框架
你说说数据绑定是什么?只记得v-model。
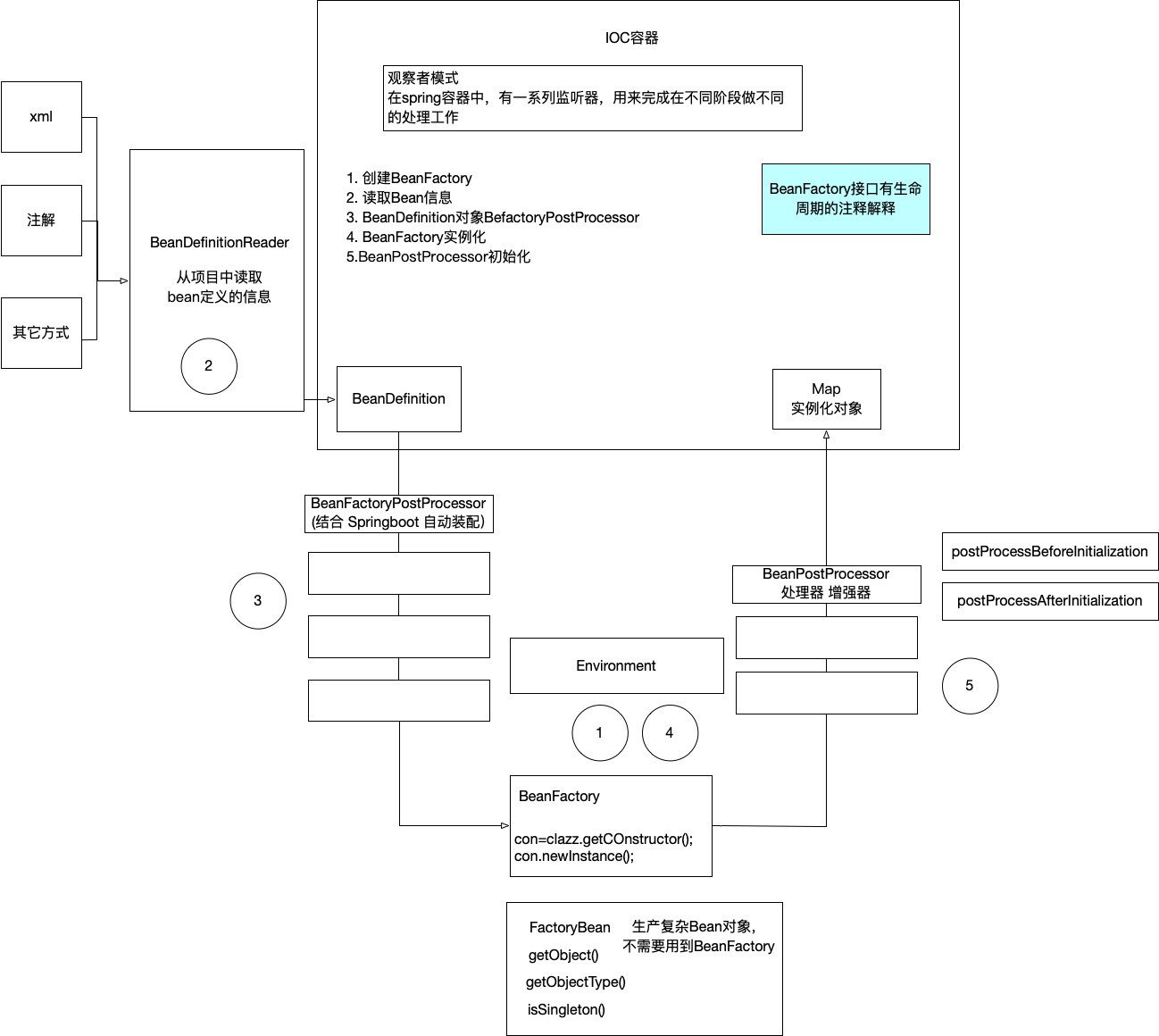
spring过程:

jdbc用过吗,说说原理


jdbc和mybatis区别
Mybatis的执行流程?
