人工神经网络与Matlab实现
What is ANN

常用激活函数

神经网络的分类:
- – 按照连接方式,可以分为:前向神经网络 vs. 反馈(递归)神经网络
- – 按照学习方式,可以分为:有导师学习神经网络 vs. 无导师学习神经网络
- – 按照实现功能,可以分为:拟合(回归)神经网络 vs. 分类神经网络
BP神经网络
简介
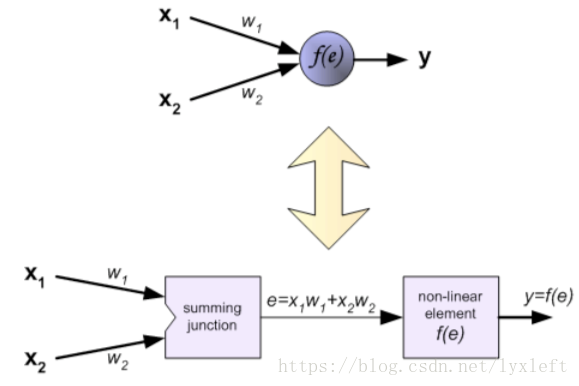
所谓BP只是神经学习训练的一个方法,是一种有监督的学习方法。BP的激活函数要求可微。
传播:
- Forward propagation of a training pattern’s input through the neural network in order to generate the propagation’s output activations.
- Back propagation of the propagation’s output activations through the neural network using the training pattern’s target in order to generate the deltas of all output and hidden neurons.
权重更新:
- Multiply its output delta and input activation to get the gradient of the weight.
- Bring the weight in the opposite direction of the gradient by subtracting a ration of it from the weight.
计算原理
我们举一个4层的例子,如下图,有2个隐含层。
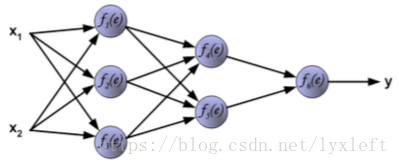
针对每一个神经元,它的计算方法是:
例如,第一个隐藏层的第一个神经元的计算结果是:
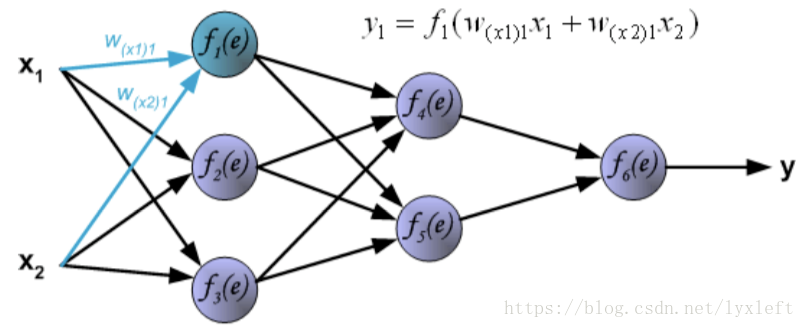

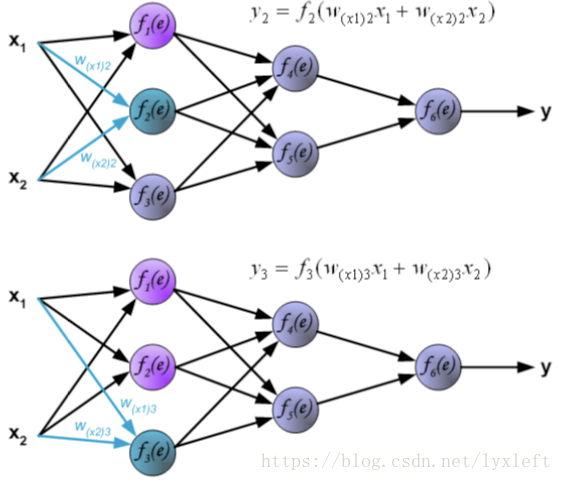
另外两个神经元,同理可得:
接下来,我们计算第二层隐含层:
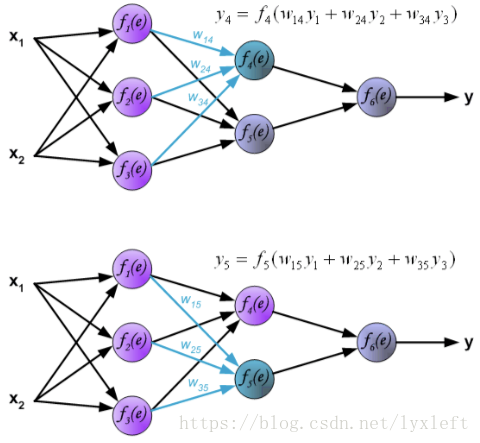
搞定之后,可以计算最后一层了:
