我们先考虑一个任务:从照片中识别出某位友人。对大多数人来说,就算照片光线不足,或是友人刚理过发,或是换了新衣服,要认出他来也是轻而易举的事。但若是要在计算机上编程来解决这个问题,应当如何开始呢?恐怕谁都会毫无头绪吧。而这类问题正是机器学习所能够解决的。
传统上来讲,计算机编程指在结构化的数据上执行明确的程序规则。软件开发人员动手编写程序,告诉计算机如何对数据执行一组指令,并输出预期的结果,如图1-1所示。这个过程与税务申报有些类似:税单中的每个框都有明确的定义,并且有详尽的规则指明如何进行计算。在有的地方,这种计算规则可能相当复杂。人们在填写税单时非常容易犯错,而这正是计算机程序最擅长的任务。
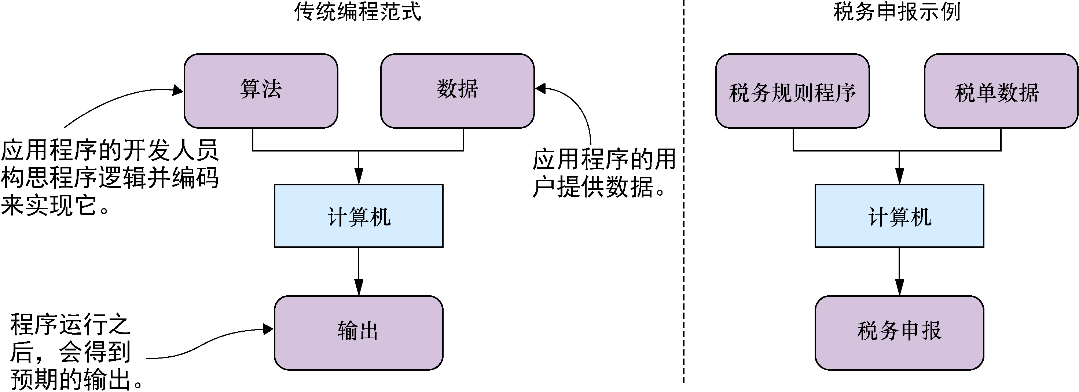
图1-1 软件开发人员所熟悉的标准编程范式。开发人员构思算法并实现代码;用户提供数据
与传统的编程范式不同,机器学习不用直接实现算法,而是从样本数据推断出程序或算法。因此,在应用机器学习技术时,我们仍然向计算机提供数据,但不再提供指令,也不再等待预期的输出,而是向它提供我们所希望的输出,让机器自己找到对应的算法。
要构建一个计算机程序来识别照片中的友人,可以先获取许多他的照片,然后用一套算法来分析这个照片集合,并生成一个能够匹配照片的函数。如果这一步做得足够好,生成的函数甚至可以用来检验没见过的新照片。当然,程序其实并不知道它的目标是什么,它唯一要做的是判断新图片与提供给它的原始图片是否相似。
在这个场景中,提供给机器用来训练的图片被称为训练数据(training data),而图片中人物的名称则被称为标签(label)。在为一个目标训练(train)出算法之后,可以用这个算法来预测(predict)新数据上的标签,以进行测试。图1-2展示了一个示例,并描述了机器学习范式。
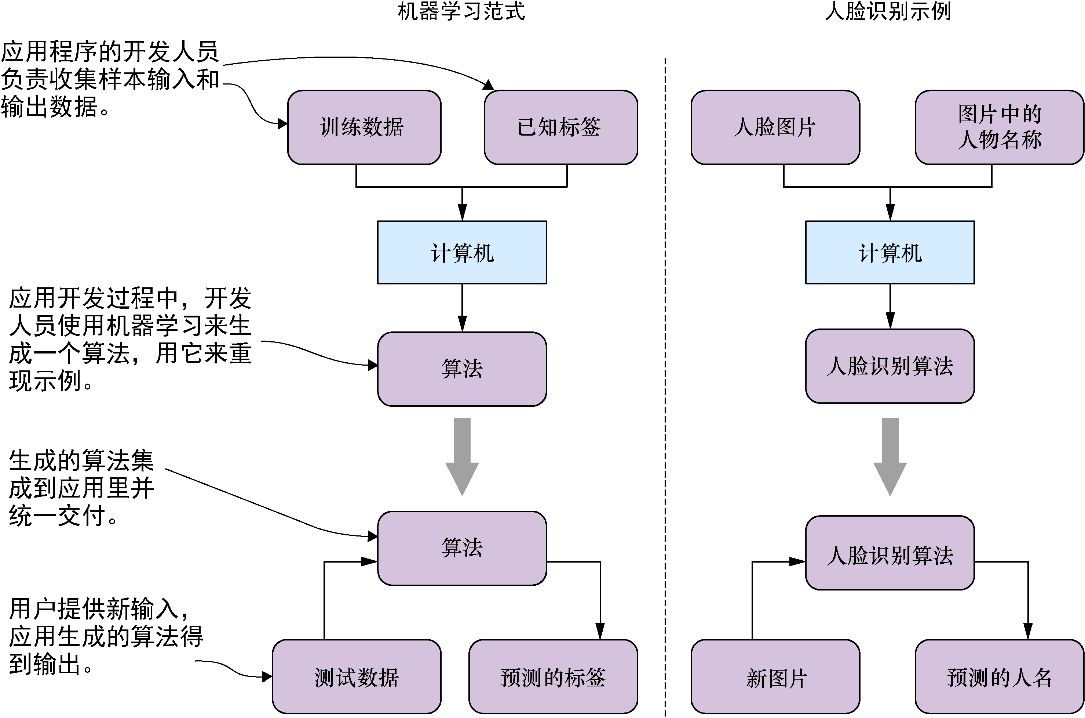
图1-2 机器学习范式:在开发过程中,从数据集生成一个算法,然后将它集成到最终的应用中
机器学习适用于规则模糊的场景。它擅长解决类似于“等我看到了才知道它是什么”的问题。我们不用直接编写函数,而是提供数据来指导函数应该做什么,然后科学地生成与数据相匹配的函数。
在实践中,通常需要把机器学习和传统编程结合起来,才能构建出真正有用的应用。例如,对于前面提到的人脸识别应用,我们必须告诉计算机如何查找、加载和转换示例图像,然后才能对图像数据应用机器学习算法。除此之外,还可能需要手写一些规则,例如如何区分头部特写、日落和咖啡拉花。把传统编程技术和先进的机器学习算法结合起来,往往会比只用其中一个要好得多。
1 机器学习与AI的关系
从广义上讲,AI是指任何让计算机模仿人类行为的技术。AI技术包括很多不同的范畴,例如以下几种:
- 逻辑生产系统,应用形式逻辑来分析语句;
- 专家系统,软件开发人员尝试将人类知识直接编码到软件中;
- 模糊逻辑,定义算法来帮助计算机处理不精确的语句。
这几个技术都是基于规则的,有时我们称它们经典AI或老式AI(Good Old-Fashioned AI,GOFAI)。
