先来了解一个概念:Innodb_page_size,这是Innodb在存取数据时,最小的基本单位,可以理解为"一页",默认大小为16KB,Innodb每次向磁盘存取数据时,最小存取一页数据,即16KB数据,这样做的好处是:可以有效减少IO操作,提高性能;
先来看一眼 “页” 的结构: 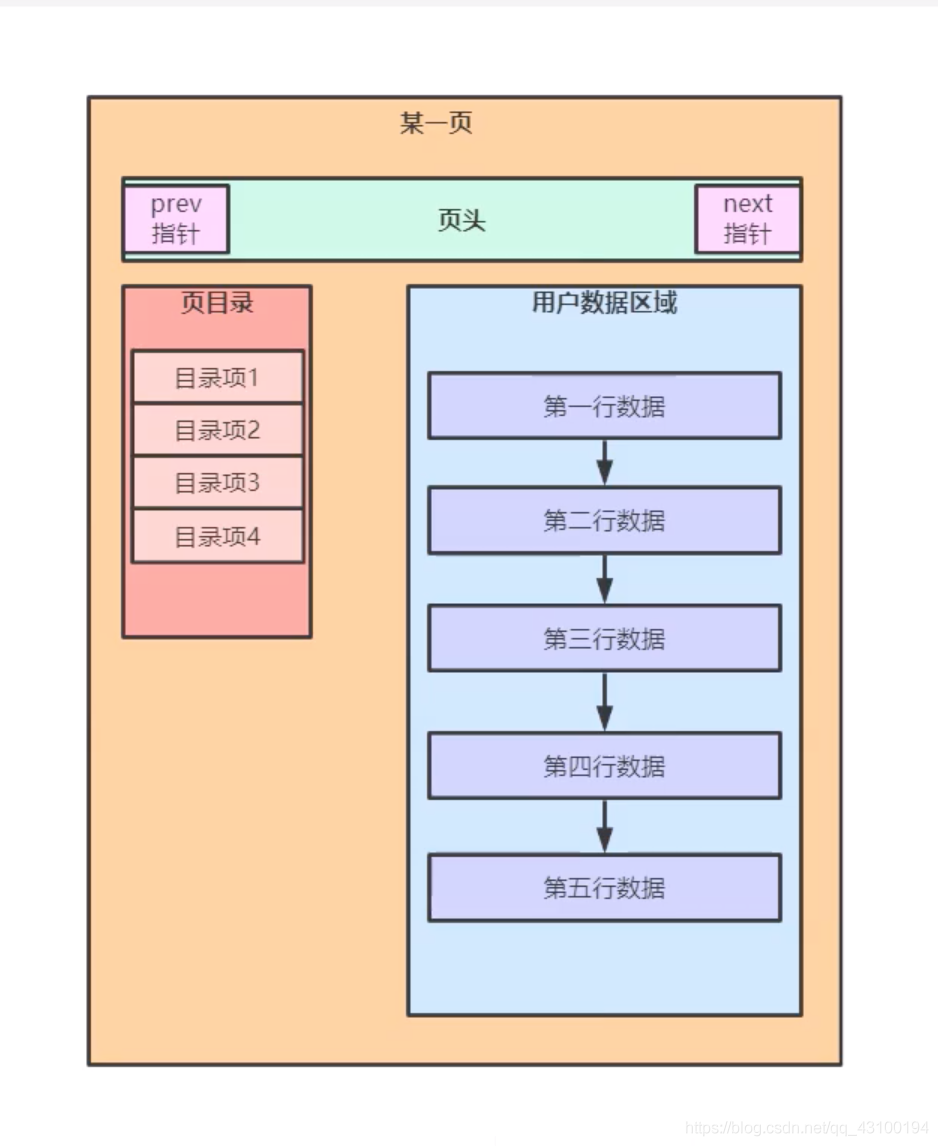
看上去可能有点儿蒙,没关系,暂时只需要知道有这么个东西,由图可知,“页”中包含“页目录”和“用户数据区域”;
另外本人整理了20年面试题大全,包含spring、并发、数据库、Redis、分布式、dubbo、JVM、微服务等方面总结,下图是部分截图,需要的话点这里点这里,暗号CSDN。
先来举个例子,建立一张表,如下图:  此时,这张表的 “页” 为:
此时,这张表的 “页” 为: 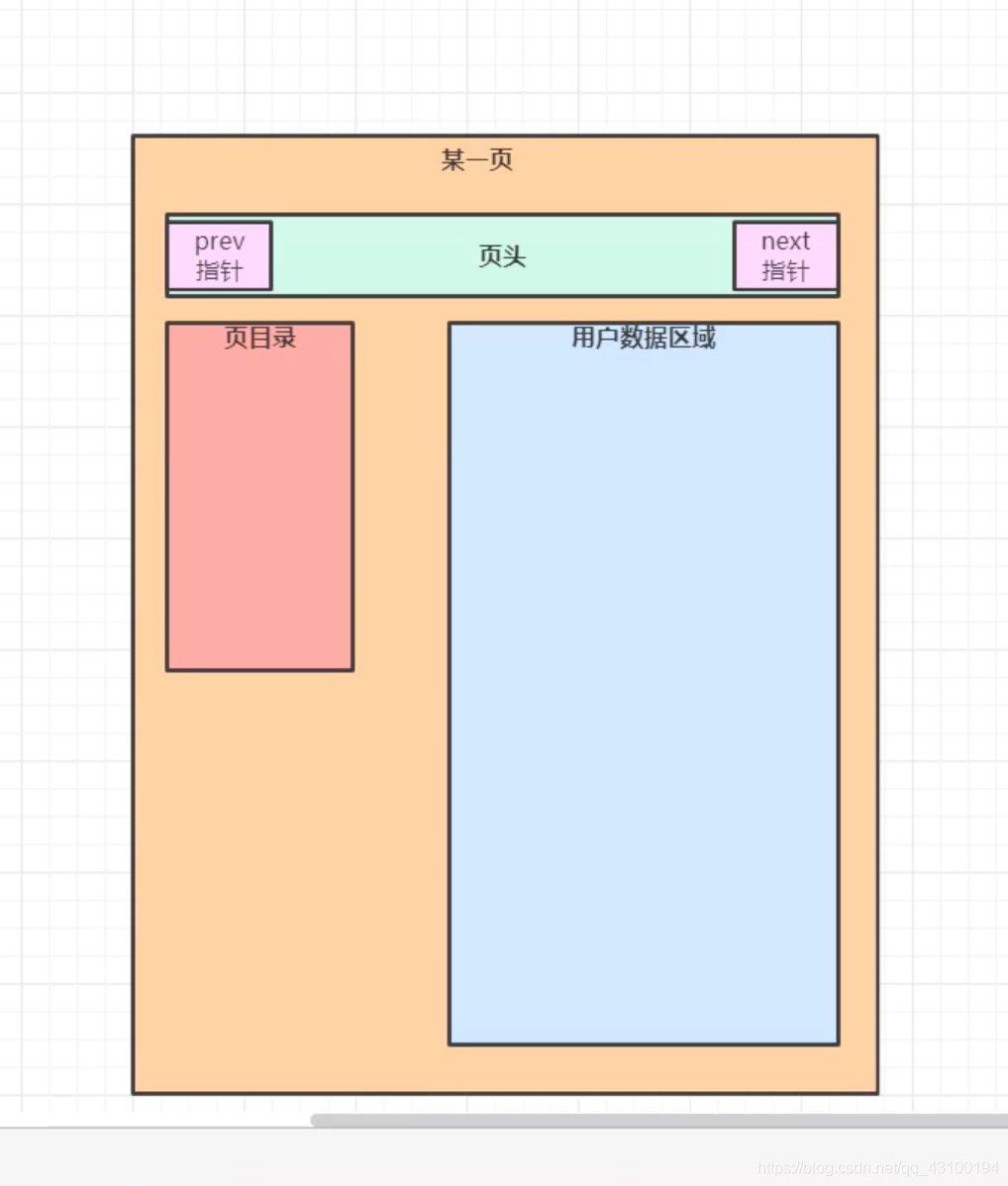 可以看到“页目录”和“用户数据区域”是没任何数据的; 现在往表里随便插入几条数据,由于MySql对于新插入的数据,会默认