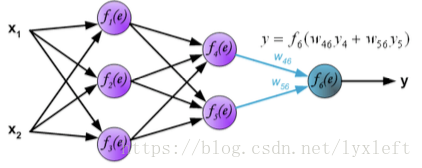
得到神经网络的输出y了,接下来就要做误差分析了。如,计算一个delta = z - y。这里只是一种简单的计算形式。一般我们还会使用误差平方和,如delta = 0.5(z-y)^2。
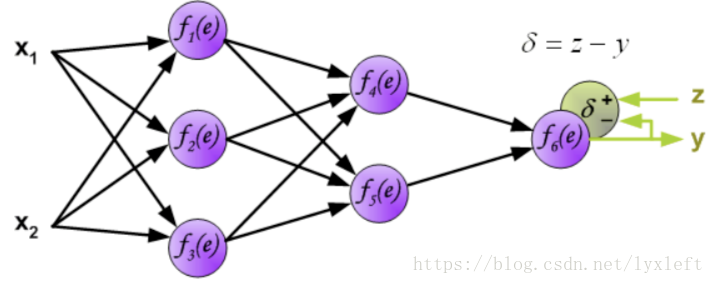
得到误差后,反向传播给前面的神经元,先乘上权重,得到某个神经元(如下图,f4)的误差:
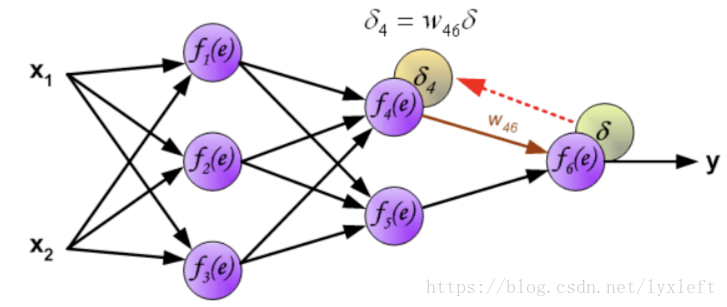
继续反向传播:
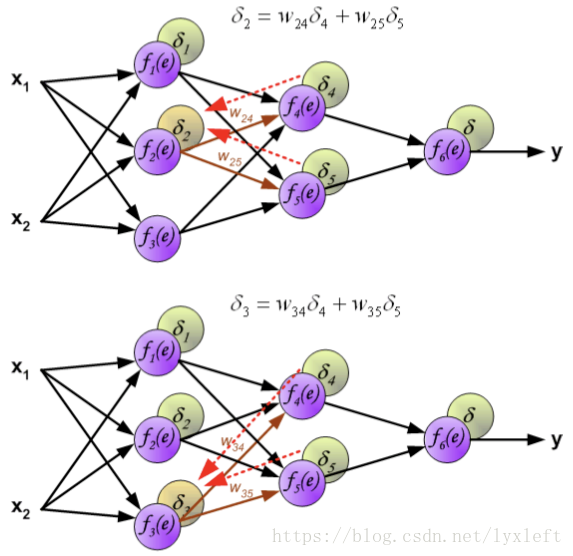
如此一直反向传播到第一层,这样就可以开始修正神经元之间的连接权重了。
我们用到梯度下降法:原来的权重+一个误差项。
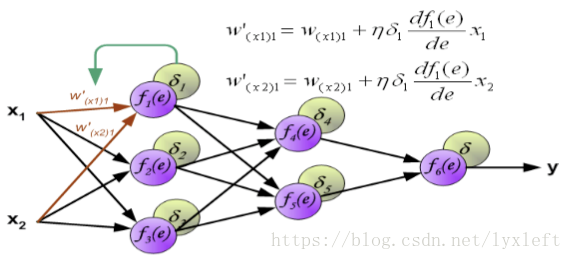
误差项中含义:yita 即学习率、delta 是反向传播回来的后面那一层的误差、激活函数求导形成的微分项。
下面是分别修正f2和f3神经元的权值:
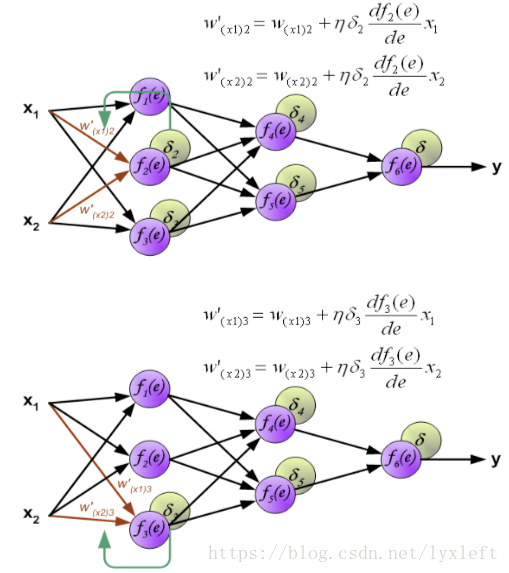
同理,第二个隐含层的权值修正:
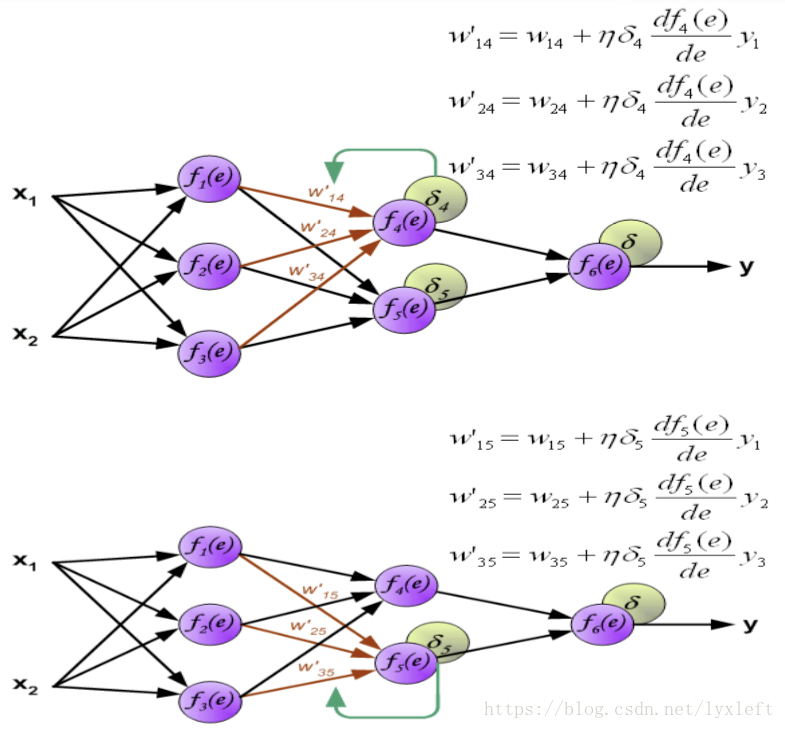
输出层:
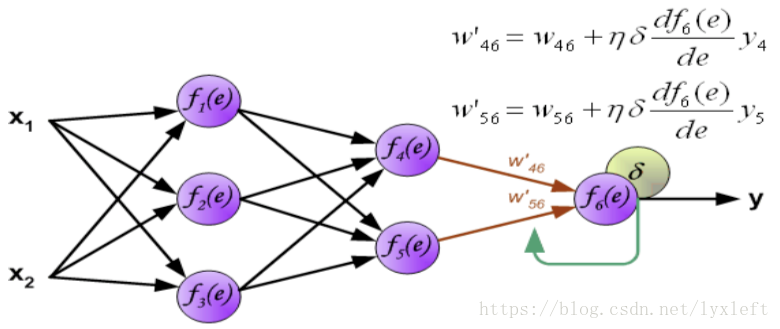
如此一来就完成了一遍每一层连接权值的修正。
接下来就可以进行下一轮的循环:利用修正完的模型,再输入一个样本,正向传播等到y,再求delta,再反向传播回来逐层修复权值。如此循环反复就是BP神经网络的计算原理了。
数据归一化
什么是归一化?
——将数据映射到[0, 1]或[-1, 1]区间或其他的区间。
为什么要归一化?
- – 输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
- – 数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。(防止数据湮灭等现象)
- – 由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活 函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
- – S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。这样数据的差异就会失去意义!