机器学习只是人工智能领域的众多分支领域之一,但如今它可以说是最成功的一个。尤其是深度学习,作为机器学习的一个子领域,它成功地引领了近年来AI世界激动人心的几次突破,甚至解决了困扰研究界数十年的问题。在经典AI中,研究者分析人类行为,尝试找到相应的规则,并编写成代码。而机器学习和深度学习解决问题的方式则完全相反:在机器学习里,我们先收集人类行为的样例,再用数学与统计学技术从数据中抽取规则。
深度学习的应用简直无处不在,以至于研究界常常混用AI和深度学习这两个词语。在本书中,为了避免混淆,我们用AI这个词来表示用计算机模仿人类行为的一般问题,用机器学习或深度学习来特指从样例中抽取算法的数学技术。
2 机器学习能做什么,不能做什么
机器学习是一种专门的技术。它不能用来更新数据库记录,也不能用来呈现用户界面。在下面几种情形中,应当优先选择传统编程来解决问题。
- 用传统算法就能够直接解决问题。如果可以直接编写代码来解决问题,那么与机器学习相比,传统算法的理解、维护、测试和调试将更加容易。
- 期望程序准确无误。所有复杂的软件都会出错。在传统的软件工程中,我们可以系统地识别和修复bug,然而在机器学习中则并不总是如此。我们可以想办法改进系统,但若是过分专注于个别错误,往往会导致整个系统变得更糟。
- 简单的启发式规则已经够好了。如果用几行代码就能够实现一个足够好的规则,那么最好安于现状。这种简单的启发式规则如果实现得足够清晰,就会非常易于理解和维护。而机器学习生成的函数却仿佛雾里看花,如果要修改更新,还需要再单独执行一遍训练过程。相反地,如果需要维护一整套复杂的规则,那么用机器学习代替传统编程就可能是个很好的选择了。
实际上,有些问题用传统编程能够解决,但如果对问题稍作变化,就可能连机器学习也难以解决了。这两类问题的区别往往非常细微。例如,前面讨论的图像中人脸识别的问题与给人脸标记名称的问题。又如,检测文本所使用的语言并不难解决,但如果想将文本翻译成其他指定的语言,其难度就会有天壤之别。
当问题的复杂度非常高时,人们往往还是倾向于使用传统编程解决,即使机器学习可能更有用。在面对信息密集、错综复杂的场景时,例如在宏观经济学、股票市场预测和政治领域中,人们通常倾向于寻求经验法则和规则表述。但实际上机器学习的发现往往能够提供灵感,从而大大帮助这些流程管理人员或专家们的直觉判断。真实世界的数据往往比预想中更有结构。在很多领域里,我们才刚刚开始感受到自动化与增强机器学习发展所带来的好处。
本文摘自《深度学习与围棋》

本书通过教读者构建一个围棋机器人来介绍深度学习技术。随着阅读的深入,读者可以通过Python深度学习库Keras采用更复杂的训练方法和策略。读者可以欣赏自己的机器人掌握围棋技艺,并找出将学到的深度学习技术应用到其他广泛的场景中的方法。
本书主要内容
● 构建一个游戏 AI,并教会它自我改进。
● 用深度学习增强经典游戏 AI 系统。
● 实现深度学习的神经网络。
要阅读本书,读者只需具备基本的Python技巧和高中水平的数学知识,而不需要任何深度学习经验。