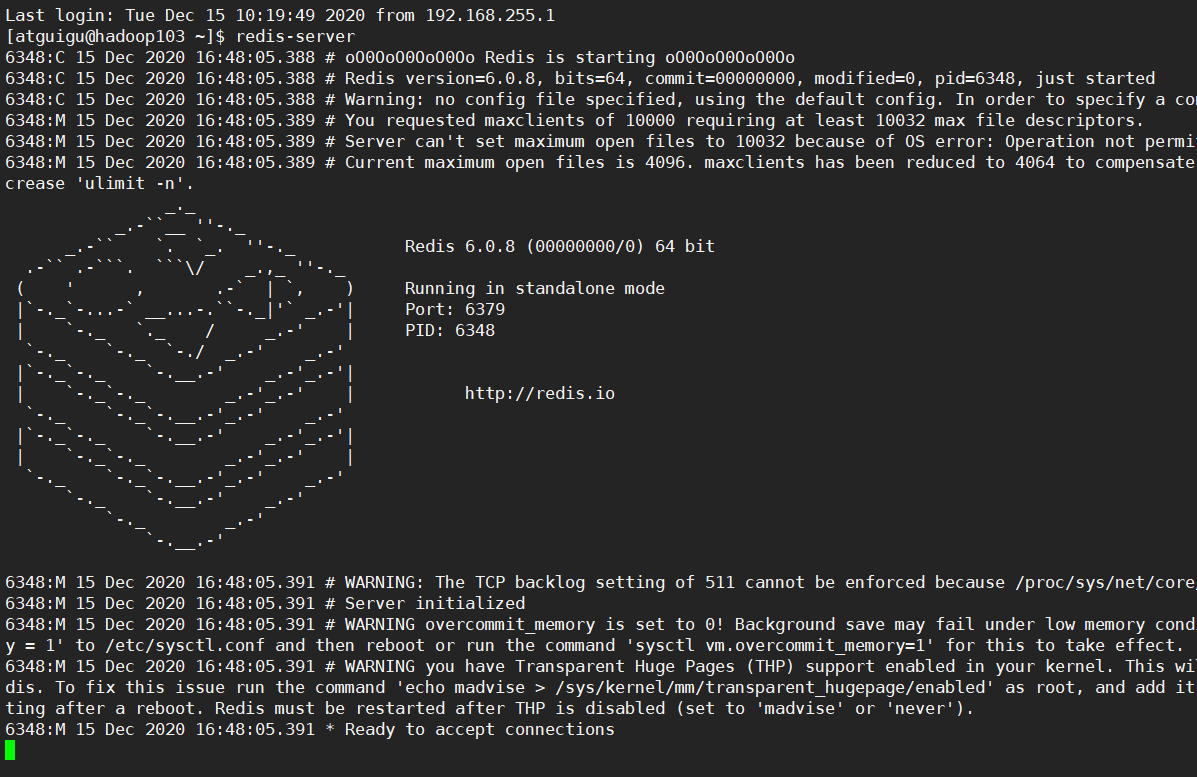
①启动redis服务器
方式1:前台启动:
会阻塞在前台!不推荐!
[atguigu@hadoop103 ~]$ redis-server
方式2:后台启动
需要修改redis.conf配置文件中的daemonize为yes

然后启动redis服务器:
# 在/home/atguigu/目录下创建myredis
# 将redis.conf复制一份,放到myredis这个文件夹内。使用这个配置文件
# 在myredis这个路径下启动redis服务,这样产生的rdb文件也会在这个文件夹内!
[atguigu@hadoop103 myredis]$ redis-server ./redis.conf
②查看开启的redis服务器进程
redis服务器开启时候:
[atguigu@hadoop103 ~]$ ps -ef | grep redis

redis服务器关闭时候:

③关闭redis服务器
方式1:在redis客户端中,使用shutdown关闭服务器
127.0.0.1:6379> shutdown
not connected>
方式2:在客户端命令后使用shutdown关闭服务器
[atguigu@hadoop103 ~]$ redis-cli shutdown
方式3:多实例关闭
多实例关闭,指定端口关闭:redis-cli -p 6379 shutdown
④启动redis客户端
方式1:本地登录redis客户端
[atguigu@hadoop103 ~]$ redis-cli
127.0.0.1:6379>
方式2:使用-h ip地址 -p 端口号的方式
[atguigu@hadoop103 ~]$ redis-cli -h hadoop103 -p 6379
Could not connect to Redis at hadoop103:6379: Connection refused
not connected>
方式3:集群模式登录客户端
[atguigu@hadoop103 ~]$ redis-cli -c -p 6379
127.0.0.1:6379>
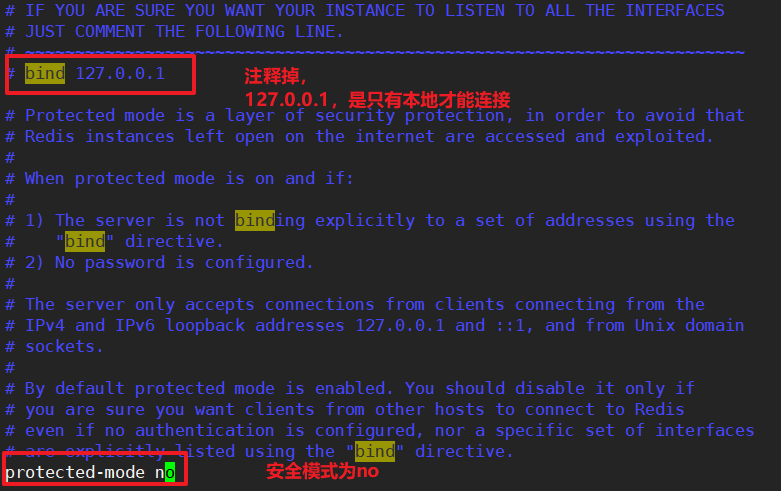
redis默认的bind是127.0.0.1是只有本地才可以连接的!
方法1:把redis-server的redis.conf中的bind注释掉,然后修改protected-mode为no
方法2:把redis.conf中的bind 改为 0.0.0.0,任何网段的ip都可以连接。
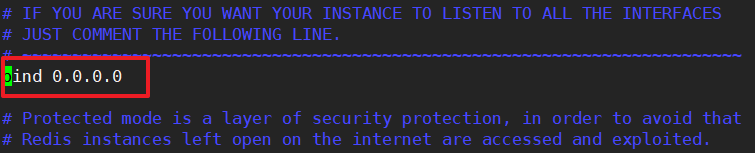
用上面两种方法修改配置文件之后,就可以连接上了~
[atguigu@hadoop103 ~]$ redis-cli -h hadoop103 -p 6379
hadoop103:6379>
测试验证:
hadoop103:6379> ping
PONG
⑤关闭客户端
方式1:
hadoop102:6379> exit
方式2:使用ctrl + c
2.4 简单的配置
单机上启动Redis服务。需要修改配置:
①注释掉网络bind

②关闭安全模式

③开启守护进程

④pid进程文件路径

⑤Redis日志路径

启停Redis服务后,这个时候就可以看到/home/atguigu/myredis/文件内有下面几个文件:

3 Redis数据类型
切换数据库 select 库号(0-16)
hadoop102:6379> select 0
OK
查看当前数据库的key的数量 dbsize
hadoop102:6379> DBSIZE
(integer) 1
清空当前库 flushdb
hadoop102:6379> FLUSHDB
OK
清空全部库 flushall
hadoop102:6379> FLUSHALL
OK
3.1 Redis键(key)
①查看所有的key
hadoop102:6379> keys *
(empty array)
②添加key-value
hadoop102:6379> set Tom 28
OK
hadoop102:6379> set Tom man
OK
# 原来的Tom,28 就被覆盖掉了~
③查看key的value
hadoop102:6379> get Tom
"man"
hadoop102:6379> get 29
(nil) # 不存在的key值为nil
④查看key的类型
hadoop102:6379> type Tom
string
⑤判断key的值是否存在
hadoop102:6379> EXISTS Tom
(integer) 1
hadoop102:6379> EXISTS Jerry
(integer) 0
# 布尔值是以0和1表示,1为true;0为false
⑥删除key的值
hadoop102:6379> del Tom
(integer) 1
# 1表示删除成功
⑦为给定的key设置过期时间
# 首先是需要给已经存在的key设置过期时间
hadoop102:6379> set Tom man
OK
# 给Tom这个key设置10s的过期时间
hadoop102:6379> expire Tom 10
(integer) 1
⑧查看key的过期时间
ttl => time to list
hadoop102:6379> ttl Tom
(integer) 5 # 表示还有5s失效
hadoop102:6379> ttl Tom
(integer) -2 # -2表示已经过期
hadoop102:6379> ttl Jerry
(integer) -1 # -1表示永不过期
3.2 Redis字符串(string)
String是Redis最基本的类型,一个Redis中字符串value最多可以是512M
①添加键值对 set
hadoop102:6379> set zhangsan money=10000
②查询对应的键值对 get
hadoop102:6379> get zhangsan
"money=10000"
③将给定的value追加到key的值的末尾 append
hadoop102:6379> APPEND zhangsan count=001
hadoop102:6379> get zhangsan
"money=10000count=001"
④只有在key不存在时,设置key的值(原子性)
当setnx一个存在的key,无效,可以还是原值。
hadoop102:6379> setnx lisi 1997
(integer) 1
hadoop102:6379> get lisi
"1997"
⑤将key的数值+1(原子性)
key对应的value必须是数值类型,如果是非数值类型会报错。
hadoop102:6379> get lisi
"1997"
hadoop102:6379> INCR lisi
(integer) 1998
hadoop102:6379> incr zhangsan
(error) ERR value is not an integer or out of range
⑥将key的数值-1(原子性)
hadoop102:6379> DECR lisi
(integer) 1997
hadoop102:6379> DECR lisi
(integer) 1996
hadoop102:6379> DECR zhangsan
(error) ERR value is not an integer or out of range
⑦将key中的数值,自定义步长增加、减少(原子性)
记忆方式:increase + by => incrby
hadoop102:6379> INCRBY lisi 100
(integer) 2096
hadoop102:6379> INCRBY lisi 100
hadoop102:6379> DECRBY lisi 100
(integer) 2096
hadoop102:6379> DECRBY lisi 100
(integer) 1996
⑧同时设置一个或多个key-value对 mset …
我的记忆方式:many set
hadoop102:6379> mset Jeck man Rose woman
⑨同时获取一个或多个value
我的记忆方式many get
hadoop102:6379> mget Jeck Rose
1) "man"
2) "woman"
⑩同时设置一个或多个key-value对,并且仅当所设置的key都不存在时 msetnx …
msetnx => 我的记忆方法:many + set + nx
hadoop102:6379> MSETNX wukong guipaiqigong tainjinfan kongqipao
(integer) 1
hadoop102:6379> mget wukong tainjinfan
1) "guipaiqigong"
2) "kongqipao"
⒒设置key-value对的同时,设置过期时间,单位为秒
set是设置k-v对,而expire是过期时间 => setex
hadoop102:6379> SETEX guixianren 10 gui # 新建key-value的同时设置过期时间
hadoop102:6379> ttl guixianren
(integer) 2
hadoop102:6379> ttl guixianren
(integer) -2
3.3 Redis列表(List)
Redis列表,一个key多个value。
它的底层是一个双端双向链表。