归一化的算法:
- y = ( x - min )/( max - min ) —— 【0,1】
- – y = 2 * ( x - min ) / ( max - min ) - 1 —— 【-1,1】
训练集、验证集、测试集,什么关系?
在有监督(supervise)的机器学习中,数据集常被分成2~3个,即:训练集(train set) 验证集(validation set) 测试集(test set)。
一般需要将样本分成独立的三部分训练集(train set),验证集(validation set)和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。
样本少的时候,上面的划分就不合适了。常用的是留少部分做测试集。然后对其余N个样本采用K折交叉验证法。就是将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据。特别的K取N,就是留一法(leave one out)。
Matlab重点函数
重点函数解读:
-
normalize()
-
N = normalize(A)按向量返回A中数据的 z 值(中心为 0、标准差为 1)。- 如果
A是向量,则normalize对整个向量进行运算。 - 如果
A是矩阵、表或时间表,则normalize分别对数据的每个列进行运算。 - 如果
A为多维数组,则normalize沿大小不等于 1 的第一个数组维度进行运算。
N = normalize(A,dim)返回维度dim上的 z 值。例如,normalize(A,2)对每个行进行归一化。 - 如果
-
-
Vector and Matrix Data
Normalize data in a vector and matrix by computing the z-score.
Create a vector v and compute the z-score, normalizing the data to have mean 0 and standard deviation 1.
v = 1:5;
N = normalize(v)
Create a matrix B and compute the z-score for each column. Then, normalize each row.
B = magic(3)
N1 = normalize(B)
N2 = normalize(B,2) -
归一化方法,指定为以下选项之一:
方法 说明 'zscore'均值为 0、标准差为 1 的 z值'norm'2-范数 'scale'按标准差缩放 'range'将数据范围缩放至 [0,1] 'center'对数据进行中心化以使其均值为 0
-
解决人工神经网络模拟预测问题研究
BP网络的MATLAB实践
重点函数解读:
- mapminmax
- – Process matrices by mapping row minimum and maximum values to [-1 1]
- – [Y, PS] = mapminmax(X, YMIN, YMAX) 归一化的信息保存到结构体PS中(自定义MIN,MAX范围)
- – Y = mapminmax(‘apply’, X, PS) 已知的归一化规则PS用于归一化其他信息
- – X = mapminmax(‘reverse’, Y, PS) 反归一化
- newff
- – Create feed-forward backpropagation network 创建前向型神经网络
- – net = newff(P, T, [S1 S2…S(N-l)], {TF1 TF2…TFNl}, BTF, BLF, PF, IPF, OPF, DDF) 输入样本、输出样本、传递函数……等其他参数。
