1 HBase概述
1.1 什么是Hbase

Hbase的原型是Google的BigTable论文。三篇论文分别对应的技术:
HDFS – GFS、MapReduce – MR、HBase – BigTable
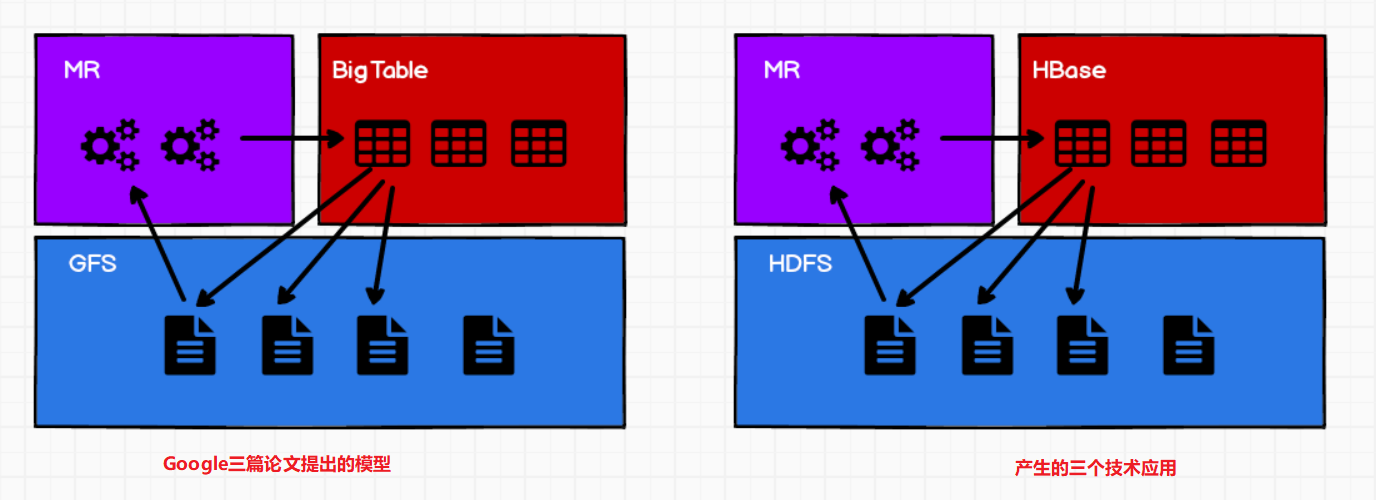
从功能上看HBase是一个高可靠性(可以配置高可用)、高性能(存储性能强)、面向列(列族)、可伸缩的分布式存储系统。
1.2 为什么用HBase
查询的列太多会影响性能
MySql一张表的最大的列数为4096列。
查询的行太多也会影响性能
MySql的单表最大容量是4G
数据行数一般在500万到2000万之间,会导致数据库阻塞
表随着业务的变化,增加新的列(动态列)
| HBase | MySql |
|---|---|
| 列式、NoSql数据库 | 行式、关系型数据库 |
| 只支持byte[]类型(便于压缩) | 支持多种数据类型 |
| 支持海量数据存储 | 500万-2000万行 |
| 存储速度快,但是查询速度慢 | 查询速度快 |
| 只支持rowkey的索引 | 支持主键索引 |
| 事务只支持到row级别 | 完整的事务 |
| 支持多个版本存在,有时间戳版本 | 直接修改元数据 |
1.3 HBase结构
①HBase逻辑架构
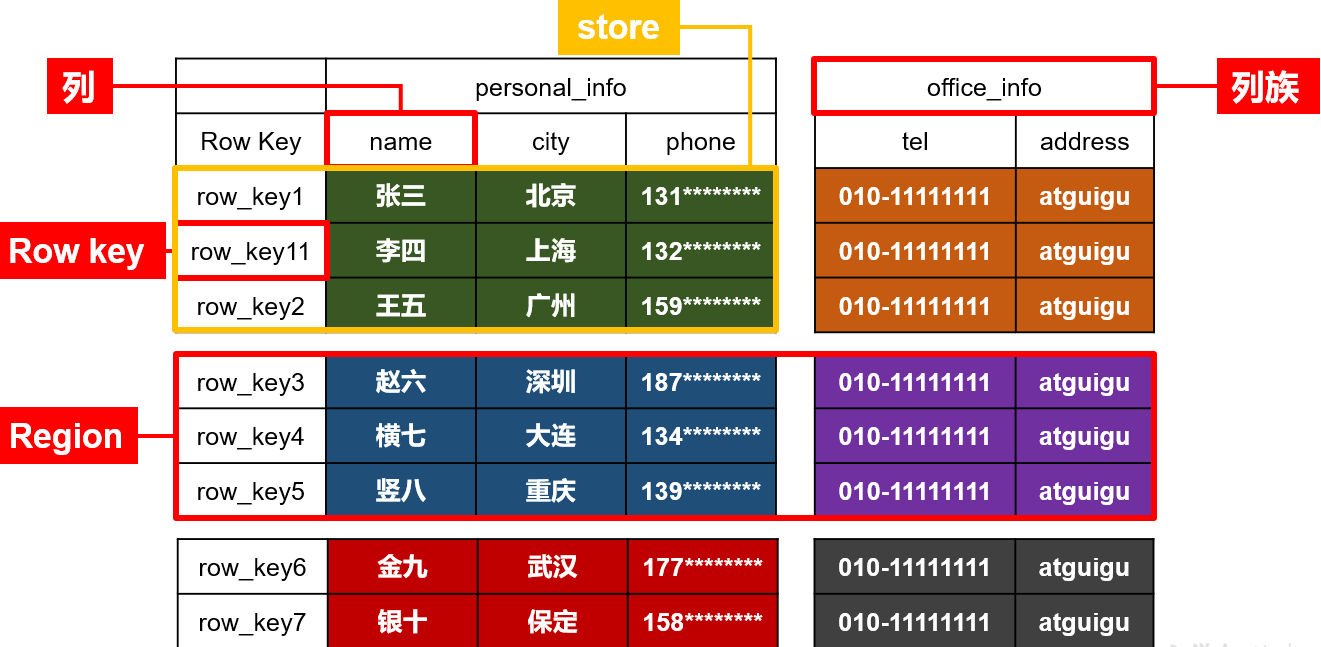
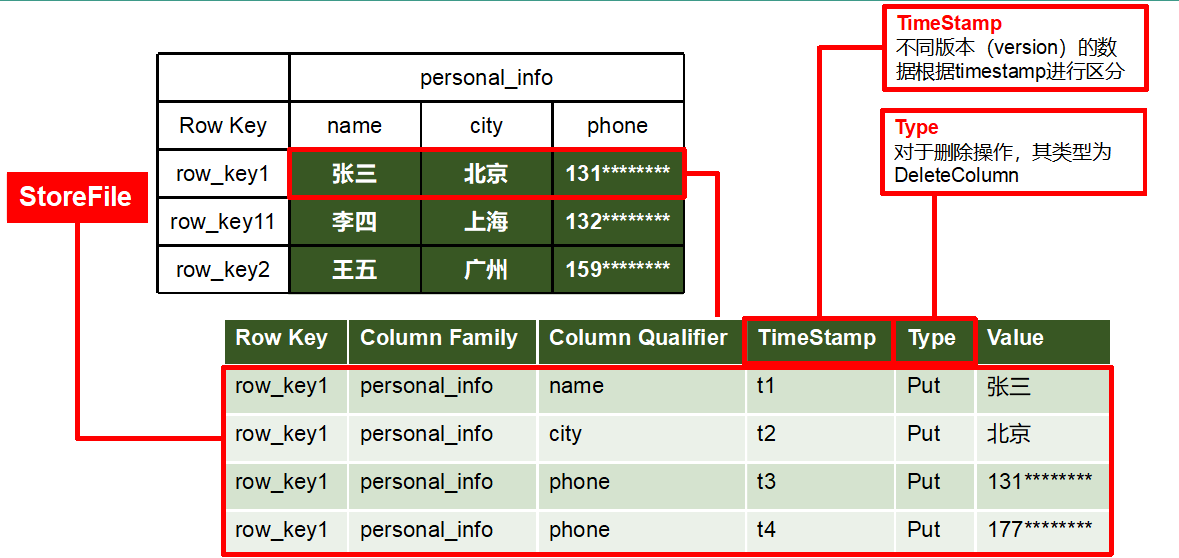
②HBase物理架构
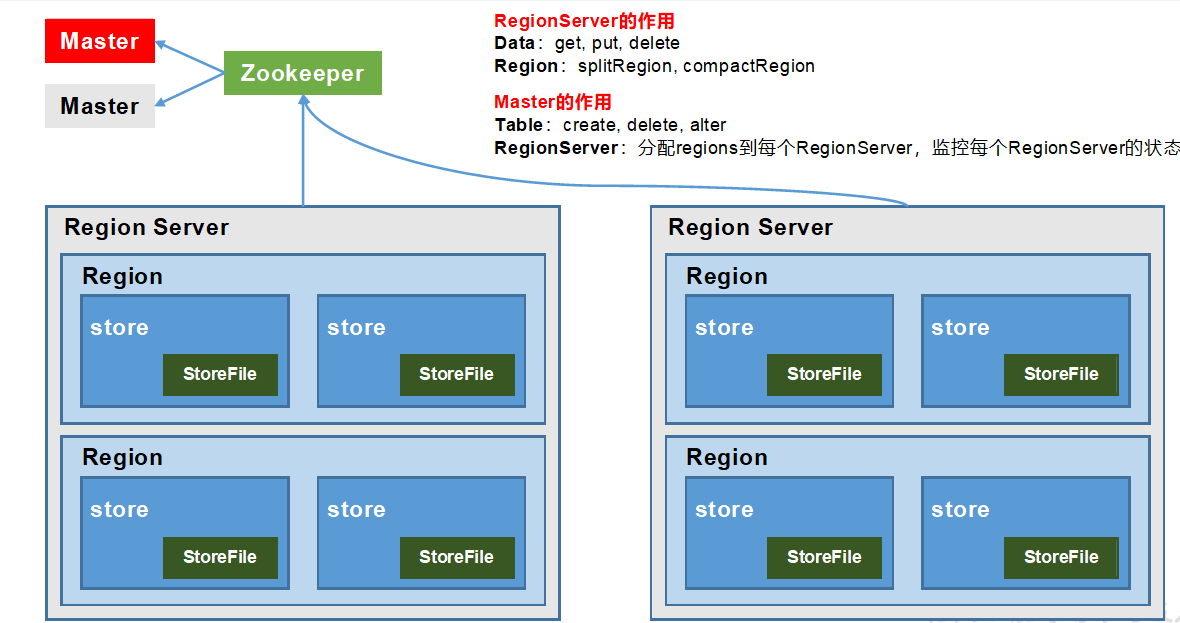
③HBase基础架构