①从左边/右边插入一个或多个值:lpush / rpush …
# 从左边插入=> v1 => v2 v1 => v3 v2 v1
hadoop102:6379> lpush list1 v1 v2 v3
(integer) 3
# 从右边插入 v3 v2 v1 v4 v5 <= v3 v2 v1 v4 <= v3 v2 v1
hadoop102:6379> rpush list1 v4 v5
(integer) 5
②查看当前列表中的数据 lrange
lrange => list range 【0,1】,包括list1【0】和list1【1】
- 取出列表中所有的数据:lrange list1 [0, -1],-1 表示到最后
hadoop102:6379> lrange list1 0 -1
1) "v3"
2) "v2"
3) "v1"
4) "v4"
5) "v5"
③从左边/右边取出一个值
hadoop102:6379> lpop list1 # 从左边取出一个
"v3"
hadoop102:6379> lrange list1 0 -1
1) "v2"
2) "v1"
3) "v4"
4) "v5"
hadoop102:6379> rpop list1 # 从右边取出一个
"v5"
hadoop102:6379> lrange list1 0 -1
1) "v2"
2) "v1"
3) "v4"
④根据索引下标查看元素(从左到右) lindex
记忆方式:list index
# 查看list1列表中索引下标为0的元素
hadoop102:6379> lindex list1 0
"v2"
⑤获取列表的长度 llen
记忆方式:list length
hadoop102:6379> llen list1
(integer) 3
# 注意,只能获取列表的长度,其他的类型会报错
hadoop102:6379> TYPE lisi
string
hadoop102:6379> type list1
list
⑥在的后面插入 插入值 linsert before
linsert => left insert
# 现在list的是:v2 v1 v4;在v1的后面插入v10
hadoop102:6379> LINSERT list1 after v1 v10
hadoop102:6379> lrange list1 0 -1
1) "v2"
2) "v1"
3) "v10"
4) "v4"
⑦从左边删除n个value(从左到右) lrem
lrem => left remove
!!! 这里的n删除的是相同的value值,也就是说当存在相同的value,n表示删除n个此value值
hadoop102:6379> lrem list1 2 v2
(integer) 1
hadoop102:6379> lrange list1 0 -1
1) "v1"
2) "v10"
3) "v4"
3.4 Redis集合(Set)
Redis set可以自动去重。
①新建一个set,向里面添加数据 sadd …
记忆方式:set add + 元素
hadoop102:6379> SADD set1 v1 v2 v3 v3 v3
(integer) 3
②列出集合中所有的值
记忆方式:smembers => set members ,去重~
hadoop102:6379> SMEMBERS set1
1) "v2"
2) "v3"
3) "v1"
③判断集合是否含有该值,sismember
记忆方式:sismember => set is member
hadoop102:6379> SISMEMBER set1 v1
(integer) 1
hadoop102:6379> SISMEMBER set1 v11
(integer) 0
④返回集合的元素个数 scard
scard => set card,card是卡片,纸牌的意思~
hadoop102:6379> SCARD set1
(integer) 3
⑤删除集合的某个元素 srem …
# 删除set集合中的v11 和v3 这两个元素
hadoop102:6379> srem set1 v11 v3
(integer) 2
⑥返回两个集合的交集 sinter
hadoop102:6379> SMEMBERS set1
1) "v33"
2) "v22"
3) "v2"
4) "v44"
5) "v1"
hadoop102:6379> SMEMBERS set2
1) "v3"
2) "v1"
3) "v6"
4) "v5"
5) "v2"
6) "v4"
两个集合的交集:sinter => set intersection,交集
hadoop102:6379> SINTER set1 set2
1) "v2"
2) "v1"
⑦返回两个集合的并集 sunion
两个集合的并集:set union
hadoop102:6379> SUNION set1 set2
1) "v2"
2) "v3"
3) "v44"
4) "v1"
5) "v33"
6) "v22"
7) "v6"
8) "v5"
9) "v4"
⑧返回两个集合的差集 sdiff
两个集合的差集:sdiff => difference set
hadoop102:6379> SDIFF set1 set2
1) "v22"
2) "v33"
3) "v44"
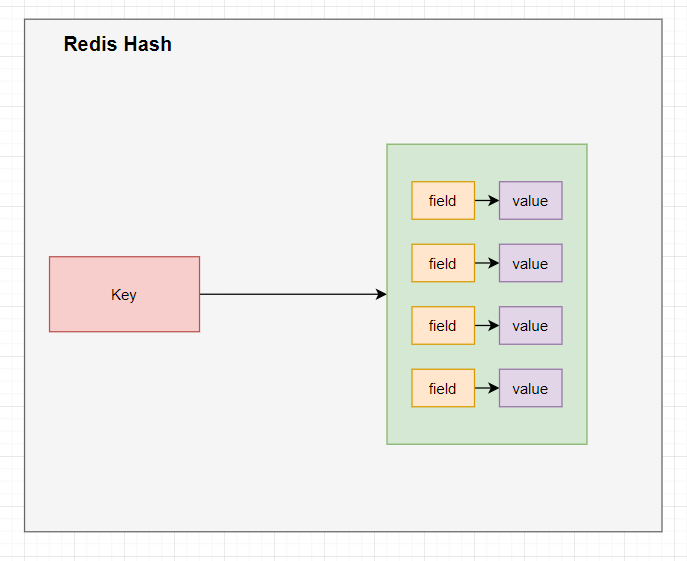
3.5 Redis哈希(Hash)
Redis hash是一个键值对集合,它的value是一个string类型的field-value的映射表。
这样存储有什么好处呢?
如果要存储userinfo id name amount city,怎么存呢?并且amount经常修改~
方式1:key - json的方式存储
get key --> json --> userInfo --> userInfo.amount+=100 --> userInfo --> json --set key
这种方式在序列化的过程会消耗性能
方式2:key -value …的方式存储
user:1001:name Tom
user:1001:amount 10000
user:1001:city beijing
这种方式会有大量的冗余数据
方式3:Redis的哈希
user:1001 name:Tom
amount:10000
city:beijing
①创建hset,并给hset赋值 hset
hadoop102:6379> HSET hset1 id 1001 name Tom amount 10000 city beijing
(integer) 4
② 从集合 取出 value hget
hadoop102:6379> hget hset1 name
"Tom"
hadoop102:6379> hget hset1 city
"beijing"
③从列出该hash集合的所有field和value hgetall
hadoop102:6379> HGETALL hset1
1) "id"
2) "1001"
3) "name"
4) "Tom"
5) "amount"
6) "10000"
7) "city"
8) "beijing"
④批量修改hash的值 hmset …
hadoop102:6379> HMSET hset1 id 1002 name Jerry
OK
hadoop102:6379> HGETALL hset1
1) "id"
2) "1002"
3) "name"
4) "Jerry"
5) "amount"
6) "10000"
7) "city"
8) "beijing"
⑤查看哈希表 key 中,给定域 field 是否存在
hadoop102:6379> HEXISTS hset1 id
(integer) 1
⑥为为哈希表 key 中的域 field 的值加上增量 1 -1 hincrby
记忆方式:hincrby => hash increase by 步长
hadoop102:6379> HINCRBY hset1 amount 100
(integer) 10100
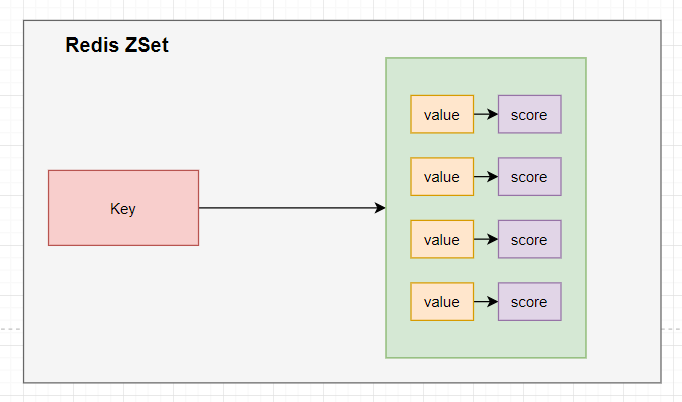
3.6 Redis有序集合(ZSet)
Redis有序集合zset和普通的set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score),这个评分score被用来按照从最低分到最高分的方式排序集合中的成员。
集合的成员是唯一的,但是评分是可以重复的
①创建zset,并添加数据 zadd …
hadoop102:6379> ZADD zset1 100 v1 70 v2 200 v3 150 v4
(integer) 4
②查看zset中的所有数据,返回的结果是按照score升序排序的 zrange
hadoop102:6379> ZRANGE zset1 0 -1
1) "v2"
2) "v1"
3) "v4"
4) "v3"
hadoop102:6379> ZRANGE zset1 0 -1 withscores
1) "v2"
2) "70"
3) "v1"
4) "100"
5) "v4"
6) "150"
7) "v3"
8) "200"
③查看zset的所有数据,返回的结果按照score降序排序的 zrevrange
hadoop102:6379> ZREVRANGE zset1 0 -1 withscores
1) "v3"
2) "200"
3) "v4"
4) "150"
5) "v1"
6) "100"
7) "v2"
8) "70"
④返回有序集合zset中,所有score介于min 和 max之间的元素。zrevrangebyscore key max min [withscores] [limit offset count]
hadoop102:6379> ZRANGEBYSCORE zset1 100 170 withscores
1) "v1"
2) "100"
3) "v4"
4) "150"
hadoop102:6379> ZRANGEBYSCORE zset1 100 170
1) "v1"
2) "v4"
⑤为元素的score加上增量 zincrby
hadoop102:6379> zincrby zset1 1 v3
"201"
hadoop102:6379> zincrby zset1 1 v3
"202"
⑥删除该集合下,指定值的元素 zrem
hadoop102:6379> ZREM zset1 v4
(integer) 1
hadoop102:6379> zrange zset1 0 -1
1) "v2"
2) "v1"
3) "v3"
案例:如何利用zset实现一个文章访问量的排行榜?
hadoop102:6379> zadd topn 1000 v1 2000 v2 1600 v3 1300 v4 600 v5
hadoop102:6379> ZREVRANGE topn 0 3 withscores
1) "v2"
2) "2000"
3) "v3"
4) "1600"
5) "v4"
6) "1300"
7) "v1"
8) "1000"
4 Redis配置文件
Redis大小写不敏感,度量单位为bytes
4.1 INCLUDES
可以再引用其他的配置文件。
当一个机器上当有多个Redis服务的时候,可以抽取出来一些公共的配置,也需要各自有自己特有的配置,比如端口号,检查点文件等。
4.2 网络相关配置
①bind
默认情况下,Redis的bind = 127.0.0.1,只接受本机的访问请求。
- 生产情况下是需要写服务器的地址。
- 可以设置成0.0.0.0任何网段的ip都可以访问redis
- 也可以注释掉。注释掉之后将下面的protected-mode修改为no。