- train
- – Train neural network 训练神经网络
- – [net, tr, Y, E, Pf, Af] = train(net, P, T, Pi, Ai)
- sim
- – Simulate neural network 模拟预测
- – [Y, Pf, Af, E, perf] = sim(net, P, Pi, Ai, T) Y即最终预测的输出
参数对BP神经网络性能的影响:
1、隐含层神经元节点个数 ?
可以手动调整为其他个数,查看预测结果。
2、激活函数类型的选择 ?
newff里会默认设计好(tansig,双S型),还可以是其他函数。
3、学习率?——参考网络资料。
4、初始权值与阈值:
今后可以利用遗传算法对权值和阈值进行优化。
手动操作推荐方法:
1、交叉验证(cross validation):训练集(training set)+验证集(validation set)+测试集(testing set)。保证足够的样本,可以分到这三波里。
2、留一法(Leave one out, LOO):如果样本数据较少时使用。每一次都留一个样本做预测,其他用于训练。
利用工具箱
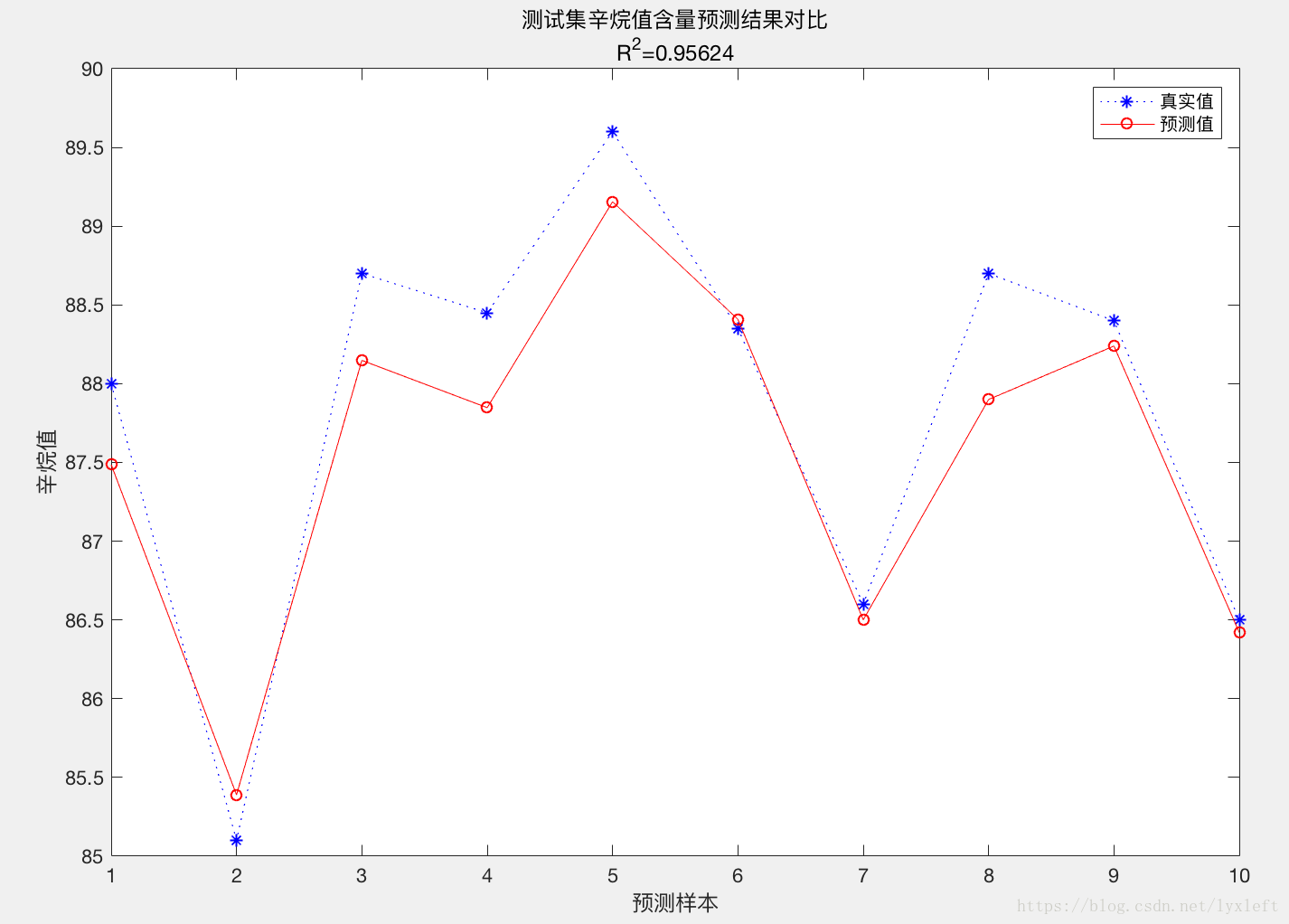
【举例】对汽油辛烷值含量做预测:
预测结果:
matlab代码:
%% I. 清空环境变量
clear all
clc
%% II. 训练集/测试集产生
%%
% 1. 导入数据
load spectra_data.mat
%%
% 2. 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集――50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集――10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
%% III. 数据归一化
[p_train, ps_input] = mapminmax(P_train,0,1);
p_test = mapminmax('apply',P_test,ps_input);
[t_train, ps_output] = mapminmax(T_train,0,1);
%% IV. BP神经网络创建、训练及仿真测试
%%
% 1. 创建网络
net = newff(p_train,t_train,9);
%%
% 2. 设置训练参数
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-3;
net.trainParam.lr = 0.01;
%%
% 3. 训练网络
net = train(net,p_train,t_train);
%%
% 4. 仿真测试
t_sim = sim(net,p_test);
%%
% 5. 数据反归一化
T_sim = mapminmax('reverse',t_sim,ps_output);
%% V. 性能评价
%%
% 1. 相对误差error
error = abs(T_sim - T_test)./T_test;
%%
% 2. 决定系数R^2
R2 = (N * sum(T_sim .* T_test) - sum(T_sim) * sum(T_test))^2 / ((N * sum((T_sim).^2) - (sum(T_sim))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
%%
% 3. 结果对比
result = [T_test' T_sim' error']
%% VI. 绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim,'r-o')