可以看到“页目录”和“用户数据区域”是没任何数据的; 现在往表里随便插入几条数据,由于MySql对于新插入的数据,会默认按照主键进行排序,用来提高查询性能,所以此时,这张表的 “页” 为:
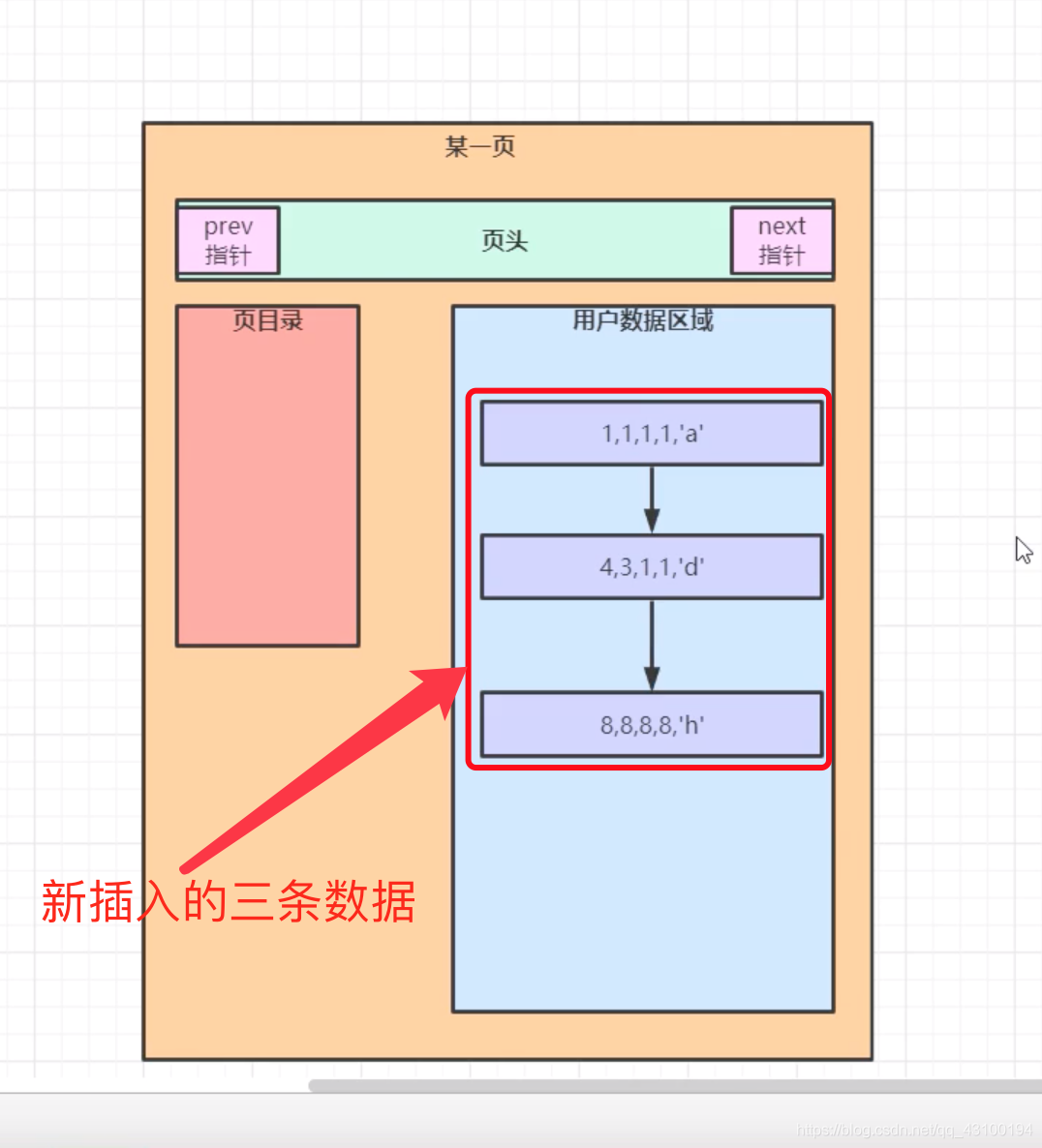 此时新插入的数据,会被保存到“用户数据区域”; 接着执行一条查询语句:
此时新插入的数据,会被保存到“用户数据区域”; 接着执行一条查询语句: select * from t1 where a = 3; 会扫描整个 “用户数据区域”,性能显然不是最优的;
接下来解释一下图中的“页目录”,“页目录”可以理解为书本中的目录,“用户数据区域”可以理解为书本中的正文;
假设此时一共插入了四条数据,可以把这四条数据按照主键的顺序,分成两组: 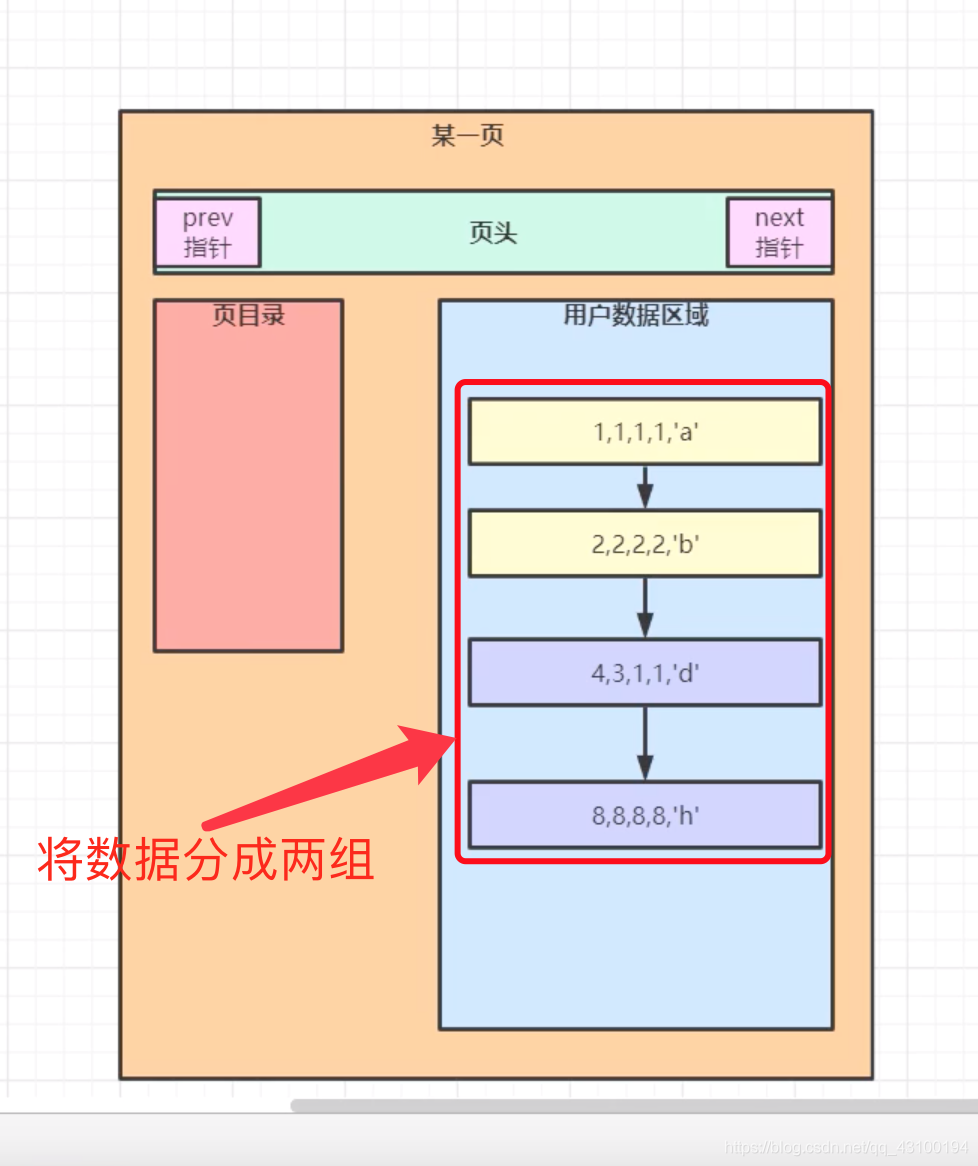 此时,“页目录”里记录的,是每组数据里,最小主键值 和 指向当前组的指针,如下图:
此时,“页目录”里记录的,是每组数据里,最小主键值 和 指向当前组的指针,如下图: 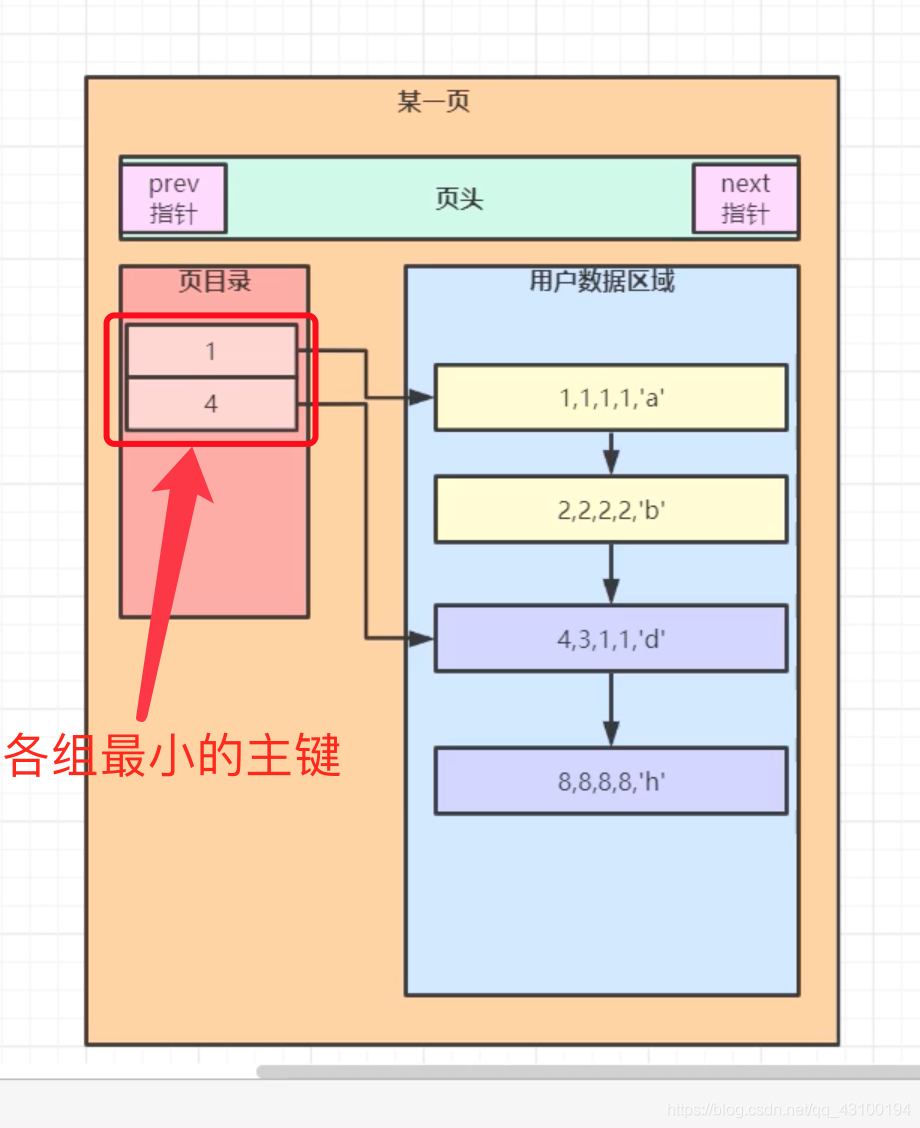 接着执行一条查询语句:
接着执行一条查询语句: select * from t1 where a = 3; 此时可以通过“页目录”,判断 a=3 只可能在第一组,此时,只需要遍历第一组中每条数据即可,这样查询性能就会提升;
按照上面了解的,假设现在表中数据很多,即很多“页”数据,如下图: 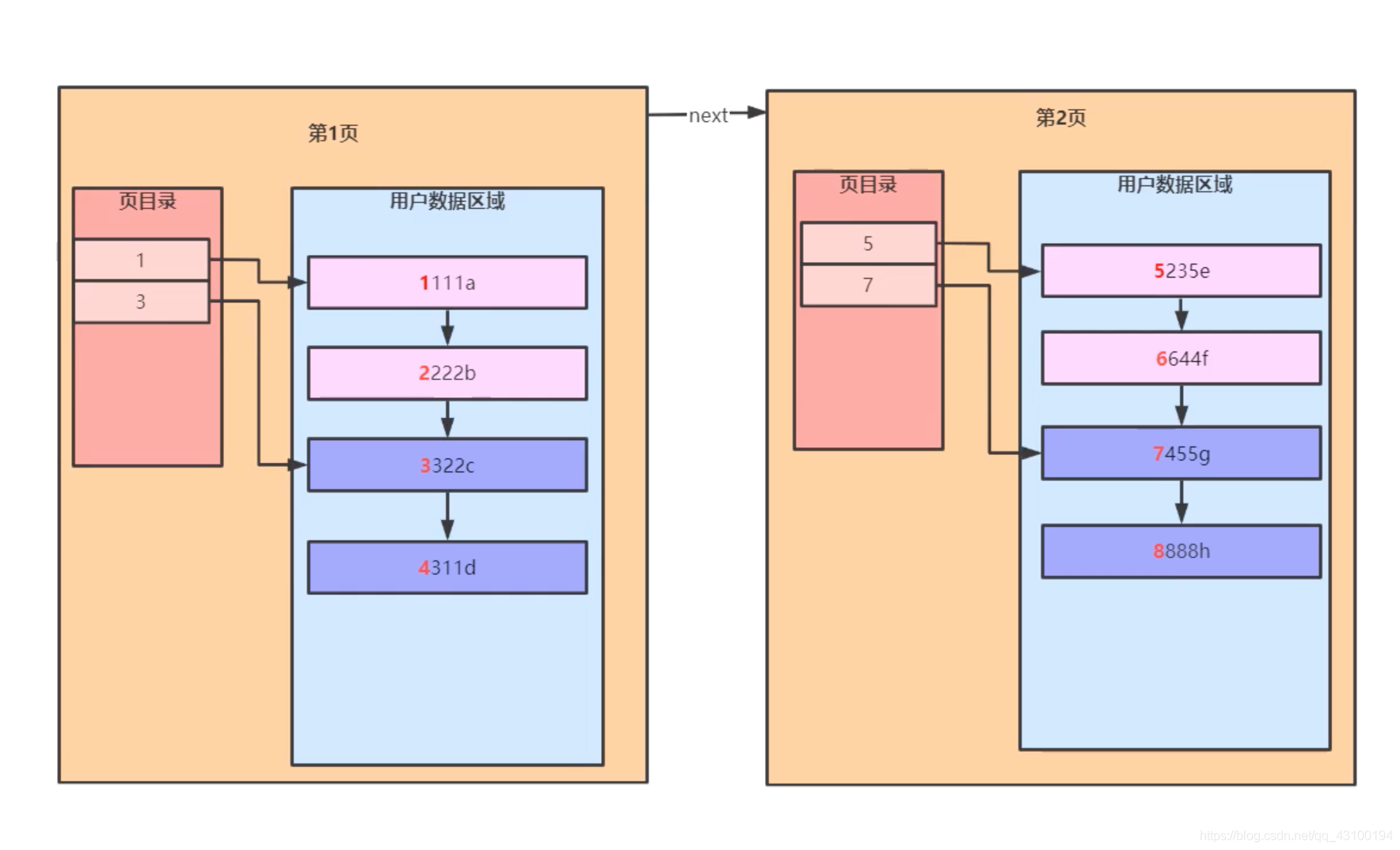 接着执行一条查询语句:
接着执行一条查询语句: select * from t1 where a = 3; 会挨个遍历每个“页”中的“页目录”,直到匹配到数据为止,性能显然不是最优的;