修改完成后需要重启redis服务器。
②protected-mode
保护模式更改为no
③端口号
端口号默认是6379

④timeout
一个空闲的客户端维持多长时间会关闭,0表示关闭该功能。永不关闭。

4.3通用配置
①daemonize
是否设置为守护进程。

②pidfile
存放进程id文件,pid的位置,每个实例会产生一个不同pid文件
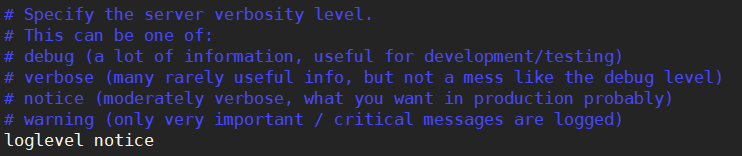
③loglevel
Redis日志等级分为:debug、verbose、notice、warning。默认是notice
④logfile
设置日志文件路径,默认是不产生日志。
这个日志文件的路径!必须是atguigu的,可不能是root的地方。不然没有权限。

⑤databases
默认数据库的数量为16

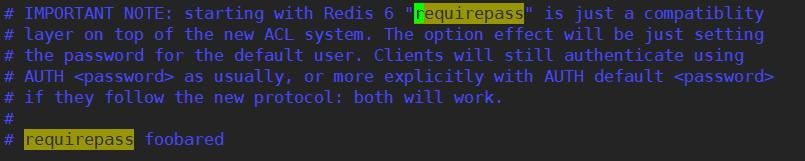
4.4 设置密码
密码是明文的,可以修改。
也可以在redis-cli 客户端内查看、修改密码。
# 查看密码 config get requirepass # 修改密码 config set requirepass "123123" # 输入密码 auth 123123
4.5 Limits限制
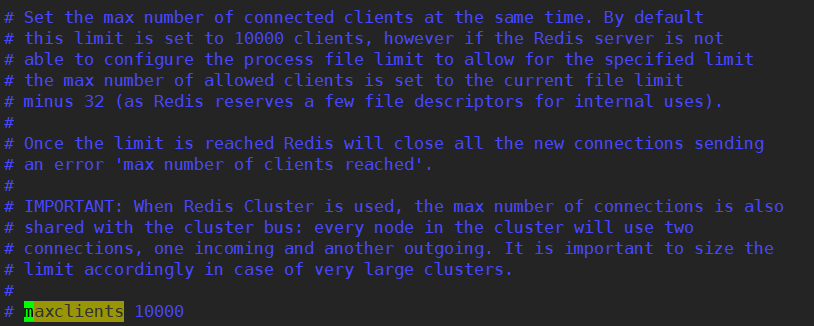
①maxclients
设置redis同时可以与多少个客户端连接。默认是10000个。
如果达到此限制会拒绝新的连接请求,发出“max number of clients reached”回应。
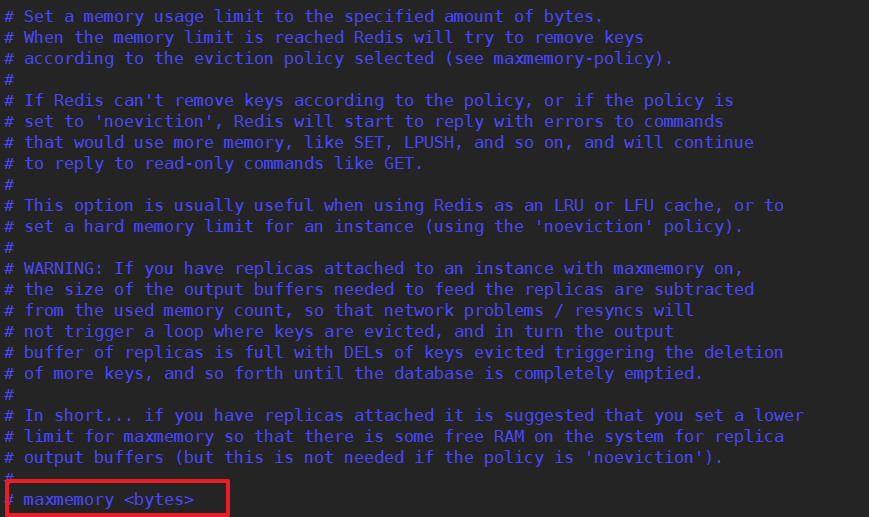
②maxmemory
- 建议必须设置,否则内存占满,会造成服务器宕机。
默认是服务器内存无限制供redis使用。
- 设置redis可以使用的内存量,一旦达到内存使用上限,redis将试图移除内存中的数据,移除的规则根据maxmemory-policy设定。
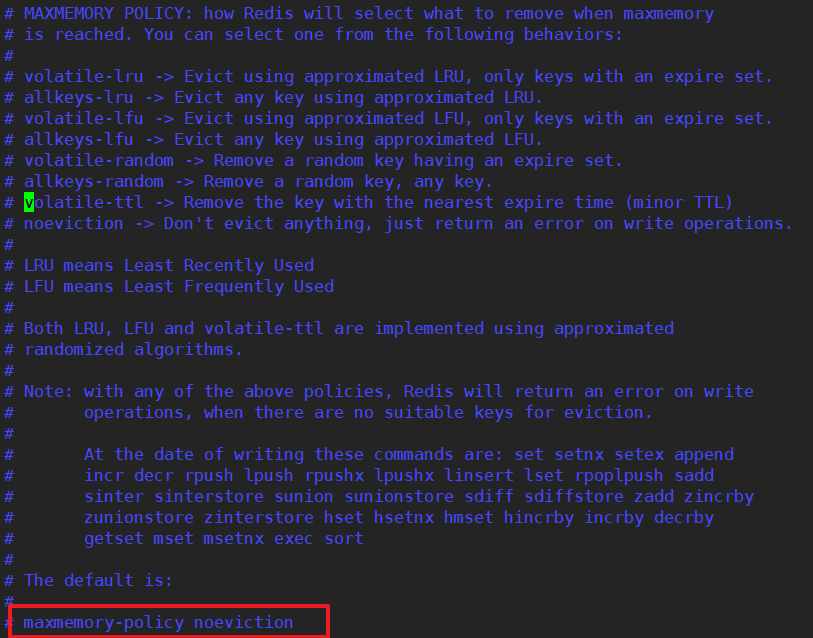
③maxmemory-policy
1) volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
-- 只设置过期时间的key,按时间最少使用移除key
2) allkeys-lru:在所有集合key中,使用LRU算法移除key。"最低访问频率"
-- 所有的key中,按照时间最少使用移除key
3) volatile-lfu:使用LFU算法移除key,只对设置了过期时间的键;(最近最少使用)
-- 只设置过期时间的key,按使用最少 移除key
4) allkeys-lfu:在所有集合key中,使用LFU算法移除key
-- 所有的key中,按照使用最少,移除key
5) volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
-- 在过期的集合中移除随机的key
6) allkeys-random:在所有集合key中,移除随机的key
-- 所有的keu中,随机移除key
7) volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
-- 移除即将要过期的key
noeviction:不进行移除。针对写操作,只是返回错误信息 (默认)
-- 不移除,返回错误信息
-- 上面都提到要移除key,那么移除多少呢?是根据maxmemory-samples取样数决定移除多少。
④maxmemory-samples
设置样本数量,LRU和LFU和TTL算法都是根据样本数量,决定移除多少个key。
一般设置3-7的数字。数字越小样本越不精确,但性能消耗越小。
5 Redis-Jedis
5.1 导入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
5.2 创建测试程序
public class Test1 {
public static void main(String[] args) {
//获取Jedis连接
Jedis jedis = new Jedis("hadoop102", 6379);
String ping = jedis.ping();
System.out.println("测试连接结果:" + ping);
//关闭Jedis连接
jedis.close();
}
}
5.3 Jedis-API: Key
public class Jedis_key01 {
public static void main(String[] args) {
//获取Jedis连接
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO 1 添加key-value
jedis.set("key-01", "99");
jedis.set("key-02", "87");
jedis.set("key-03", "88");
//TODO 2 获取所有的key
Set<String> keys = jedis.keys("*");
//TODO 3 获取key的数量
System.out.println(keys.size());
//TODO 4 遍历所有的key
for (String key : keys) {
System.out.println(key);
}
//TODO 5 exists
System.out.println(jedis.exists("key-01"));
//TODO 6 expire,给已有的key设置过期时间
jedis.expire("key-03", 10);
//TODO 7 ttl,已有key查看剩余的过期时间
System.out.println(jedis.ttl("key-01"));
//TODO 8 get,查看某个key的value值
System.out.println(jedis.get("key-01"));
//关闭Jedis连接
jedis.close();
}
}
5.4 Jedis-API: String
public class Jedis_string01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO mset 添加多个key-value
jedis.mset("str1", "v1", "str2", "v2", "str3", "v3");
//TODO mget 获取多个key的value
System.out.println(jedis.mget("str1", "str2", "str3"));
jedis.close();
}
}
5.5 Jedis-API: List
public class Jedis_list01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO lpush 创建列表,添加元素
jedis.lpush("list-01", "v1", "v2", "v3", "v4");
//TODO rpush 右边添加元素
jedis.rpush("list-01", "b1", "b2", "b3");
//TODO lpop 从左边取出元素
System.out.println(jedis.lpop("list-01"));
//TODO rpop 从右边取出元素
System.out.println(jedis.rpop("list-01"));
//TODO lrange 查看列表中的元素
List<String> lrange = jedis.lrange("list-01", 0, -1);
System.out.println(Arrays.toString(lrange.toArray()));
//TODO lindex 根据索引下标查看元素
System.out.println(jedis.lindex("list-01", 1));
//TODO llen 查看列表的长度
System.out.println(jedis.llen("list-01"));
jedis.close();
}
}
5.6 Jedis-API: Set
public class Jedis_set01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO 创建set,并添加值
jedis.sadd("set-01", "v1", "v1", "v2", "v2", "v3");
//TODO smembers 查看set的所有元素
Set<String> smembers = jedis.smembers("set-01");
System.out.println(Arrays.toString(smembers.toArray()));
//TODO sismember 判断set是否包含value
System.out.println(jedis.sismember("set-01", "v1"));
//TODO scard 返回set的元素个数
System.out.println(jedis.scard("set-01"));
//TODO srem 删除set中的元素
jedis.srem("set-01", "v2", "v3");
Set<String> smembers1 = jedis.smembers("set-01");
System.out.println(Arrays.toString(smembers1.toArray()));
jedis.close();
}
}
5.7 Jedis-API: hash
public class Jedis_hash01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO hset 创建hash,添加元素
jedis.hset("hset-01", "f1", "v1");
//TODO hmset 批量添加元素
HashMap<String, String> map = new HashMap<>();
map.put("id", "1001");
map.put("name", "Tom");
map.put("amount", "10000");
map.put("city", "beijing");
jedis.hmset("hset-01", map);
//TODO hgetAll 获取hset中所有的元素
Map<String, String> hgetAll = jedis.hgetAll("hset-01");
for (Map.Entry<String, String> entry : hgetAll.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
jedis.close();
}
}
5.8 Jedis-API: zset
public class Jedis_zset01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop102", 6379);
//TODO zadd 创建zset,添加元素
jedis.zadd("zset-01", 100, "m1");
//TODO zadd 批量添加元素
HashMap<String, Double> map = new HashMap<>();
map.put("m2", 150.0);
map.put("m3", 80.9);
map.put("m4", 50.0);
jedis.zadd("zset-01", map);
//TODO zrange 查看zset中所有的元素
Set<String> zrange = jedis.zrange("zset-01", 0, -1);
System.out.println(Arrays.toString(zrange.toArray()));
//TODO zrevrangeByScore 按照score降序排序
Set<String> set = jedis.zrevrangeByScore("zset-01", 100, 10);
System.out.println(Arrays.toString(set.toArray()));
jedis.close();
}
}
5.9 连接池
public class RedisUtil {
private static JedisPool jedisPool=null;
public static Jedis getJedisFromPool(){
if(jedisPool==null){
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10); //最大可用连接数
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(2); //最小闲置连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时间
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
jedisPool=new JedisPool(jedisPoolConfig,"hadoop102", 6379 );
return jedisPool.getResource();
}else{
return jedisPool.getResource();
}
}
}
6 Redis持久化
6.1 RDB
RDB,Redis DataBase。
在指定的时间间隔内,将内存中的数据快照Snapshot写入到磁盘,恢复时将快照文件读到内存中。
①RDB备份原理
Redis会单独创建fock一个子进程来进行持久化,会先将数据写入一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化的文件。
Fork:就是复制一个当前进程一样的子进程。
但是复制一个一样的进程肯定会占用内存翻倍啊!这个时候就引入了Linux的“写时复制技术”,就是父进程和子进程会公用同一段物理内存,只有进程空间内容发生变化时,才会复制。
②配置文件
Redis在启动服务器,然后启动客户端以后,当关闭客户端之前,会将内存中的数据备份到一个dump.rdb文件中。