legend('真实值','预测值')
xlabel('预测样本')
ylabel('辛烷值')
string = {'测试集辛烷值含量预测结果对比';['R^2=' num2str(R2)]};
title(string)
test2
clc
clear all
close all
%bp 神经网络的预测代码
%载入输出和输入数据
load C:\Users\amzon\Desktop\p.txt;
load C:\Users\amzon\Desktop\t.txt;
%保存数据到matlab的工作路径里面
save p.mat;
save t.mat;%注意t必须为行向量
%赋值给输出p和输入t
p=p;
t=t;
%数据的归一化处理,利用mapminmax函数,使数值归一化到[-1.1]之间
%该函数使用方法如下:[y,ps] =mapminmax(x,ymin,ymax),x需归化的数据输入,
%ymin,ymax为需归化到的范围,不填默认为归化到[-1,1]
%返回归化后的值y,以及参数ps,ps在结果反归一化中,需要调用
[p1,ps]=mapminmax§;
[t1,ts]=mapminmax(t);
%确定训练数据,测试数据,一般是随机的从样本中选取70%的数据作为训练数据
%15%的数据作为测试数据,一般是使用函数dividerand,其一般的使用方法如下:
%[trainInd,valInd,testInd] = dividerand(Q,trainRatio,valRatio,testRatio)
[trainsample.p,valsample.p,testsample.p] =dividerand(p,0.7,0.15,0.15);
[trainsample.t,valsample.t,testsample.t] =dividerand(t,0.7,0.15,0.15);
%建立反向传播算法的BP神经网络,使用newff函数,其一般的使用方法如下
%net = newff(minmax§,[隐层的神经元的个数,输出层的神经元的个数],{隐层神经元的传输函数,输出层的传输函数},‘反向传播的训练函数’),其中p为输入数据,t为输出数据
%tf为神经网络的传输函数,默认为’tansig’函数为隐层的传输函数,
%purelin函数为输出层的传输函数
%一般在这里还有其他的传输的函数一般的如下,如果预测出来的效果不是很好,可以调节
%TF1 = ‘tansig’;TF2 = ‘logsig’;
%TF1 = ‘logsig’;TF2 = ‘purelin’;
%TF1 = ‘logsig’;TF2 = ‘logsig’;
%TF1 = ‘purelin’;TF2 = ‘purelin’;
TF1=‘tansig’;TF2=‘purelin’;
net=newff(minmax§,[10,1],{TF1 TF2},‘traingdm’);%网络创建
%网络参数的设置
net.trainParam.epochs=10000;%训练次数设置
net.trainParam.goal=1e-7;%训练目标设置
net.trainParam.lr=0.01;%学习率设置,应设置为较少值,太大虽然会在开始加快收敛速度,但临近最佳点时,会产生动荡,而致使无法收敛
net.trainParam.mc=0.9;%动量因子的设置,默认为0.9
net.trainParam.show=25;%显示的间隔次数
% 指定训练参数
% net.trainFcn = ‘traingd’; % 梯度下降算法
% net.trainFcn = ‘traingdm’; % 动量梯度下降算法
% net.trainFcn = ‘traingda’; % 变学习率梯度下降算法