此时,可以参照前面介绍的“页目录”的思想,再来重新开辟一个新的“页”,专门用来存储每一“页”内,“页目录”中最小的值 和 指向这一页的指针,如下图: 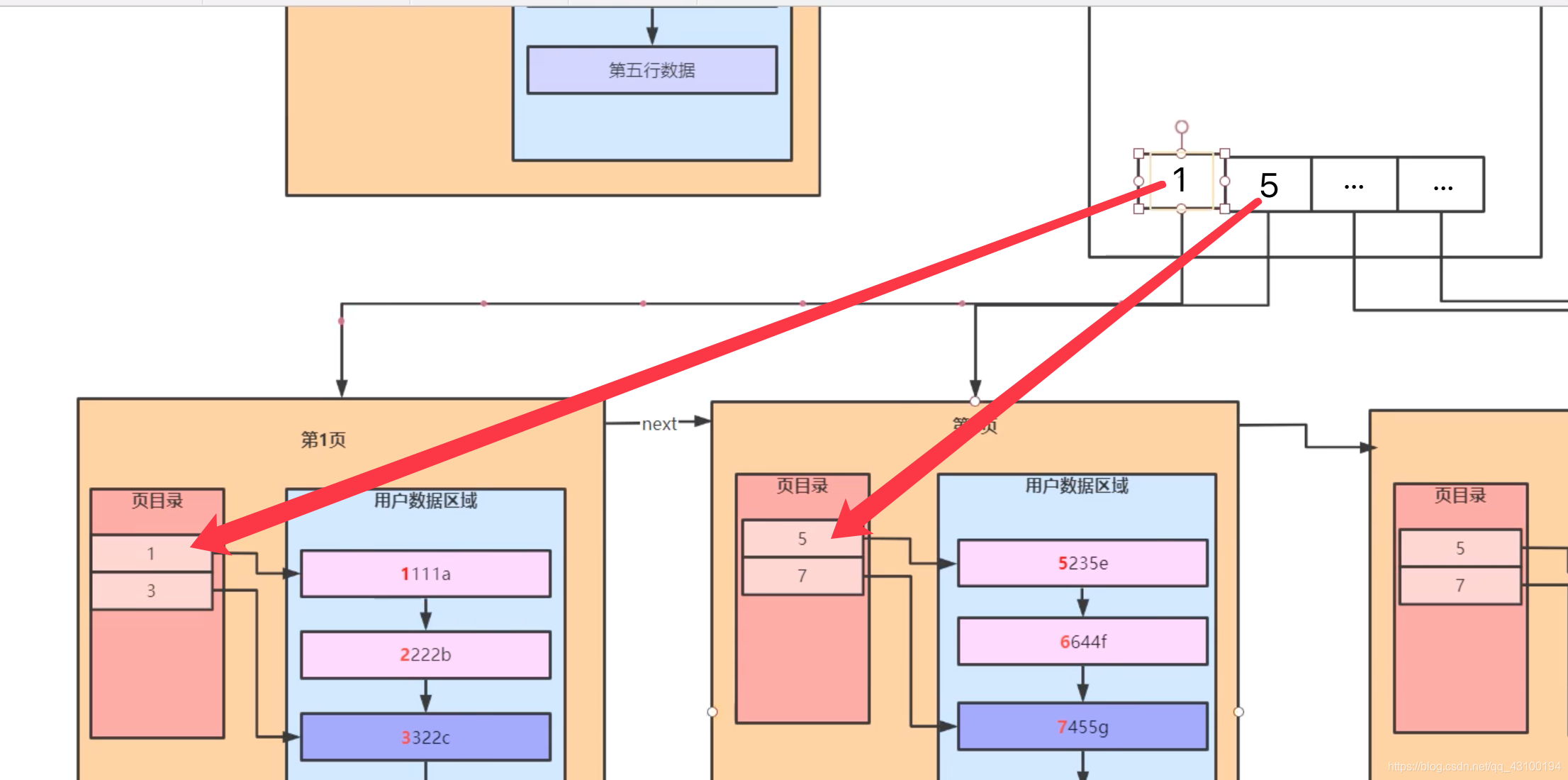 接着执行一条查询语句:
接着执行一条查询语句: select * from t1 where a = 3; 可以直接确定 a=3 只可能在第一页内,到此,性能又有所提升;
如果把刚刚上面的图画规范一点,就变成了下面这张图: 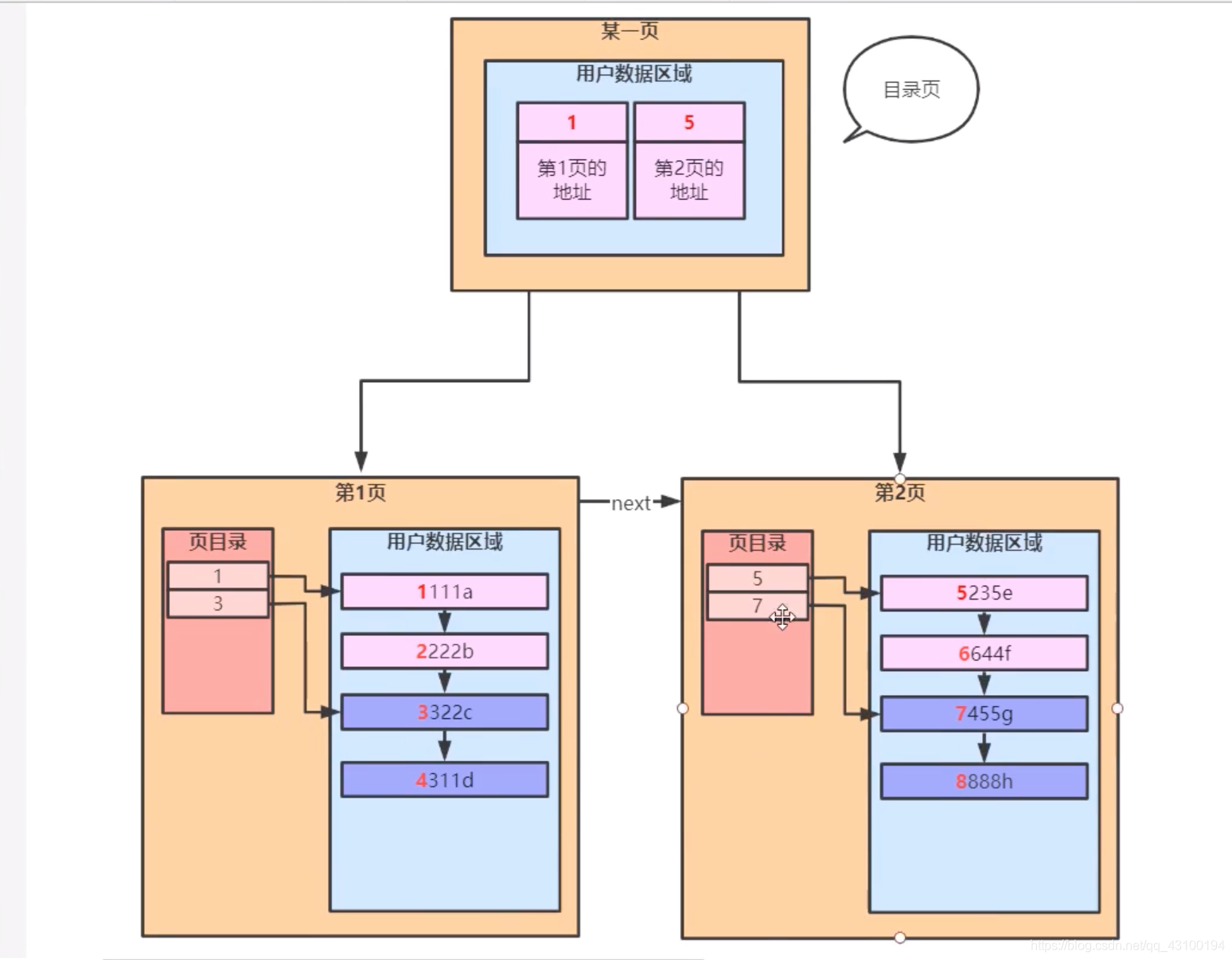 由上图可见,下面那两页,是专门存放数据的,顶部那一页,是专门存放下面每个页地址的;
由上图可见,下面那两页,是专门存放数据的,顶部那一页,是专门存放下面每个页地址的;
到这里,细心的同学可能会发现,这不就是一棵B+Tree嘛?如果没看出来也没关系,接着看下面这张图: 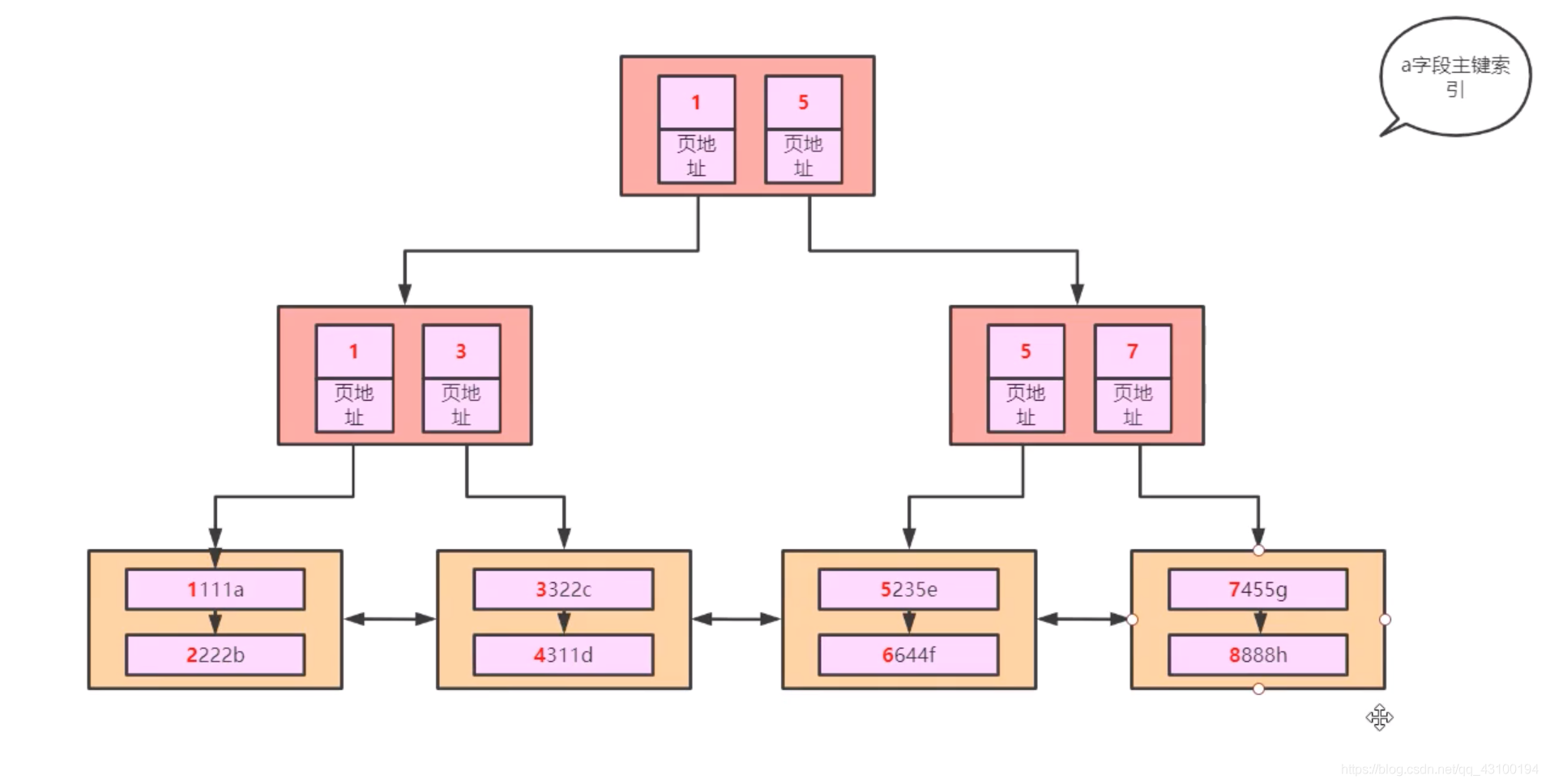 把每一页中的“页目录”提出来,放在中间的位置,这就是InnoDB中B+Tree数据结构;