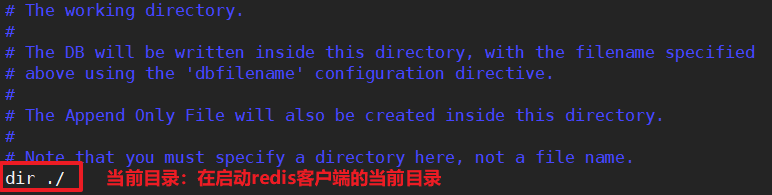
这个文件生成在哪里呢?
默认的情况下,在启动redis客户端的当前目录:
我们修改为/home/atguigu/myredis/redis_db/,注意了前提是创建好这个文件夹。
这个时候有可能会出现一个问题:无法关闭redis服务。
这是因为启动redis-server和redis-cli,当要退出的时候会把内存中的数据备份到dump.rdb文件中,但是如果启动服务的路径是一个root权限的文件路径,但是默认dump.rdb是在启动服务的路径下生成,这个时候就普通用户atguigu启动的服务,就没有在root路径写文件的权限。就无法关闭redis服务了!

③触发RDB快照:保存策略
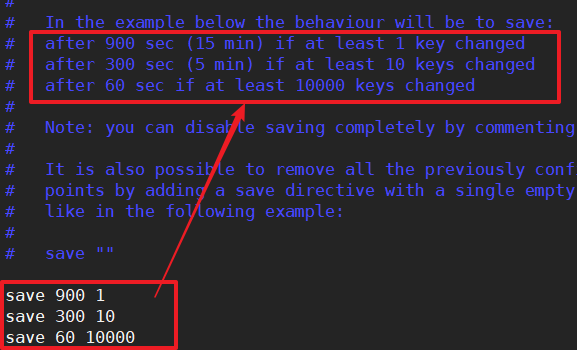
1 配置文件中默认的快照配置:
900s并且1个key发生改变,或者300s并且10个key发生变化,或者60s并且1000个key发生改变。
如果没有达到上面的条件就宕机了,那么数据就丢失了~
2 save & bgsave
如果没有达到上面的快照备份条件,我有一些比较重要的数据也要快照呢?
save:快照当前的数据,并且阻塞住。不建议~
bgsave:Redis在后台异步快照操作,快照同时还可以响应客户端请求。


3 flushall
flushall也会触发快照。不过是造成dump.rdb文件为空,没有意义。

4 配置参数:stop-writes-on-bgsave-error
这个参数什么意思呢?是当Redis无法写入磁盘的时候,是否停止写入操作。
推荐是yes,默认也是yes。
5 配置参数:rdbcompression压缩文件
这个参数是:将内存中的数据快照备份到文件中是否采用LZF压缩算法压缩。
推荐yes,默认也是yes
6 配置参数:rdbchecksum
这个参数是:对备份到文件中的数据是否采用CRC64算法进行数据校验。
推荐yes,默认也是yes
7 动态关闭RDB快照
hadoop102:6379> CONFIG GET *
# 可以查到RDB的save保存策略为:
253) "save"
254) "900 1 300 10 60 10000"
# 停止RDB的save保存策略:
hadoop102:6379> CONFIG SET save ""
6.2 AOF
Append Only File。以日志的形式来记录每个操作(增量保存),将redis执行过程所有的写指令记录下来(读操作不记录),只追加文件但不可以改文件。
这个类似于HBase中的WAL预写日志一样~
①配置文件
默认情况下,AOF关闭。
默认AOF备份的文件名称为:appendonly.aof