% net.trainFcn = ‘traingdx’; % 变学习率动量梯度下降算法
% (大型网络的首选算法)
% net.trainFcn = ‘trainrp’; % RPROP(弹性BP)算法,内存需求最小
% 共轭梯度算法
% net.trainFcn = ‘traincgf’; %Fletcher-Reeves修正算法
% net.trainFcn = ‘traincgp’; %Polak-Ribiere修正算法,内存需求比Fletcher-Reeves修正算法略大
% net.trainFcn = ‘traincgb’; % Powell-Beal复位算法,内存需求比Polak-Ribiere修正算法略大
% (大型网络的首选算法)
%net.trainFcn = ‘trainscg’; % ScaledConjugate Gradient算法,内存需求与Fletcher-Reeves修正算法相同,计算量比上面三种算法都小很多
% net.trainFcn = ‘trainbfg’; %Quasi-Newton Algorithms - BFGS Algorithm,计算量和内存需求均比共轭梯度算法大,但收敛比较快
% net.trainFcn = ‘trainoss’; % OneStep Secant Algorithm,计算量和内存需求均比BFGS算法小,比共轭梯度算法略大
% (中型网络的首选算法)
%net.trainFcn = ‘trainlm’; %Levenberg-Marquardt算法,内存需求最大,收敛速度最快
% net.trainFcn = ‘trainbr’; % 贝叶斯正则化算法
% 有代表性的五种算法为:‘traingdx’,‘trainrp’,‘trainscg’,‘trainoss’, ‘trainlm’
%在这里一般是选取’trainlm’函数来训练,其算对对应的是Levenberg-Marquardt算法
net.trainFcn=‘trainlm’;
[net,tr]=train(net,trainsample.p,trainsample.t);
%计算仿真,其一般用sim函数
[normtrainoutput,trainPerf]=sim(net,trainsample.p,[],[],trainsample.t);%训练的数据,根据BP得到的结果
[normvalidateoutput,validatePerf]=sim(net,valsample.p,[],[],valsample.t);%验证的数据,经BP得到的结果
[normtestoutput,testPerf]=sim(net,testsample.p,[],[],testsample.t);%测试数据,经BP得到的结果
%将所得的结果进行反归一化,得到其拟合的数据
trainoutput=mapminmax(‘reverse’,normtrainoutput,ts);
validateoutput=mapminmax(‘reverse’,normvalidateoutput,ts);
testoutput=mapminmax(‘reverse’,normtestoutput,ts);
%正常输入的数据的反归一化的处理,得到其正式值
trainvalue=mapminmax(‘reverse’,trainsample.t,ts);%正常的验证数据
validatevalue=mapminmax(‘reverse’,valsample.t,ts);%正常的验证的数据
testvalue=mapminmax(‘reverse’,testsample.t,ts);%正常的测试数据
%做预测,输入要预测的数据pnew
pnew=[313,256,239]’;
pnewn=mapminmax(pnew);
anewn=sim(net,pnewn);