1.书写主配置文件mybatis-config.xml,配置环境****,连接Mysql数据库的,指定事务管理,Java的JDBC,控制事务的提交与回滚,dataSource是连接源配置,POOLED是JDBC连接对象的数据源连接池的实现,其中还要映射mapper文件
2.获取Sqlsession对象,将该对象提取到MybatisUtil工具类中,并将获取工厂对象放到静态代码中,然后提供一个公共的访问方法,这一步底层会调用defaultSqlsessionFactory中的方法,帮我关闭io流了
3.获取Sqlsession对象,这一步底层已经帮我们开启了事务
4.开启事务,如果事务开启失败,则底层会帮我们回滚事务
5.关闭资源1.sql语句与java代码分离(变成了配置文件usermapper.xml)
2.对结果集的映射,mybatis会帮我们将数据进行封装
3.mybatis底层用到了连接池,不用每次都从数据库获取以及关闭资源,节省资源
4.动态sql语句方便,如果是传统的JDBC要进行关键字查询时需要写多条代码
流程:
1. 首先写MybatisUtils.java,建造工厂获取sqlSessionFactory的实例,借此获得SqlSession的实例。它就代表了数据库。
2. 然后写配置文件mybatis-config.xml,它连接了数据库,是固定代码。
3. 写pojo里的实体类user,根据数据库的表写。
4. 写dao里的接口getUserList
5. 写实现dao的mapper文件,包含了sql语句。namespace绑定接口,里面的标签id绑定方法,返回类型对应于返回值,标签体专注于sql。(最终测试的时候直接调用方法就行了)
IoC理论
本质:inversion of control是一种设计思想,DI(依赖注入)是实现IoC的方法。所谓控制反转,就是获得依赖对象的方式反转了。它是一种通过描述(xml或者注解)并通过第三方去生产或获取特定对象的方式。
控制:谁来控制对象的创建,传统应用程序的对象是由程序本身控制创建的,使用spring后对象是由spring来创建的。
反转:程序本身不创建对象,变成被动接收对象。
依赖注入:用set实现注入。pojo没有set方法无法正确被spring接管。
隐式地自动装配分为byName和byType: id/class
@Autowired: https://www.cnblogs.com/fnlingnzb-learner/p/9723834.html
- 直接在属性上使用即可,也可以在set方法上使用。
- 使用Autowired我们甚至可以不用编写set方法,前提是你这个自动装配的属性在ioc(spring)容器中,且符合名字byname。
@Qualifier: 可以显式地通过它指定实现一个装配的值
@Resource:不通过spring:先通过名字查找,然后通过类型查找,两个都失败才报错
@Component+@Value:属性注入 下面为衍生注解
- dao:@Repository
- service:@Service
- controller: @Controller
@Scope("prototype"):作用域
注:
@Autowired注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。
@Resource注解和@Autowired一样,也可以标注在字段或属性的setter方法上,但它默认按名称装配。名称可以通过@Resource的name属性指定,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。
@Resources按名字,是JDK的,@Autowired按类型,是Spring的。
spring的创建初始化一个bean对象的流程
那么使用@Autowired的原理是什么?
其实在启动spring IoC时,容器自动装载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied、@Resource(是CommonAnnotationBeanPostProcessor后置处理器处理的)或@Inject时,就会在IoC容器自动查找需要的bean,并装配给该对象的属性
<bean class="org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor"/>

https://www.cnblogs.com/jimmyhe/p/13976202.html
spring是怎么解析json的,说说你用过的json解析器
jackson,fastjson
将 Java 对象转换为 JSON 格式:JSON.toJSONString(对象)
JSON 字符串转换为 Java 对象:JSON.parseObject(jsonObject, Person.class)
fastjson原理:序列化:通过asm 获取对象上的属性的get方法集合,然后通过调用相应的方法拼装出json字符串。
https://blog.csdn.net/weixin_33859665/article/details/91965701
SpringAOP实现原理
https://www.jianshu.com/p/4b02f4fa5cd4
aop能做什么:Authentication 权限 Caching 缓存 Lazy loading 懒加载 Transactions 事务
假如让你用aop来做事务应该注意哪些点
前端给你传一个请求过来服务器是怎么处理的,流程
mybatis是怎么完成ORM的?
mybatis
#{}是预编译处理,${}是字符串替换。
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 的 set 方法来赋值;
Mybatis 在处理${}时,就是把${}替换成变量的值。
项目
1.项目中pagehelper的原理是什么?
2.项目中使用aop是如何实现降低耦合和提高拓展性的?