②AOF启动/修复/恢复
1 当redis中没有数据的时候:
直接修改配置i文件中的appendonly= yes就可以了。
2 当redis中有数据的时候:
当redis中有数据的时候,直接通过修改配置文件appendonly yes这样会产生appendonly.aof文件,但是文件内没有数据。而redis默认是先读取appendonly.aof文件,这样就会丢失数据了~
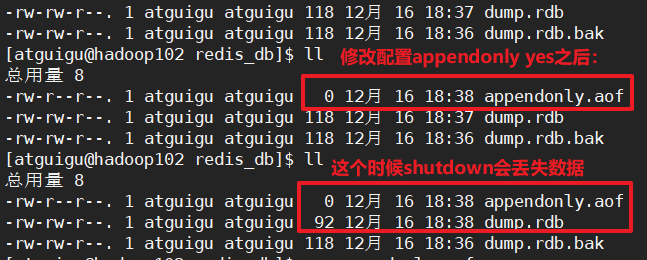
所以说正常的启动AOF的顺序是:
# 启动redis客户端,这个时候会加载dump.rdb中的数据
[atguigu@hadoop102 myredis]$ redis-cli -h hadoop102 -p 6379
# 动态修改appendonly为yes,这样生成的appendonly.aof会加载此时内存中的数据~
hadoop102:6379> CONFIG SET appendonly "yes"
# 这个时候就算关闭服务,也不会发现appendonly.aof为空了
hadoop102:6379> SHUTDOWN
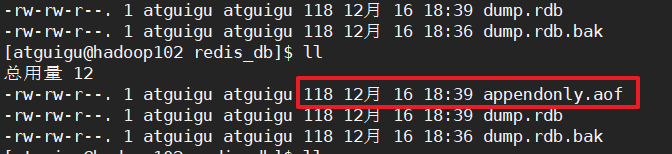
这个时候去修改redis.conf配置文件中的appendonly = yes就可以了
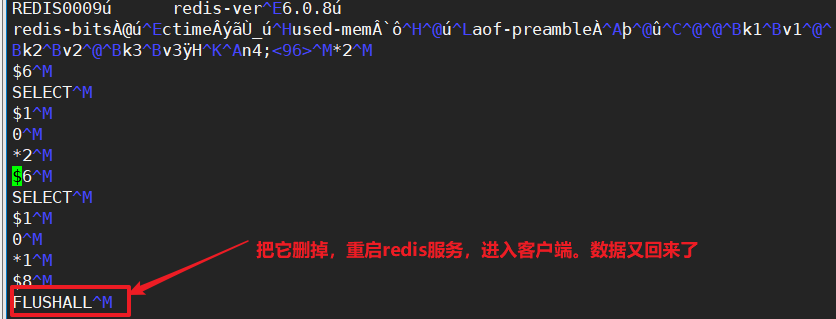
当无意间flushall了怎么办?
flushall会清空数据。如果在开启了appendonly的情况下,是可以恢复的!
编辑appendonly.orf文件:把FLUSHALL这一条记录删掉,也可以恢复。
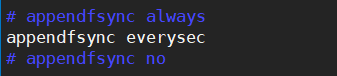
③AOF同步频率设置
- appendfsync always:始终同步,每次Redis的写入都会立刻记入日志
- appendfsync everysec:每秒同步,每秒记入日志一次,如果宕机本秒的数据可能丢失。(默认)
- appendfsync no:redis不主动进行同步,把同步时机交给操作系统。
④AOF的重写原理
AOF采用的是文件追加的方式,为了避免文件越来越大,新增了重写策略,当AOF文件的大小超过所设定的阈值时,会触发AOF文件的重写(压缩)。
如何重写呢?
重写是指把rdb的快照,以二进制
6.3 RDB和AOF对比
-
当RDB和AOF同时开启,系统默认取AOF的数据。
RDB在恢复大的数据集的时候,会更快一些。
RDB一旦没有达到快照条件,或者没有正常关闭,一定会丢失数据。丢失数据的风险比较大
AOF是一个只进行追加的日志文件,丢失数据的概率更低。
AOF会占用更多的磁盘空间
AOF恢复数据的速度更慢
-
那么怎么选择呢?
官方推荐两个都启用。
如果对数据不敏感,可以单独用RDB
不建议单独使用AOF,因为可能会出现bug
如果只做纯内存缓存,可以都不用。
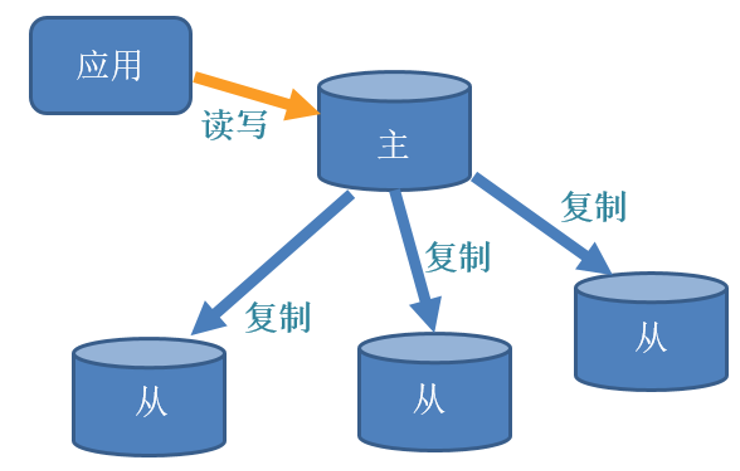
7 Redis主从复制
主机数据更新后根据配置和策略,自动同步到从机的master/slaver机制,Master主要是写;Slaver主要是读
7.1 配置Redis主从复制模式
步骤1:创建一个单独文件夹myredis_ms
[atguigu@hadoop102 ~]$ mkdir myredis_ms
步骤2:复制redis.conf配置文件,作为公共的配置
[atguigu@hadoop102 myredis_ms]$ cp ../myredis/redis.conf ./
修改这个公用的配置文件:
# 1 关闭aof
appendonly no
# 2 修改rdb文件的路径
dir /home/atguigu/myredis_ms/redis_db
# 3 其他共性的配置
#bind 0.0.0.0
protected-mode no
daemonize yes
logfile "/home/atguigu/myredis_ms/redis.log"
步骤3:创建3个不同的配置文件,可以先创建一个
[atguigu@hadoop102 myredis_ms]$ touch redis6379.conf
修改这个配置文件的内容:
# 追踪共性的配置文件
include /home/atguigu/myredis_ms/redis.conf
# 设置pid文件
pidfile /var/run/redis_6379.pid
# 设置端口号
port 6379
# 设置rdb的文件名
dbfilename dump6379.rdb
步骤4:修改剩下的两个配置文件
[atguigu@hadoop102 myredis_ms]$ cp redis6379.conf redis6380.conf
[atguigu@hadoop102 myredis_ms]$ cp redis6379.conf redis6381.conf
修改这两个文件的内容
使用:%s/6379/6380/g 替换6379为6380
# 追踪共性的配置文件
include /home/atguigu/myredis_ms/redis.conf
# 设置pid文件
pidfile /var/run/redis_6380.pid
# 设置端口号
port 6380
# 设置rdb的文件名
dbfilename dump6380.rdb
在6381这个配置文件中多添加一条配置
include /home/atguigu/myredis_ms/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
# 设置优先级
slave-priority 10
步骤5:启动三个redis服务
[atguigu@hadoop102 myredis_ms]$ redis-server redis6379.conf
[atguigu@hadoop102 myredis_ms]$ redis-server redis6380.conf
[atguigu@hadoop102 myredis_ms]$ redis-server redis6381.conf
步骤6:查看三个进程
[atguigu@hadoop102 myredis_ms]$ ps -ef | grep redis
atguigu 1805 1 0 19:40 ? 00:00:00 redis-server *:637
atguigu 1813 1 0 19:41 ? 00:00:00 redis-server *:638
atguigu 1819 1 0 19:41 ? 00:00:00 redis-server *:638
atguigu 1825 1238 0 19:41 pts/0 00:00:00 grep --color=auto
步骤7:启动三个客户端
[atguigu@hadoop102 myredis_ms]$ redis-cli -p 6379
[atguigu@hadoop102 myredis_ms]$ redis-cli -p 6380
[atguigu@hadoop102 myredis_ms]$ redis-cli -p 6381
①手动建立 主从模式(动态,重启失效)
默认情况下三个客户端都是master