把每一页中的“页目录”提出来,放在中间的位置,这就是InnoDB中B+Tree数据结构;
由图可知,B+Tree 每个节点左边的数据都比自己小,右边的数据都比自己大,即天生有序,另外,每个节点里面,可以有多个元素,非叶子节点,冗余了一部分主键数据;
接下来结合上图,解释一些名词,上面这棵树,按照主键进行排序,称为主键索引,叶子节点存储的是整张表的具体数据,又叫聚集索引,即索引和表中数据同时在一起;
再观察,查询某条数据时,只有两条路径,要么是从左往右依次遍历每个叶子节点,要么是从上往下通过页目录最终匹配到数据。
如何判断查询数据时,有没有走索引呢? 如果查询是从左往右依次遍历叶子节点,就是全表扫描,如果查询是从上往下,就是走索引,通过explain执行sql时可查看是否走了索引;
再来解释下每个叶子节点之间的双向指针,其实是专门用来做范围查找,举个例子,执行一条查询语句: select * from t1 where a > 3; 由于a是主键,InnoDB会先从主键索引中从上到下找到a=3的叶子节点,由于叶子是有序的,并且相互之间有指针指向前后节点,如果此时a > 3,那就从a=3这个节点开始,往后的数据全部匹配,如果查的是a < 3,那就从a=3这个节点开始,往前的数据全部匹配;
现在建一个联合索引: create index idx on t1(b,c,d); InnoDB会按照b,c,d三个字段排序,建立一棵B+Tree,如下图: 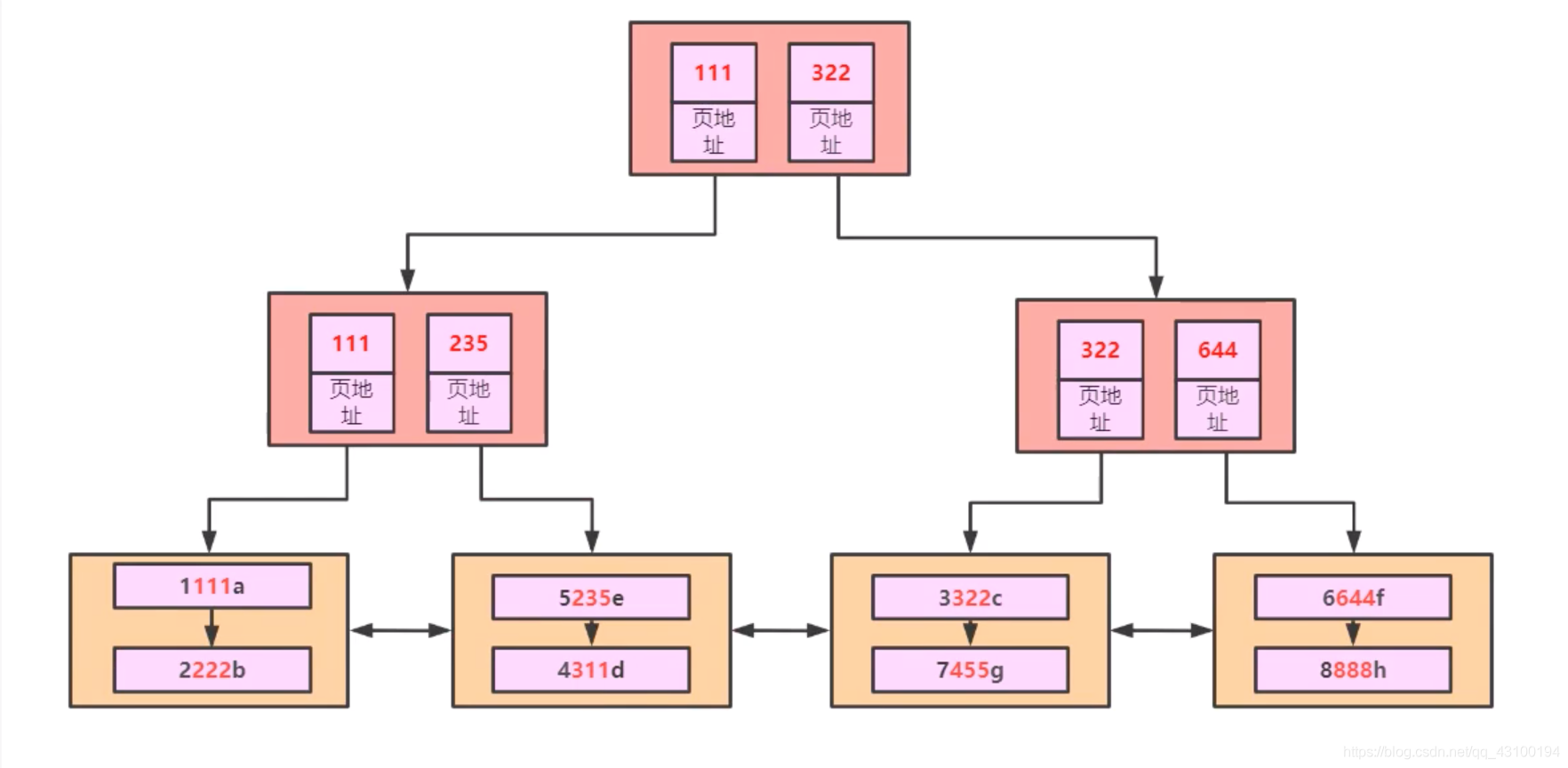 解释一下,叶子节点存储了按照
解释一下,叶子节点存储了按照b,c,d排好序后的全表数据,非叶子节点只存储了b,c,d字段的值; 细心的同学可能发现,新创建的索引又把全表数据复制保存了一份,太浪费资源了,这里的叶子节点数据其实和主键索引中叶子节点数据是一样的,只是顺序不同而已,所以需要把叶子节点冗余的数据去掉,只保存b,c,d字段的值,如下图: 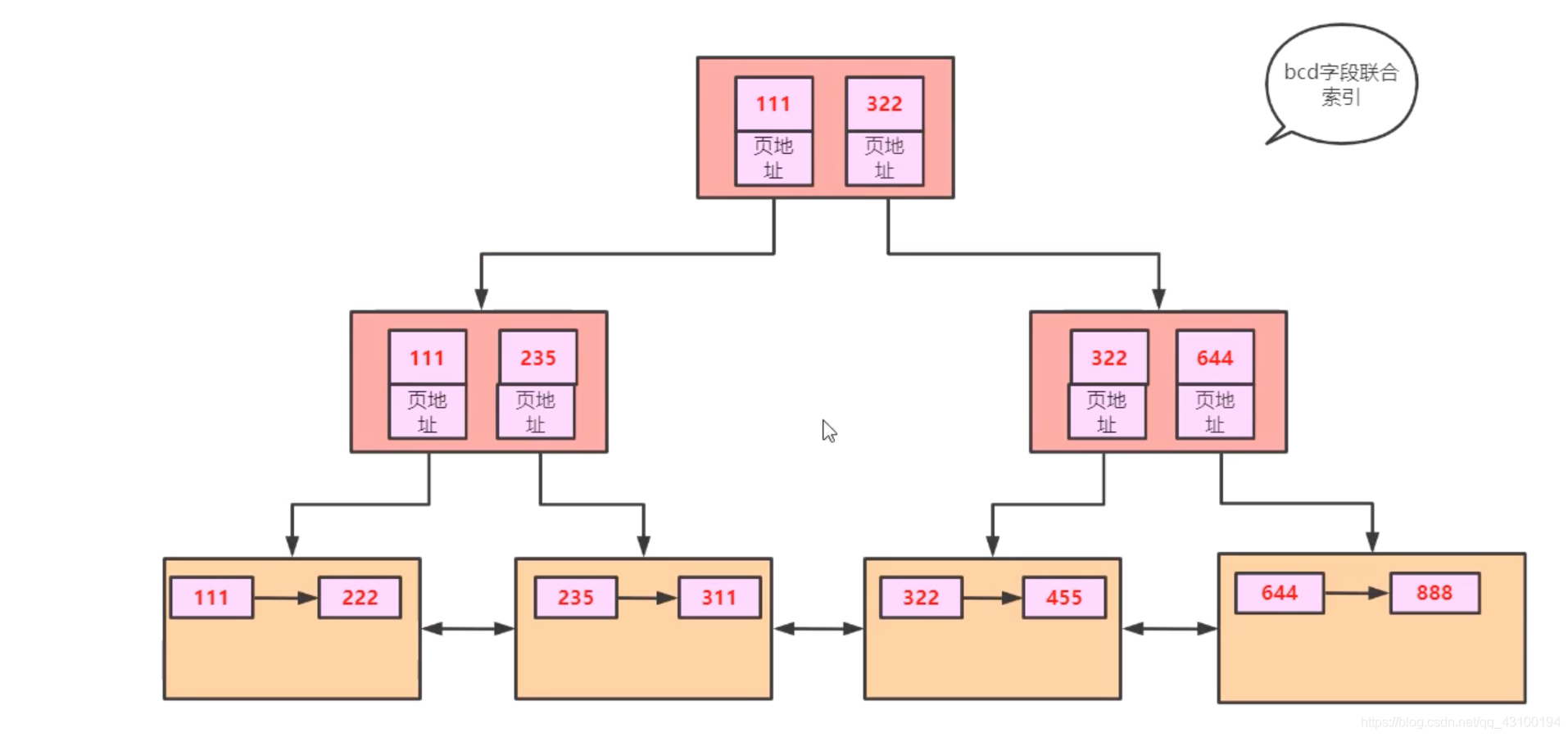 但是这样会有一个缺点,如果查询