anew=mapminmax(‘reverse’,anewn,ts);
%绝对误差的计算
errors=trainvalue-trainoutput;
%plotregression拟合图
figure,plotregression(trainvalue,trainoutput)
%误差图
figure,plot(1:length(errors),errors,’-b’)
title(‘误差变化图’)
%误差值的正态性的检验
figure,hist(errors);%频数直方图
figure,normplot(errors);%Q-Q图
[muhat,sigmahat,muci,sigmaci]=normfit(errors);%参数估计 均值,方差,均值的0.95置信区间,方差的0.95置信区间
[h1,sig,ci]= ttest(errors,muhat);%假设检验
figure, ploterrcorr(errors);%绘制误差的自相关图
figure, parcorr(errors);%绘制偏相关图
运行之后的,结果如下:
**
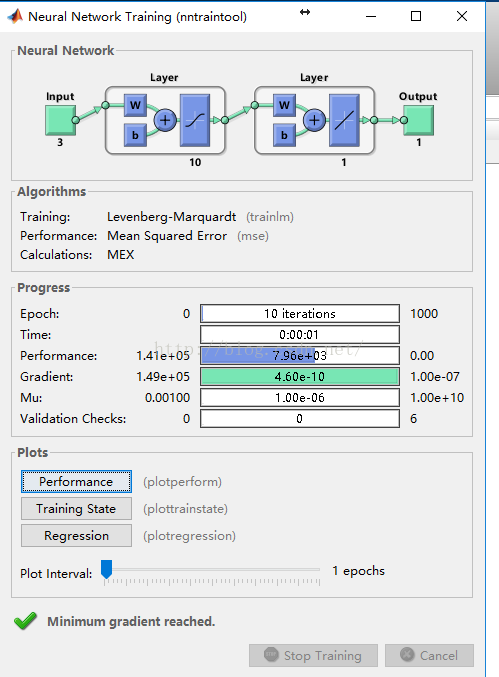
**
**BP神经网络的结果分析图
**
**
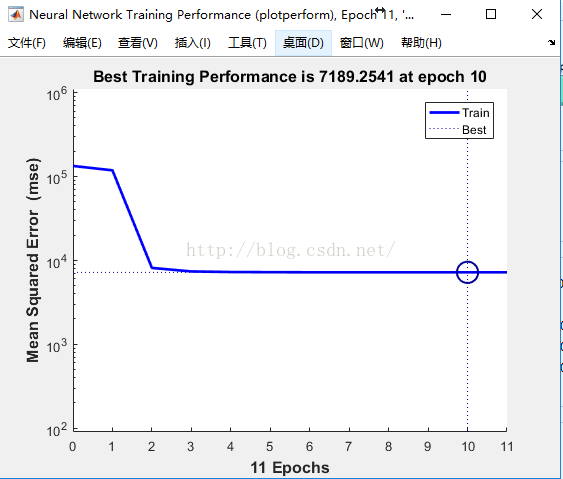
**
**训练数据的梯度和均方误差之间的关系图
**
**
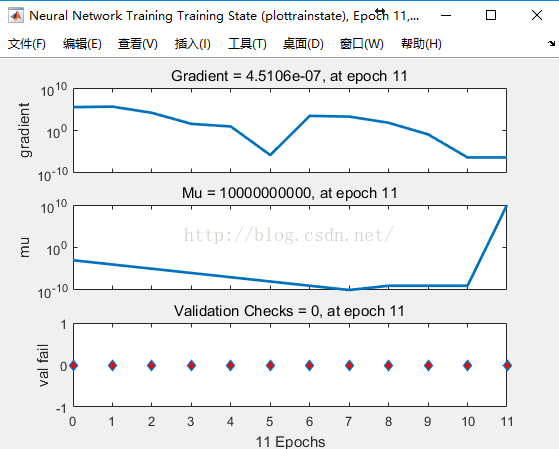
**
**验证数据的梯度与学习次数
**
**
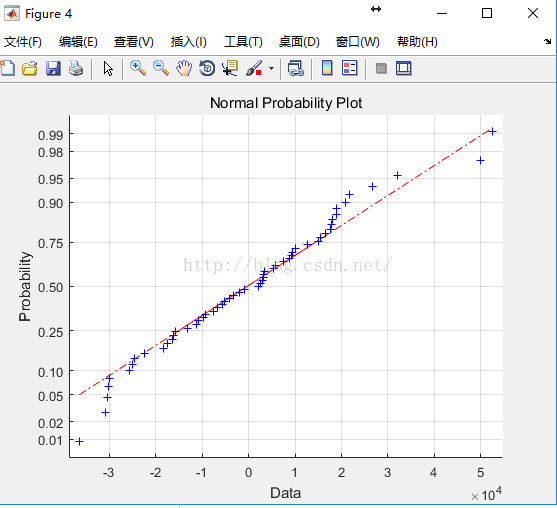
**
**残差的正态的检验图(Q-Q图)
**
GUI
1:在输入命令里面输入nntool命令,或者在应用程序这个选项下找到Netrual Net Fitting 这个应用程序,点击打开,就能看见如下界面
**
**
**
**
**
**
**
**
**
**
2:输入数据和输出数据的导入(在本文中选取了matlab自带的案例数据)
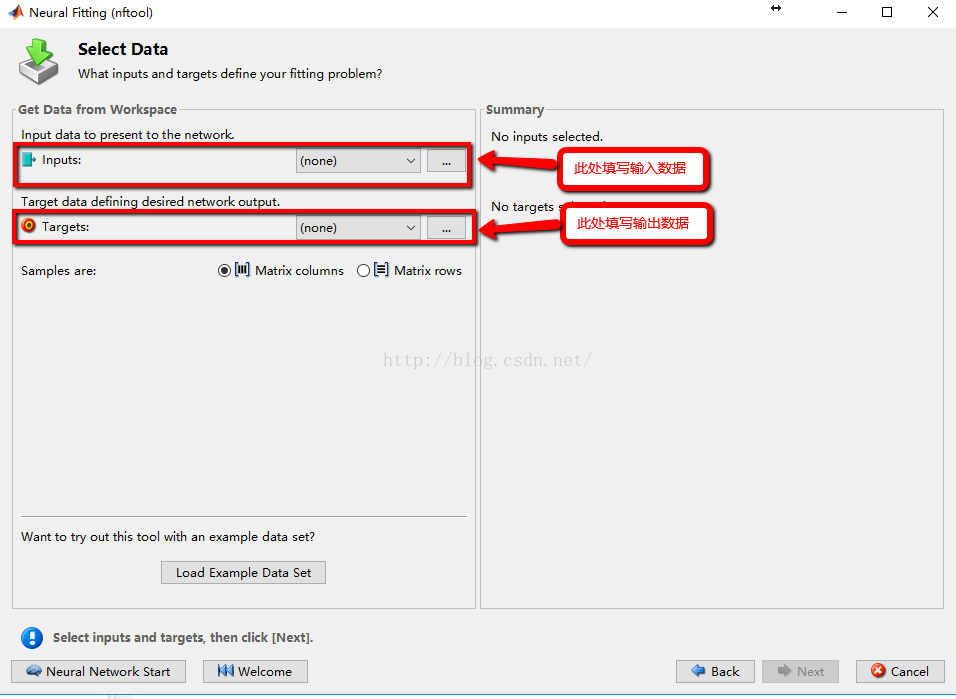
**
3:随机选择三种类型的数据所占的样本量的比例,一般选取默认即可
**
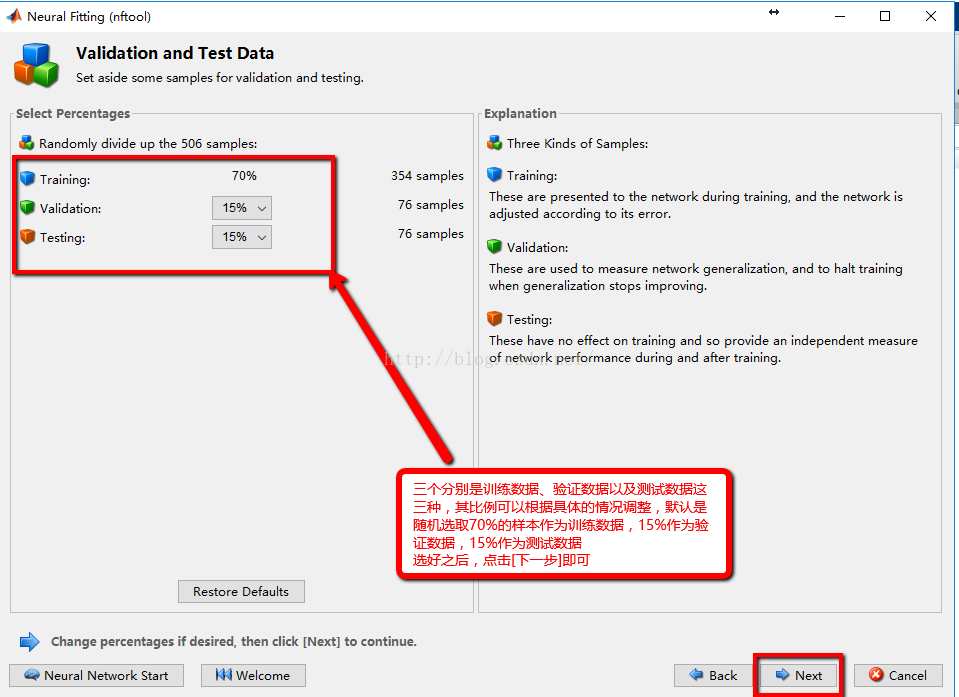
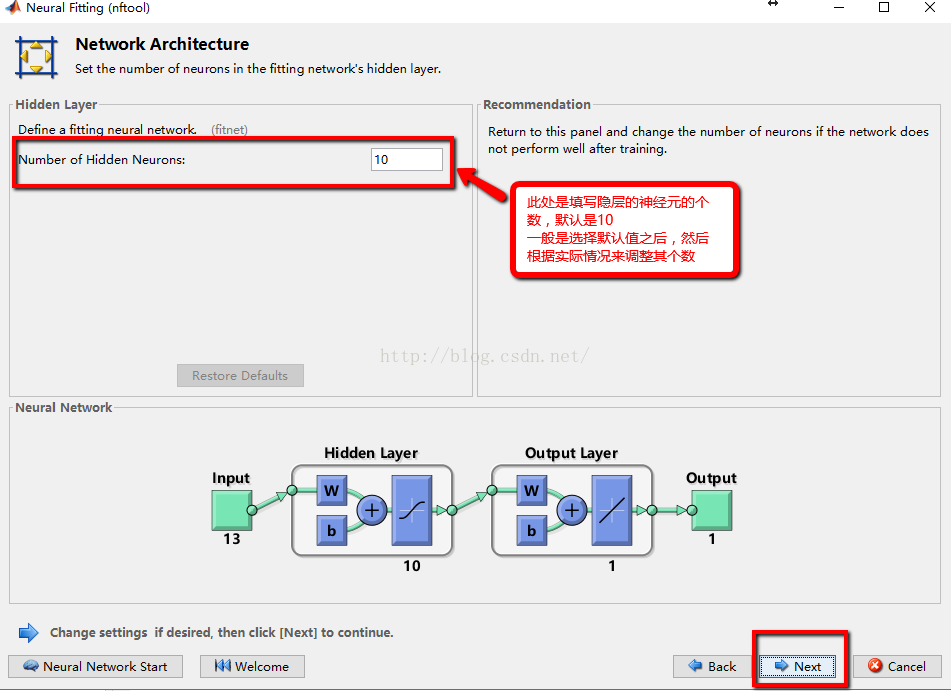
4:隐层神经元的确定
**
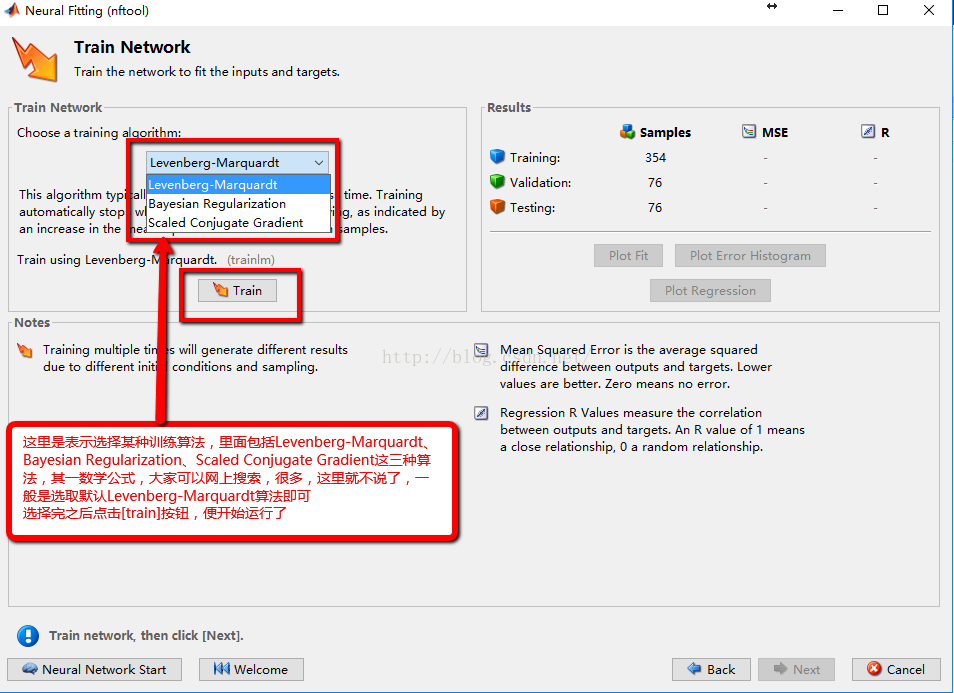
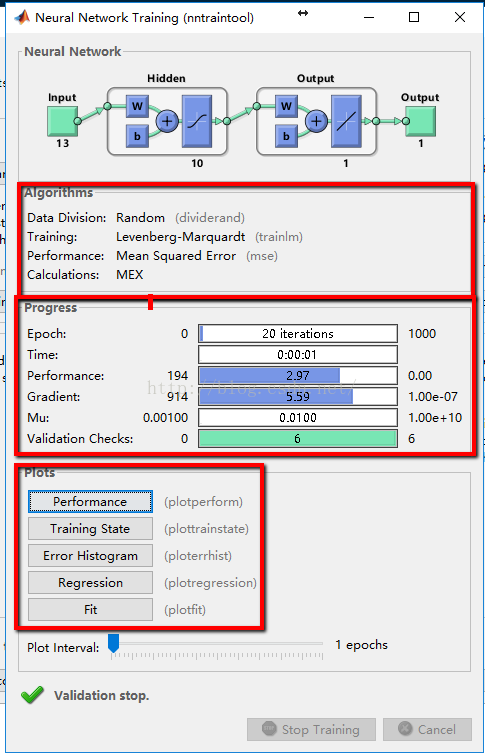
5:训练算法的选取,一般是选择默认即可,选择完成后点击按钮即可运行程序
**
**
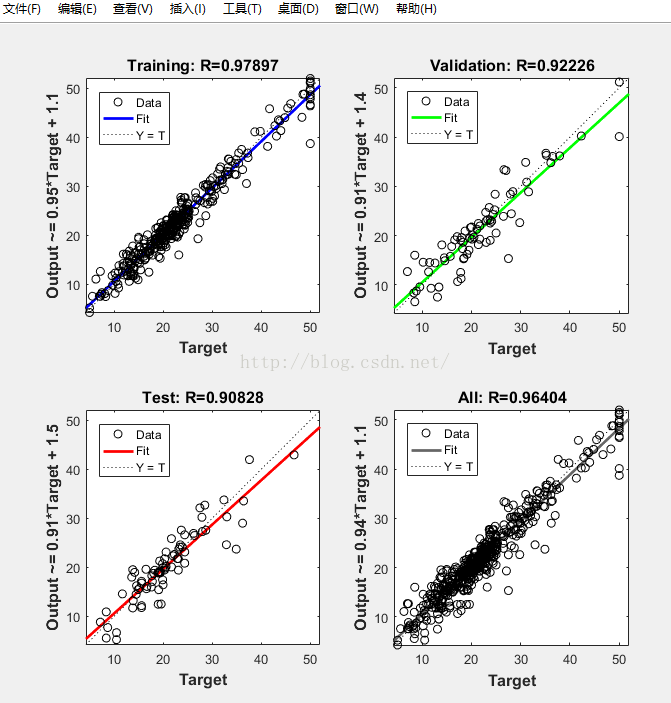
6:根据得到的结果,一般是MSE的值越小,R值越接近1,其训练的效果比较,并第二张图给出了神经网络的各参数的设置以及其最终的结果,其拟合图R越接近1,模型拟合的更好
**
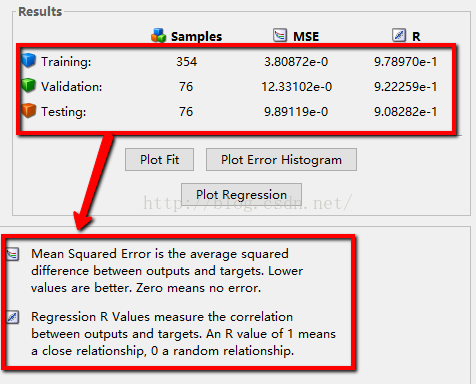
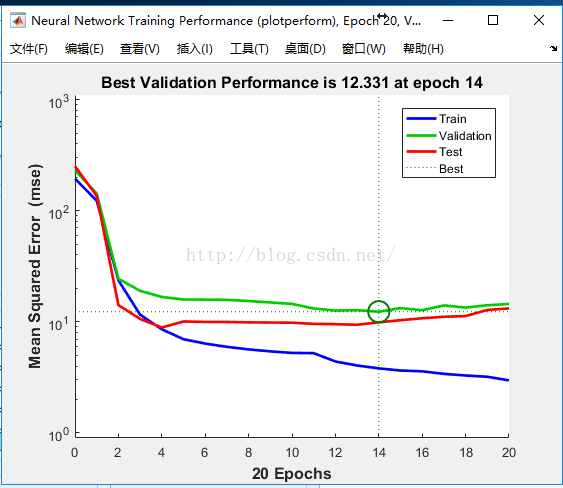
最终的结果图
**7:如果所得到的模型不能满足你的需求,则需重复上述的步骤直至能够得到你想要的精确度
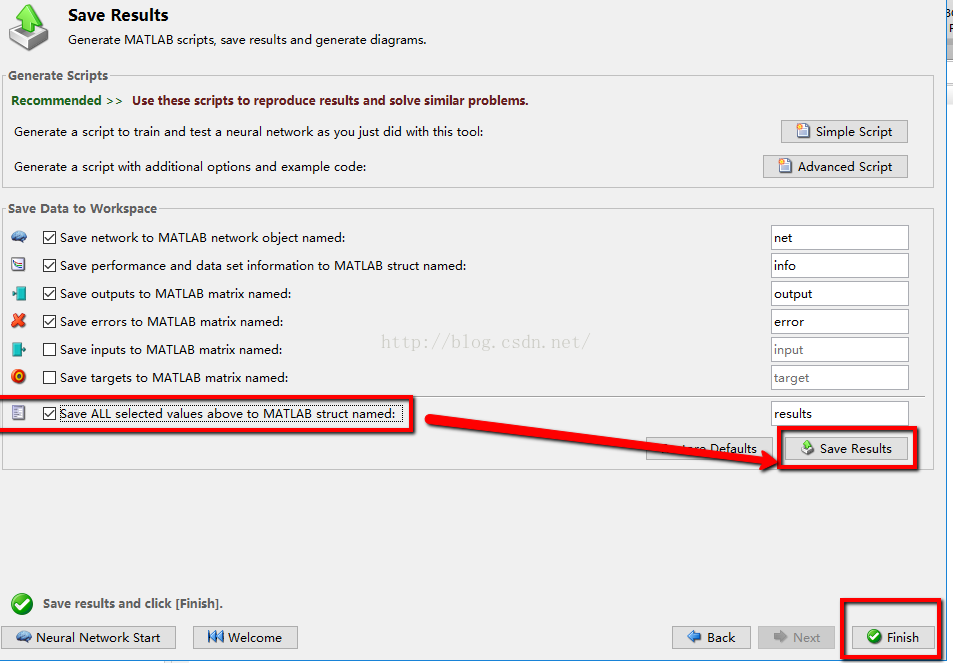
8:将最终的得到的各种数据以及其拟合值进行保存,然后查看,就可以得到所要的拟合值
例题:
公路运量主要包括公路客运量和公路货运量两个方面。根据研究,某地区的公路运量主要与该地区的人数、机动车数量和公路面积有关,下表给出了某地区20年的公路运量相关数据,表中人数和公路客运量的单位为万人,机动车数量的单位为万辆,公路面积的单位为万平方千米,公路货运量单位为万吨。