那么如何建立三个redis之间的关系呢?
# 在客户端内使用slaveof ip post
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
OK
这个时候可以看到6379是master,6380和6381都是6379的slaver
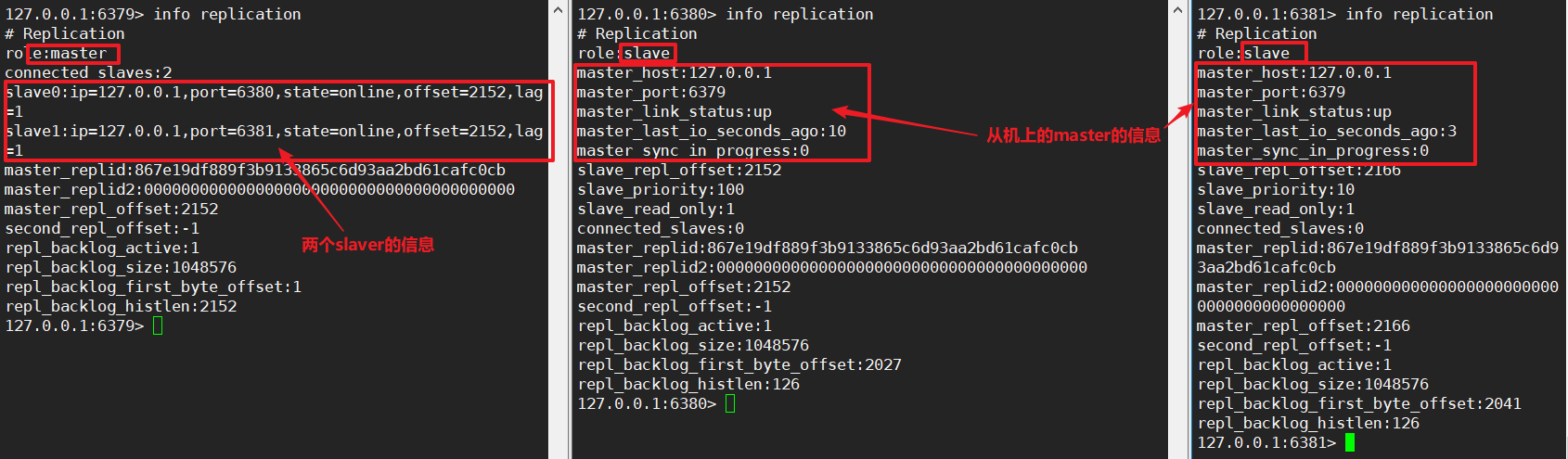
1 在master上创建key-value可以在slaver上查询到
2 master可以写也可以读,但是slaver只能读不能写!
3 slaver也能读到,slaverof 之前的master中的数据!
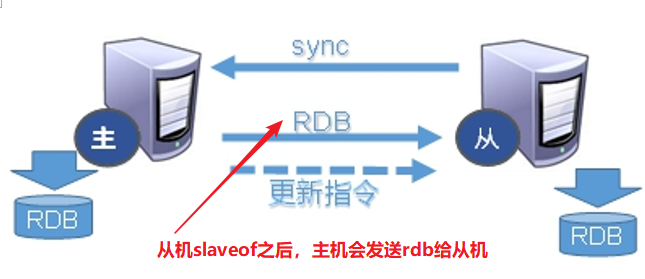
复制原理:
4 当master宕机了,slaver不会改变状态,还是slaver!
5 当master重新上线,还是master!
6 当6379 <-- 6380 <-- 6381 形成这种串行的主从关系,还是只有6379可以写,6380和6381只能读
7 当6379 <-- 6380 <-- 6381 形成这种串行的主从关系,6379的数据可以传递到6381
串行的主从关系可以降低6379这台机器的压力,但是若6380挂掉了,6381也不能正常!
8 串行情况下 当主机挂掉了,那么怎样才能让6380成为主机呢?
6381还是6380的从机
127.0.0.1:6380> SLAVEOF no one
②手动建立 主从模式(写死在配置)
上面再redis客户端内使用slaveof ip post的方式,当重启服务的时候,又重新都称为master了
那么要想一值生效,可以将slaveof ip post 写死再配置文件中
redis6380.conf内添加:
# 跟随6379
slaveof 127.0.0.1 6379
redis6381.conf内添加
# 跟随6380
slaveof 127.0.0.1 6380
再次重启之后,查看信息:
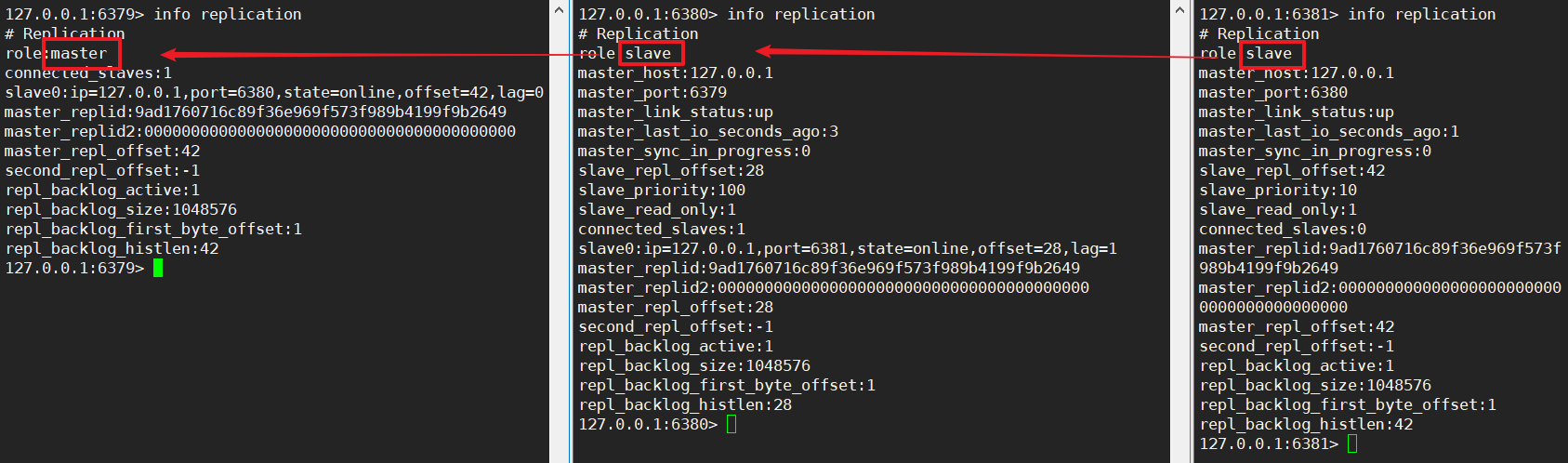
7.2 哨兵模式(sentinel)
上面两种的建立主从模式,太麻烦了,需要手动的设置slaveof ip post 的方式。
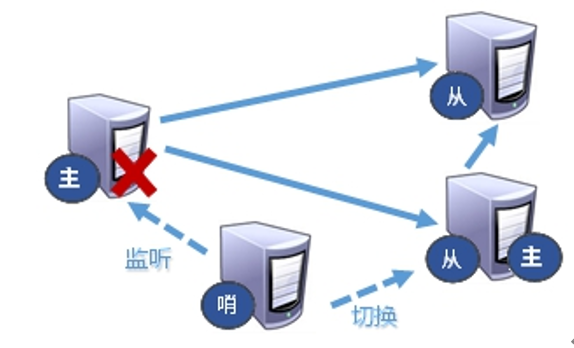
哨兵模式:是设置一个或多个哨兵节点,监控master的状态,当master挂掉,自动选举生成master。
根据slave-priority 10优先级的选择多个slaver中谁成为新的master。优先级100最低 --> 0最高
③主从模式(哨兵模式)
步骤1:切换到1主2从的模式,6379 <-- 6380/6381
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
步骤2:在/home/atguigu/myredis_ms/下新建一个sentinel.conf文件,在里面填写:
sentinel monitor mymaster 127.0.0.1 6379 1
# 其中mymaster是给监控对象起的别名
# 1 表示至少有1个哨兵同意迁移的数量
步骤3:启动哨兵:
[atguigu@hadoop102 myredis_ms]$ redis-sentinel sentinel.conf
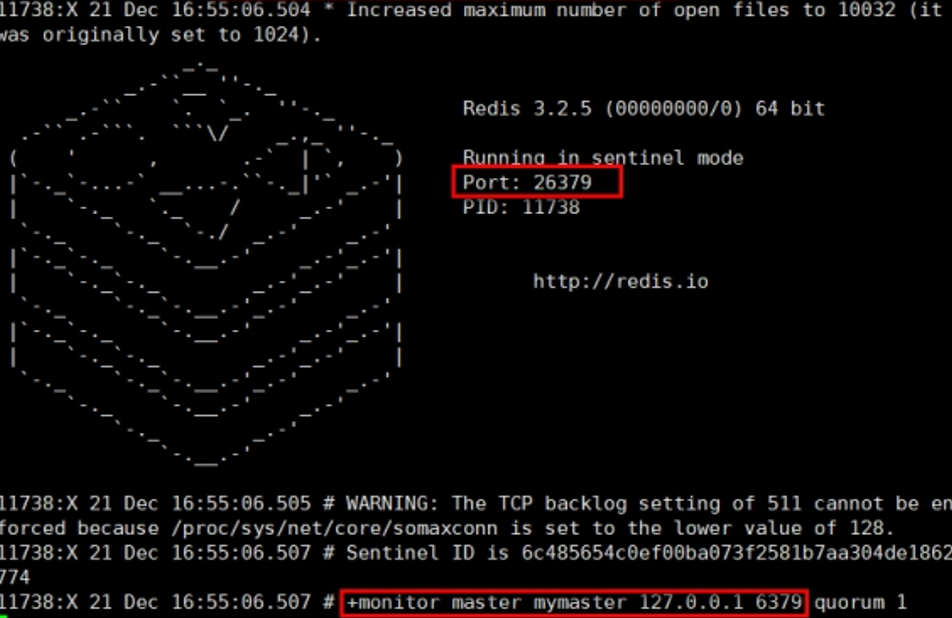
步骤4:当6379master宕机,哨兵将会选举出新的主机master
大约10s左右可以看到哨兵窗口,切换到了新的master。
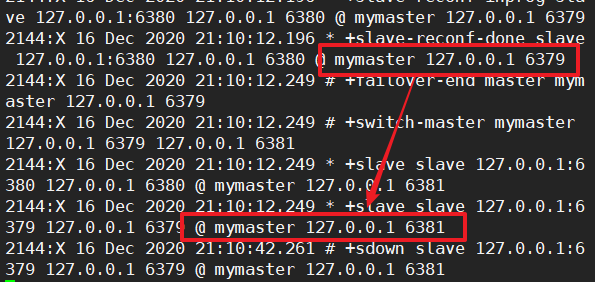
为什么会选择6381为master主机呢?
是因为6381的配置设置了优先级为10
选择的条件为:
- 选择优先级靠前的,越小越好
- 选择偏移量大的,偏移量越大表示slaver中有master中的数据越多。
- 选择runid最小的服务,每个redis实例启动会随机生成一个40位的runid
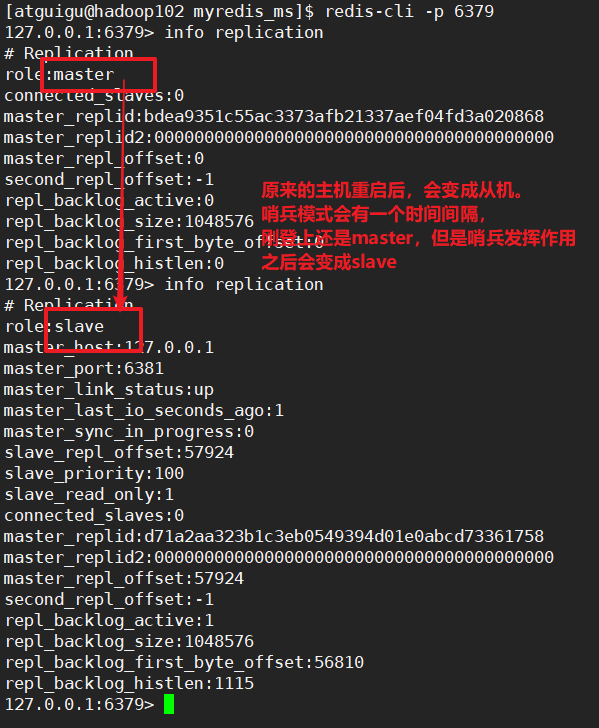
原来的主机重新启动之后,是什么状态呢?
原来的主机重启之后是slaver。
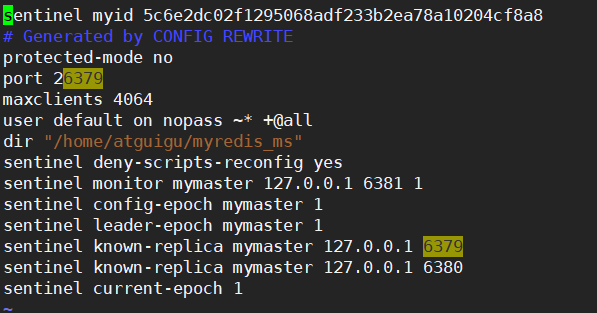
开启了哨兵模式之后
[atguigu@hadoop102 myredis_ms]$ vim sentinel.conf
复制延时
由于所有的写操作都是在master上,然后同步到slaver上,所以从master同步到slaver机器有一定的延时。当系统繁忙的时候,延迟问题会更加严重,slaver机器数量的增加也会加重这个问题。
7.3 JedisSentinelPool
JedisUtils
注意点1:远程连接RedisSentinelPool,sentineSet.add(“hadoop102:26379”);必须是ip或者hostname(已配hosts),不能填127.0.0.1。
修改sentinel.conf,将127.0.0.1改为hadoop102
//TODO 步骤1 声明一个JedisSentinelPool 哨兵池
public static JedisSentinelPool jedisSentinelPool = null;
public static Jedis getJedisFromSentinel(){
if (jedisSentinelPool == null) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10); //最大可用连接数
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(2); //最小闲置连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时机
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
//TODO 步骤2 new一个HashSet里面放哨兵的ip + port
Set sentineSet = new HashSet();
sentineSet.add("hadoop102:26379");
//TODO 步骤3 new哨兵池,参数1是哨兵配置内的别名,参数2是哨兵集合,参数3是Jedis池配置
jedisSentinelPool = new JedisSentinelPool("mymaster", sentineSet, jedisPoolConfig);
return jedisSentinelPool.getResource();
}else {
return jedisSentinelPool.getResource();
}
}
public class JedisTest01 {
public static void main(String[] args) {
//TODO 从哨兵池中获取redis
Jedis jedis = JedisUtils.getJedisFromSentinel();
//TODO 测试ping
String ping = jedis.ping();
System.out.println(ping);
//TODO 获取当前库中的key的值
Set<String> keys = jedis.keys("*");
for (String key : keys) {
System.out.println(key);
}
//TODO 关闭资源
jedis.close();
}
}
8 Redis集群
主从复制的Redis配置模式,也会存在一个问题:不管有几台机器,还是只有一个主master。
虽然Redis的可用性提高了,也能够自动的选择主从了。但是还是一台master提供服务。
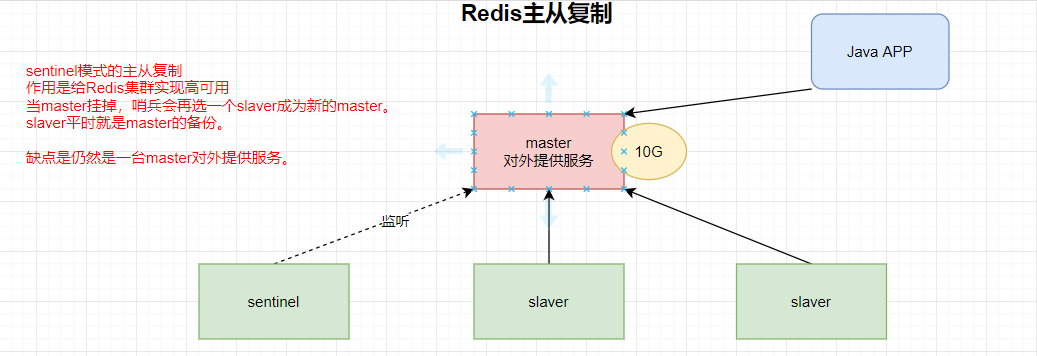
8.1 Redis集群模式的发展
方案一
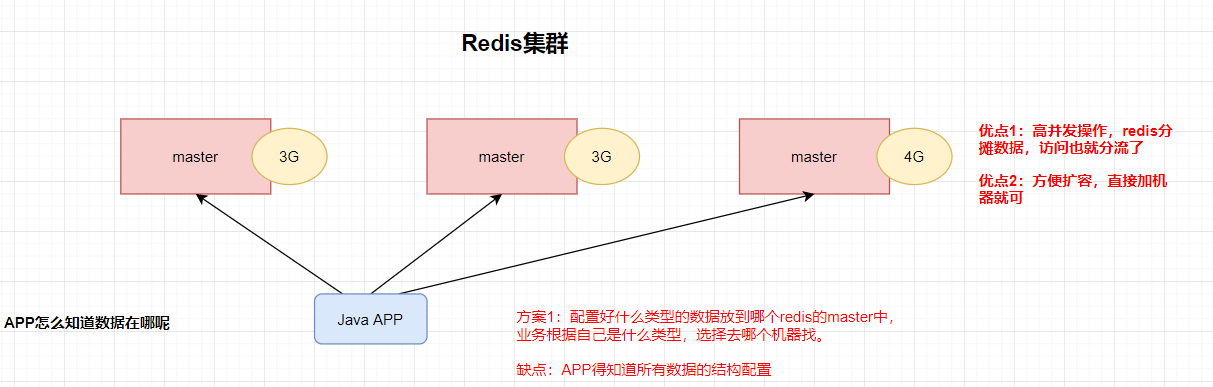
方案二:中间件
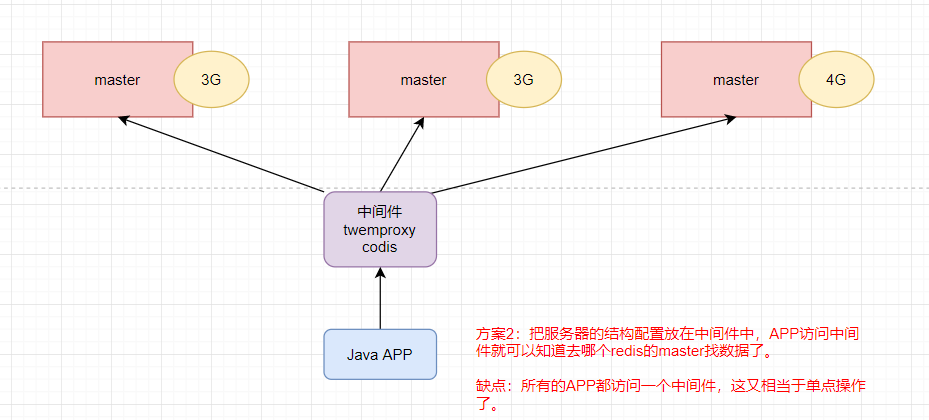
方案三:去中心化集群
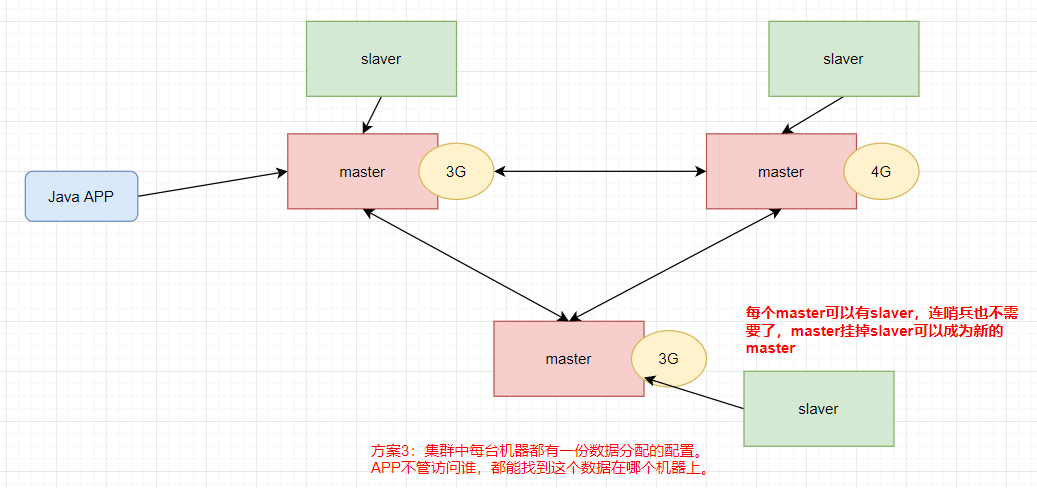
8.2 Redis集群配置
制作6个实例,6379、6380、6381、6389、6390、6391
步骤1:基本配置
公用的redis.conf
# 1 注释bind,让所有网段的ip都能连接
#bind 127.0.0.1
# 2 关闭保护模式
protected-mode no
# 3 开启后台服务
daemonize yes
# 4 redis日志位置
logfile "/home/atguigu/myredis_cluster/redis.log"
# 5 rdb快照文件位置
dir /home/atguigu/myredis_cluster/redis_db/
# 6 关闭aof
appendonly no
步骤2:实例独有的配置redis6379.conf…;修改6个实例的配置
include /home/atguigu/myredis_cluster/redis.conf
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
# 开启集群模式
cluster-enabled yes
# 集群所有机器配置的文件,(取好名字,自己生成)
cluster-config-file nodes-6379.conf
# 超时时间,当master15s没有上线,则从slaver选一个当新的master
cluster-node-timeout 15000
步骤3:启动6个实例的redis服务
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6379.conf
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6380.conf
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6381.conf
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6389.conf
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6390.conf
[atguigu@hadoop102 myredis_cluster]$ redis-server redis6391.conf
步骤4:查看6个实例的进程
[atguigu@hadoop102 myredis_cluster]$ ps -ef | grep redis
atguigu 1506 1 0 10:57 ? 00:00:00 redis-server *:6379 [cluster]
atguigu 1512 1 0 10:57 ? 00:00:00 redis-server *:6380 [cluster]
atguigu 1518 1 0 10:57 ? 00:00:00 redis-server *:6381 [cluster]
atguigu 1524 1 0 10:57 ? 00:00:00 redis-server *:6389 [cluster]
atguigu 1530 1 0 10:57 ? 00:00:00 redis-server *:6390 [cluster]
atguigu 1536 1 0 10:57 ? 00:00:00 redis-server *:6391 [cluster]
atguigu 1542 1115 0 10:57 pts/0 00:00:00 grep --color=auto redis
步骤5:建立6个实例之间的集群关系
[atguigu@hadoop102 myredis_cluster]$ redis-cli --cluster create --cluster-replicas 1 192.168.255.102:6379 192.168.255.102:6380 192.168.255.102:6381 192.168.255.102:6389 192.168.255.102:6390 192.168.255.102:6391
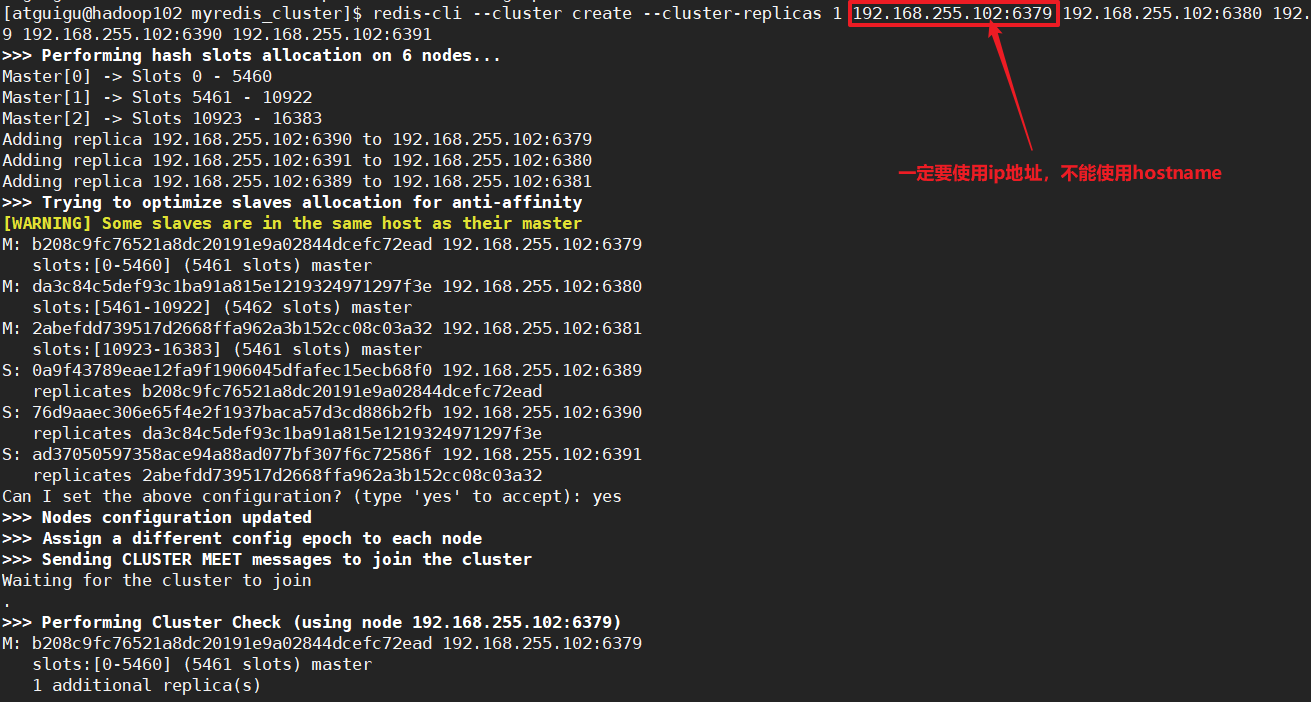
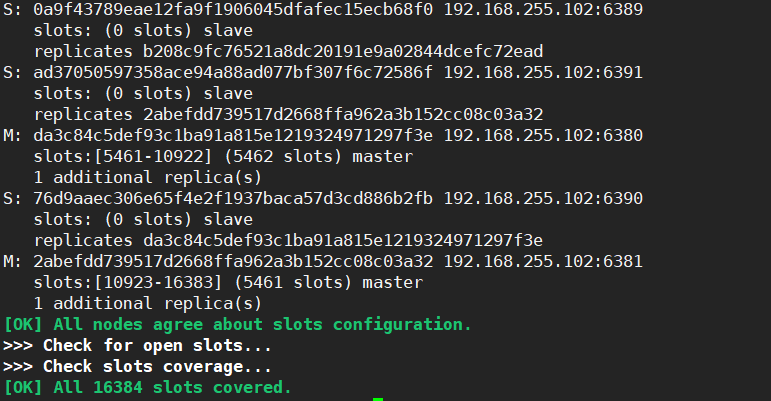
错误情况!使用hostname,会找不到地址
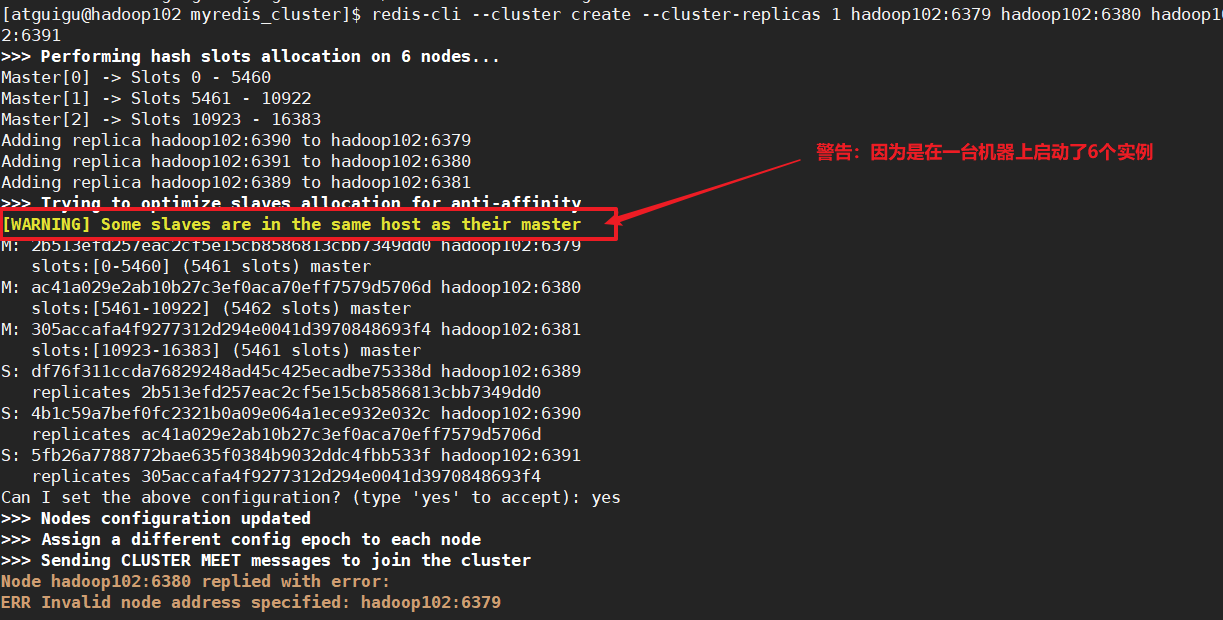
[atguigu@hadoop102 myredis_cluster]$ redis-cli --cluster create --cluster-replicas 1 hadoop102:6379 hadoop102:6380 hadoop102:6381 hadoop102:6389 hadoop102:6390 hadoop102:6391
步骤6:查看6台机器的集群配置文件
问题:如果集群没有配成功
可以看看:
配置中的dir /home/atguigu/myredis_cluster/redis_db/,快照和集群配置文件的路径。
启动集群建立集群间关系的时候要使用ip地址,不能使用hostname
步骤7:普通方式登录客户端
普通方式登录客户端,直接进入的读主机,不能写操作。会出现MOVED重定向操作。
[atguigu@hadoop102 myredis_cluster]$ redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set key18 v18
(error) MOVED 6098 192.168.255.102:6380
步骤8:集群方式登录客户端
以集群方式登录客户端,写操作的时候,会根据数据所在的solts自动切换到对应的写master
[atguigu@hadoop102 myredis_cluster]$ redis-cli -c -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set k18 v18
-> Redirected to slot [10853] located at 192.168.255.102:6380
OK
192.168.255.102:6380>
步骤9:查看集群信息cluster nodes
192.168.255.102:6380> CLUSTER NODES