Redis存储session的需要考虑问题:
https://www.cnblogs.com/xiongze520/p/10333233.html
考虑到session中数据类似map的结构,采用redis中hash存储session数据比较合适,如果使用单个value存储session数据,不加锁的情况下,就会存在session覆盖的问题,因此使用hash存储session,每次只保存本次变更session属性的数据,避免了锁处理,性能更好。
如果每改一个session的属性就触发存储,在变更较多session属性时会触发多次redis写操作,对性能也会有影响,我们是在每次请求处理完后,做一次session的写入,并且之写入变更过的属性。
如果本次没有做session的更改, 是不会做redis写入的,仅当没有变更的session超过一个时间阈值(不变更session刷新过期时间的阀值),就会触发session保存,以便session能够延长有效期。
登录功能,怎么维护登录状态
https://www.cnblogs.com/xlh-2014/p/8110685.html
将用户的用户名和加密之后的密码也通过Cookie的方式存放在客户端,当服务器上的Session销毁以后,使用Cookie里面存 放的用户名和加密之后的密码重新执行一次登录操作,重建Session,并更新客户端上Cookie中存放的的Session ID,而这个操作是发生在用户请求一个需要身份验证的页面资源的背后,对于用户来讲是透明的,于是就达到了“记住我的登录状态”的目的了。
https://blog.csdn.net/a754895/article/details/82632747
首先,用户登录成功后保存用户登陆的用户名到Cookie,同时设置Cookie的有效时间,在下次用户想免输入登陆时,直接判断Cookie是否含有该用户的用户名,如果有则直接登陆不需要输入,否则需要重新输入用户名和密码。
过滤器,监听器:
CharacterEncodingFilter implements Filter
登录功能: 1.LoginServlet extends HttpServlet,判断用户名密码 2. 进入主页的时候,要判断用户是否已经登录(判断usersession是不是null)(在过滤器中实现)
3.注销功能,删除session信息




JDBC:
forname反射加载驱动,DriverManager.getConnection获取数据库connection,用connection.createStatement()得到statement,执行SQL(查询)返回一个resultSet,关闭连接,释放资源
session机制是怎么实现的?有哪两种实现方式
session是以cookie或URL重写为基础的,默认使用cookie来实现
1. 通过cookie
Cookie是保存在客户端的一小段信息,服务器在响应请求时可以将一些数据以“键-值”对的形式通过响应信息保存在客户端。当浏览器再次访问相同的应用时,会将原先的Cookie通过请求信息带到服务器端。2. url重写
通过cookie可以很好地实现session,但是如果客户端由于某些原因(比如出于安全考虑)而禁用cookie,在这种情况之下,为了使session能够继续生效,可以采用url重写。url重写很简单,比如我要从1.jsp页面跳转到2.jsp,采用超链接的方式,可以用两种方式:一种如下所示:
<a href="2.jsp">2.jsp</a>
另一种是<a href="<%=response.encodeURL("2.jsp")%>">2.jsp</a>https://blog.csdn.net/shenquanxi/article/details/6690140
session cookie(json)
session共享的四种方法
(1)基于Cookie的Session共享
其原理是将全站用户的Session信息加密、序列化后以Cookie的方式统一种植在根域名下(如.host.com)。当浏览器访问该根域名下的所有二级域名站点时,将与域名相对应的所有Cookie内容的特性传递给它,从而实现用户的Cookie化Session在多服务间的共享访问
这个方案的优点是无需额外的服务器资源;缺点是由于受HTTP协议头信息长度的限制,仅能够存储小部分的用户信息,同时Cookie化的Session内容需要进行安全加解密(如采用DES、RSA等进行明文加解密,再由MD5、SHA-1等算法进行防伪认证),另外它也会占用一定的带宽资源,因为浏览器会在请求当前域名下的任何资源时将本地Cookie附加在http头中传递到服务器上
(2)基于数据库的Session共享
把session信息存储在数据库中,通常使用内存表,以提高Session操作的读写效率
这个方案的实用性比较强,应用较为普遍。缺点在于Session的并发读写能力取决于MySQL数据库的性能,同时需要我们自己来实现Session淘汰逻辑,以便定时从数据表中更新、删除Session记录,当并发过高时容易出现表锁,对数据库造成较大压力
(3)基于Memcache的Session共享
Memcache是一款基于Libevent的多路异步I/O技术的内存共享系统,简单的Key+Value数据存储模式使其代码逻辑小巧高效,因此在并发处理能力上占据了绝对优势
分页,下拉列表
1)导入分页的工具类:pagesupport文件
2)用户列表页面导入:userlist.jsp
从前端获取数据 获取用户列表,在dao得到一个userlist 获取用户的总数count(1) 控制首页和尾页,如果页面小于1,就显示第一页的东西 获取用户列表展示,get一页的用户对象,limit性能问题:偏移量会越来越大,效率极低。采用基于索引的子查询或者join。
对limit的优化,不是直接使用limit,而是首先获取到offset的id,然后直接使用limit size来获取数据。
另一种方法:拦截器 https://www.iteye.com/blog/elim-1851081#_Toc354330568
拦截所有以ByPage结尾的查询语句,并且利用获取到的分页相关参数统一在sql语句后面加上limit分页的相关语句,一劳永逸。不再需要在每个语句中单独去配置分页相关的参数了。
利用拦截器实现Mybatis分页的一个思路就是拦截StatementHandler接口的prepare方法,然后在拦截器方法中把Sql语句改成对应的分页查询Sql语句,之后再调用StatementHandler对象的prepare方法,即调用invocation.proceed()。
秒杀怎么设计
密码修改
update 清除session
拦截器的登录退出
实现 HandlerInterceptor 接口,配置拦截器配置文件


怎么实现验证码功能(session)
权限的区分:
拦截器,判断身份
或者重定向到不同页面。
shiro
邮箱注册
https://cloud.tencent.com/developer/article/1455749
主要业务逻辑实现过程:
- 用户填写完成相关信息后,点击注册,系统先将用户记录保存到数据库表中,其中用户状态为未激活。
- 系统发送一封邮件并通知用户去验证,邮件中包含了唯一标识用户的激活码。
- 用户登录邮箱并点击激活链接,系统接收到激活码。
- 系统根据激活码在数据库中找到相应用户,并将用户状态更改为已激活,最后通知用户激活成功。
ActivationServlet:用于接收激活信息。
RegisterServlet:插入用户信息到数据库中,并发送激活邮件。
文件上传
fileupload工具类两个jar包
commons-fileupload-1.2.1.jar和commons-io-1.4.jar# 文件上传三要素:
1. form表单的提交方式必须是POST方式
2. form表单中必须有字段为file类型的字段 <input type="file" name="upload" />
3. 表单的enctype属性值必须是:enctype="multipart/form-data" #
fileUpload上传文件的步骤:
1. 创建磁盘项工厂类,用于对上传文件进行配置 new DiskFileItemFactory()
2. 通过工厂类获得Servlet的上传文件的核心解析类 new ServletFileUpload(diskFileItemFactory)
3. 通过核心类解析request对象,获取所有字段的集合,集合中的内容是分割线分成的每个部分 fileUpload.parseRequest(req)
4. 遍历集合中每个部分 * 如果是普通项:直接获取属性名称和属性值 * 如果是文件项:通过输入输出流读取文件
mvc中:
在上下文中配置MultipartResolver
前端表单要求:为了能上传文件,必须将表单的method设置为POST,并将enctype设置为 multipart/form-data。只有在这样的情况下,浏览器才会把用户选择的文件以二进制数据发送给服务器。
设置相应的路径和编码格式,封装到bean里。
项目中遇到的困难
密码修改:
Dao层实现类用prestatement实现sql语句执行,service层用connection,
设计模式
手写单例问题
https://www.runoob.com/design-pattern/singleton-pattern.html
https://github.com/biezhi/java-bible/blob/master/designpatterns/singleton.md
饿汉式
public class Singleton { private static Singleton instance = new Singleton(); private Singleton (){} public static Singleton getInstance() { return instance; } }懒汉式dcl:双重检查锁(double checked locking)先判断对象是否已经被初始化,再决定要不要加锁。
为什么volatile?因为new singleton()不是一个原子操作
* 1. 分配内存空间
* 2、执行构造方法,初始化对象
* 3、把这个对象指向这个空间
为什么在同步块内还要再检验一次?因为可能会有多个线程一起进入同步块外的 if,如果在同步块内不进行二次检验的话就会生成多个实例了。
public class Singleton { private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }枚举
public enum EnumSingle { INSTANCE; public EnumSingle getInstance(){ return INSTANCE; } }
生产者消费者(虚假唤醒)
虚假唤醒:if 改为 while 判断
降低耦合
支持并发 生产者把制造出来的数据往缓冲区一丢,就可以再去生产下一个数据。基本上不用依赖消费者的处理速度。
https://blog.csdn.net/nrsc272420199/article/details/106038372
static class PrintClass { //共用一把锁 private Lock lock = new ReentrantLock(); //三个不同的条件 private Condition c1 = lock.newCondition(); private Condition c2 = lock.newCondition(); private Condition c3 = lock.newCondition(); private int flag = 1; //打印A时使用标志1,B->2, C->3 public void printA() { lock.lock(); try { //如果标识不为1,则利用条件c1将次线程阻塞 while (flag != 1) { c1.await(); } //走到这里说明标识为1,打印A,并将标识为改为2,且将利用c2条件阻塞的线程唤醒 flag = 2; log.info("A"); c2.signal(); } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); } } ... public static void main(String[] args) throws InterruptedException { PrintClass printClass = new PrintClass(); new Thread(() -> { for (int i = 1; i <= 5; i++) { printClass.printA(); } }, "线程A").start(); ...

代理模式
https://github.com/biezhi/java-bible/blob/master/designpatterns/proxy.md
leetcode
链表反转:先记录head后面节点为b,再连接上head前面的a节点,然后刷新a为这个head,最后重新定义head为下一个节点。
两个单链表是否交叉及是否有环
最大的子序列和
合并有序链表 (经典高频题了) 追问:如果链表降序还是增序的还未定,要求按照原本链表的增降序来合并 。追问2:链表有重复节点,怎么合并,要求去重
Leetcode138. 复制带随机指针的链表
求二叉树所有的左叶子节点之和(Leetcode 404)
两个字符串s1,s2,求出s1中包含s2的最短子串(Leetcode 76)
LRU
树从根到叶子节点的遍历