但是这样会有一个缺点,如果查询b,c,d之外的字段,该如何查呢? 此时可以在叶子节点,记录每条数据主键的值,如下图: 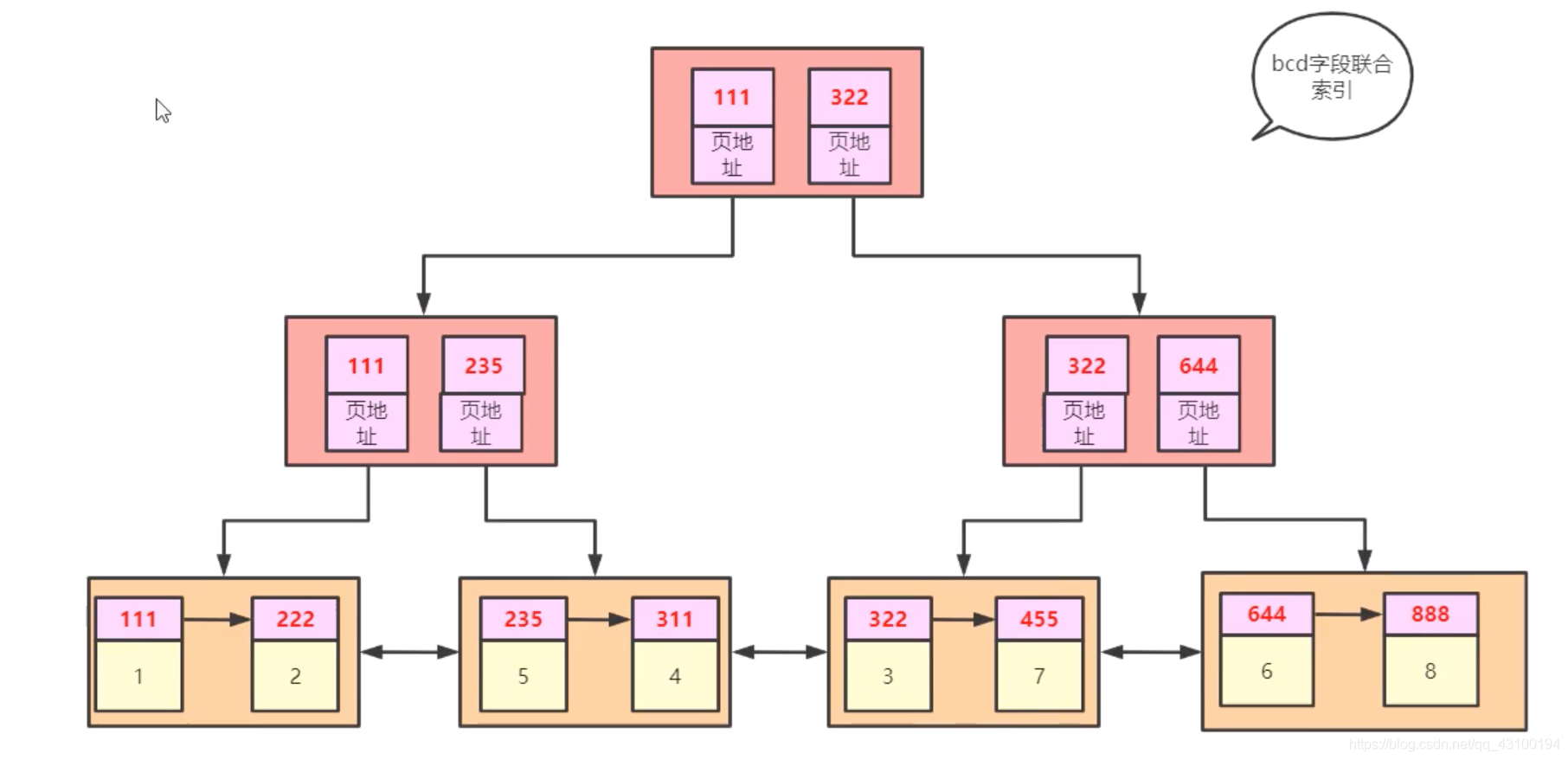 由图可知,根据
由图可知,根据b,c,d找到主键后,拿着主键到主键索引上去找,最终找到具体数据,这个过程就叫做:回表; 此时这个索引没有和完整数据关联在一起,只关联了主键值,又叫非聚集索引;
回表过程如下: 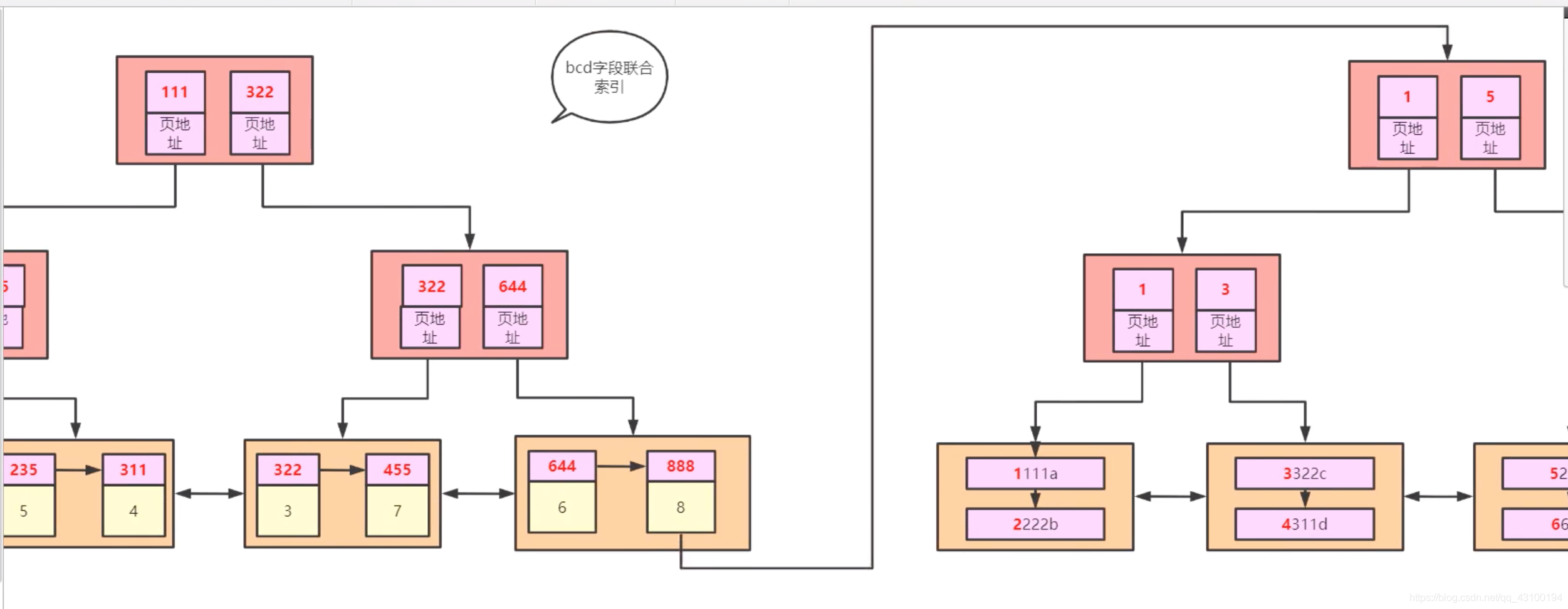 左边是非主键索引,右边是主键索引;
左边是非主键索引,右边是主键索引;
最左匹配原则:此时有联合索引b,c,d,如果想使用这个联合索引,查询顺序必须按照b,c,d顺序来,即:b、bc、bcd,如果不连续时,比如:bd,只用到了b列的索引,c列和d列都没有用到。
select * from t1 where c = 1 and d = 3; 由于联合索引树每个节点都是按照b,c,d排序的,此时没有给b的值,从联合索引树从上往下查找时,就确定不了该从哪里开始往下查找,所以只能走全表扫描;
select * from t1 where b = 1; 此时走索引,只匹配b的值,从上往下查找;
select * from t1 where b > 1; 此时会走全表扫描,原因是如果走索引,每条记录都会回表,会回表多次,还不如一次全表扫描来的快,InnoDB底层会判断要走索引还是全表扫描;
select b,c,d,a from t1 where b > 1; 此时会走索引,因为联合索引叶子节点已经保存了b,c,d的值和主键值,不需要回表;
暂时先记录这么多!
作者:Talent_Fly
链接:https://juejin.cn/post/6921912548006739976
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。