8.3 Redis集群分配原则
一个集群至少要有三个master节点
在启动redis-cli的时候会指定分配的副本数:
--cluster-replicas 1
表示为集群中的每一个主节点创建一个从节点。
分配原则:尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
8.4 Redis集群模式中的slots
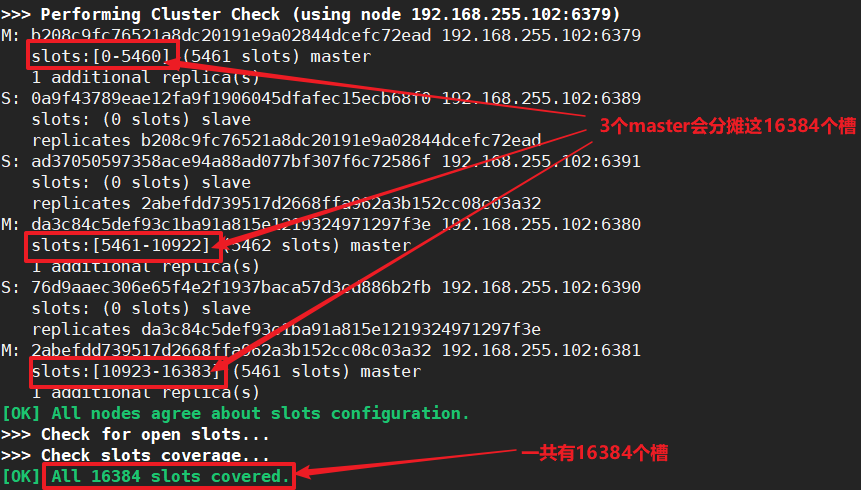
一个Redis集群中包含16384个槽,数据库中的每个键都数据16384个槽中的一个。
在我们的集群中:
节点A6379:负责处理0-5460号槽
节点B6380:负责处理5461-10922号槽
节点C6381:负责处理10923-16383号槽
集群中的key怎样决定去哪一个槽呢??
CRC16(key) % 16384来计算键key属于哪个槽,其中CRC16(key)用于计算键key和CRC16检验和。
①在集群中录入值
在Redis客户端录入,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis
实例地址和端口
[atguigu@hadoop102 ~]$ redis-cli -p 6390
127.0.0.1:6390> set k1 v1
(error) MOVED 12706 192.168.255.102:6381
在Redis客户端录入、查询键值,redis会计算出该key应该送往的插槽
[atguigu@hadoop102 ~]$ redis-cli -c -p 6390
127.0.0.1:6390> set k111 v111
-> Redirected to slot [9614] located at 192.168.255.102:6380
OK
不在一个slot下的键值,是不能使用mget、mset多键操作
[atguigu@hadoop102 ~]$ redis-cli -c -p 6380
127.0.0.1:6380> mset k188 v188 k189 v189 k190 v190
(error) CROSSSLOT Keys in request don't hash to the same slot
那么怎么实现一次插入多个key-value呢?
使用{槽的别名},让key中{}内相同内容的键值放到一个slot中去。
127.0.0.1:6380> mset k1{
cluster} v1 k2{
cluster} v2 k3{
cluster} v3
-> Redirected to slot [14041] located at 192.168.255.102:6381
②在集群中查询值
在集群中查询单个的键值
192.168.255.102:6381> get k18
-> Redirected to slot [10853] located at 192.168.255.102:6380
"v18"
在集群中查看某个槽的别名所在的槽号
192.168.255.102:6381> CLUSTER KEYSLOT cluster
(integer) 14041 # 返回cluster这个槽的别名所在的槽号
查看某个槽中值的个数
192.168.255.102:6381> CLUSTER COUNTKEYSINSLOT 14041
(integer) 3
从某个槽中取出n个值
192.168.255.102:6381> CLUSTER GETKEYSINSLOT 14041 10
1) "k1{cluster}"
2) "k2{cluster}"
3) "k3{cluster}"
8.5 故障恢复
如果某个master宕机,它的从节点能否自动成为新的master呢?
注意:15s超时