根据相关部门数据,该地区2010年和2011年的人数分别为73.39和75.55万人,机动车数量分别为3.9635和4.0975万辆,公路面积将分别为0.9880和1.0268万平方千米。请利用BP网络预测该地区2010年和2011年的公路客运量和公路货运量。
表 1 某地区20年公路运量数据
| 年份 | 人口数量/万人 | 机动车数量/万辆 | 公路面积/万平方千米 | 公路客运量/万人 | 公路货运量/万吨 |
|---|---|---|---|---|---|
| 1990 | 20.5500 | 0.6000 | 0.0900 | 5126 | 1237 |
| 1991 | 22.4400 | 0.7500 | 0.1100 | 6217 | 1379 |
| 1992 | 25.3700 | 0.8500 | 0.1100 | 7730 | 1385 |
| 1993 | 27.1300 | 0.9000 | 0.1400 | 9145 | 1399 |
| 1994 | 29.3500 | 1.0500 | 0.2000 | 10460 | 1663 |
| 1995 | 30.1000 | 1.3500 | 0.2300 | 11387 | 1714 |
| 1996 | 30.9600 | 1.4500 | 0.2300 | 12353 | 1834 |
| 1997 | 34.0600 | 1.6000 | 0.3200 | 15750 | 4322 |
| 1998 | 36.4200 | 1.7000 | 0.3200 | 18304 | 8132 |
| 1999 | 38.0900 | 1.8500 | 0.3400 | 19836 | 8936 |
| 2000 | 39.1300 | 2.1500 | 0.3600 | 21024 | 11099 |
| 2001 | 39.9900 | 2.2000 | 0.3600 | 19490 | 11203 |
| 2002 | 41.9300 | 2.2500 | 0.3800 | 20433 | 10524 |
| 2003 | 44.5900 | 2.3500 | 0.4900 | 22598 | 11115 |
| 2004 | 47.3000 | 2.5000 | 0.5600 | 25107 | 13320 |
| 2005 | 52.8900 | 2.6000 | 0.5900 | 33442 | 16762 |
| 2006 | 55.7300 | 2.7000 | 0.5900 | 36836 | 18673 |
| 2007 | 56.7600 | 2.8500 | 0.6700 | 40548 | 20724 |
| 2008 | 59.1700 | 2.9500 | 0.6900 | 42927 | 20803 |
| 2009 | 60.6300 | 3.1000 | 0.7900 | 43462 | 21804 |
根据个人理解来说,我认为用matlab解决这个问题有两种方法,第一种是利用MATLAB工具箱,另一种方法是根据神经网络编写相应的程序求解,根据自己的仿真结果来看,我觉得用工具箱来求解方法简单,但是算法收敛比较慢,需要选取比较合适的参数,这个得需要一遍一遍的实验,比如,增加节点数,减少节点数,修改学习速率等参数,还有均方误差等参数。而自己编写程序算法收敛一般比较快。但是需要深刻理解神经网络的原理,下面我利用两种方法来求解。
以下求解过程不论用那种方法都是利用的BP网络进行求解的。个人认为可以把问题分为6个部分:
1、 数据的输入;
2、 数据的预处理;
3、 网络训练;
4、 数据仿真;
5、 仿真数据和原始数据进行对比;
6、 对新数据进行预测;