每一个列族一个store。
1.4 HBase结构概念
①NameSpace
命名空间,类似于数据库中的database概念,每个命名空间内有多个表。
HBase有两个自带的命名空间:default和hbase
- hbase存放HBase内置的表
- default是默认创建表,所放的命名空间
②Table
类似于数据库中的表的概念。
HBase定义表的时候,只需要声明表名和列族即可,不需要声明具体的列。
create ‘命名空间:表名’, ‘列族’
③RowKey
分区的RowKey是有序的!
HBase表中的每行数据,都是由一个RowKey和多个Column(列)组成,按照RowKey的字典序排列的!
④Column
HBase中每个列由Column Family(列族)和Column Qualifier(列限定符)进行限定。比如:info:name
⑤TimeStamp
用来表示不同的版本(Version),系统自动加上该字段,其值是写入HBase的时间
⑥ Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
1.5 HBase架构概念
①RegionServer
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
②Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
③Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
防止Master出现异常情况,无法对RegionServer做操作。HBase默认情况下,含有内置的ZK,但是我们一般使用外置ZK,包含了Master的管理信息。
④HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
1.6 HBase操作原理
①增加
使用put指令,put ‘命名空间:表名’, ‘行键rowkey’, ‘列族:列名’, ‘列值’
时间戳是由HBase自动生成的,而且存储的是数据的单元格信息,而不是一行数据。
②修改
修改数据时,逻辑上需要先查询数据,再进行修改,对于HBase来讲,性能非常低,所以不能采用这种方式来实现修改操作。HBase采用了新增数据的方式来覆盖旧的数据,来达到修改的目的。
③插入
HBase本身就是用于存储海量数据的数据库,所以对于插入操作进行了优化,性能非常的快,而且HBase本身就是基于HDFS文件系统,所以数据量增大不是很大的问题。如果业务中存在历史数据操作的话,这种方式更加合理。
数据插入后,读取数据时,其实依赖于时间戳(版本),HBase会把最新的数据查询出来。
④删除
HBase中的删除,其实也是增加新的数据,只不过进行了特殊处理,不让HBase可以查询出来。
如果数据删除的话,那么在查询的时候其实时看不到的,但是HBase中会增加新数据,这样做的原因主要是考虑到性能的原因,但是并不是说,这个数据会永久的保留,也会真正的删除,由内部的处理机制在特定的时间进行数据的真实删除。这个操作我们称之为compaction,文件合并的时候,会删除。
⑤查询
查询可以全表扫描查询(scan)
增加查询范围(scan,StartRow(包含),StopRow(不包含))
查询一条(RowKey)数据(get),可以限定列名或列族的名称