宕机的master重新上线之后呢?
宕机的重新上线就只能是slaver了。

如果某一段槽的机器全部宕机了呢 ?
根据cluster-require-full-coverage 决定redis服务是否还能继续使用。
- cluster-require-full-coverage 为yes,那么整个集群都挂掉。(默认yes)
- cluster-require-full-coverage 为no,那么该槽的数据全部不能使用,也无法存储。

8.6 集群模式Jedis开发
//TODO 1 声明一个JedisCluster
public static JedisCluster jedisCluster = null;
public static JedisCluster getJedisCluster(){
if (jedisCluster == null){
//TODO JedisPoolConfig基本配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10);
jedisPoolConfig.setMaxIdle(5);
jedisPoolConfig.setMinIdle(5);
jedisPoolConfig.setBlockWhenExhausted(true);
jedisPoolConfig.setMaxWaitMillis(2000);
jedisPoolConfig.setTestOnBorrow(true);
//TODO 3 添加Redis集群的地址
Set<HostAndPort> hostAndPortSet = new HashSet<>();
hostAndPortSet.add(new HostAndPort("hadoop102", 6379));
hostAndPortSet.add(new HostAndPort("hadoop102", 6380));
//TODO 2 创建JedisCluster对象,传入hostAndPortSet对象
jedisCluster = new JedisCluster(hostAndPortSet, jedisPoolConfig);
return jedisCluster;
}else {
return jedisCluster;
}
}
public class TestJedisCluster {
public static void main(String[] args) {
//TODO 获取Jedis集群对象
JedisCluster jedisCluster = JedisUtils.getJedisCluster();
//通过集群对象操作key-value
jedisCluster.set("k10086", "v10086");
System.out.println(jedisCluster.get("k10086"));
// Set<String> keys = jedisCluster.keys("*");
// for (String key : keys) {
// System.out.println(key);
// }
//TODO 不用释放资源~因为这是一个池子,池子不用关,会自动分配资源~
}
}