Hash索引
(1) 它会使用到hash函数,算出一个确切的值 , 如果key发生变化. hash值也会跟着发生变化. 而且还存在着hash冲突的情况.
(2) 联合索引的情况 hash(id+name) = hash值 , 不能支持 部分索引查询和范围查找.
红黑树
(1) 树太高,读取磁盘的次数过多, 1,2,4,8,16......
比如第一层只会存一个数据,读一次磁盘,就取1个数据 ,如果是n叉树,读一次磁盘可以拿到n个数据....
(2) 每次读取磁盘浪费太多
所以, 不适合做数据库索引, 毕竟它只是个二叉树,太浪费磁盘IO了.
红黑树用于HashMap的原因?

因为HashMap是内存数据结构,所以不存在上面提到的两个问题
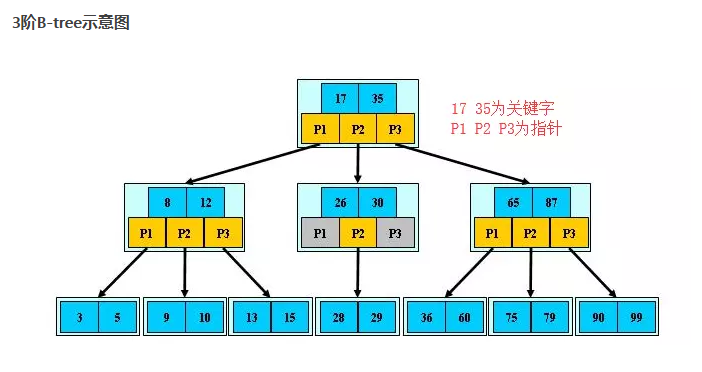
B树
B-tree, B+tree, B*tree
B-tree是n叉排序树.
M阶的Btree的几个重要特性:
1. 结节最多含有m颗子树(指针), m-1个关键字(存储数据的空间) (m>2)
2. 除根节点和叶子节点外,其它每个节点至少有ceil(m/2)个子节点, ciel向上取整 . 比如, 5/2 =2.5 (取整) = 3 . 分裂的时候从中间分开,分成两颗子树.
3. 若根节点不是叶子节点,则至少有两根子树
示例
创建一颗5阶Btree,插入的数据有3 14 7 1 8 5 11 17 13 6 23 12 20 26 4 16 18 24 25 19(数据库的userId),根据Btree的特点, 5阶Btree即一个磁盘空间最多有5个指针(存的查找路径), 4个关键字(mysql中存的数据)
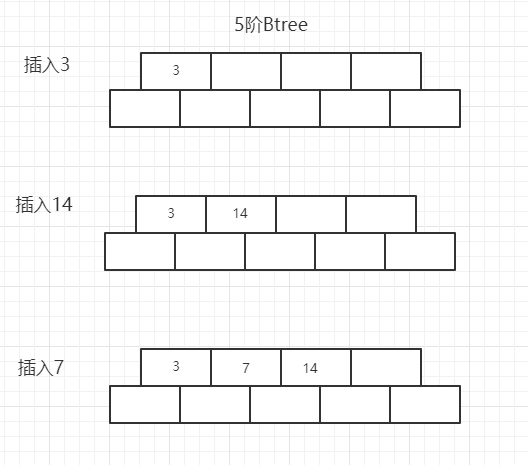
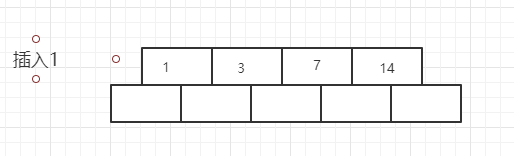
现在插入8,发现空间不够,就会出现一次分裂,移动中间元素到根节点即可

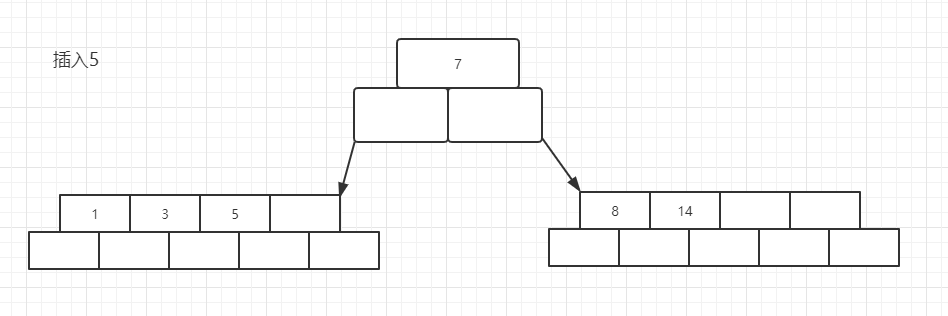
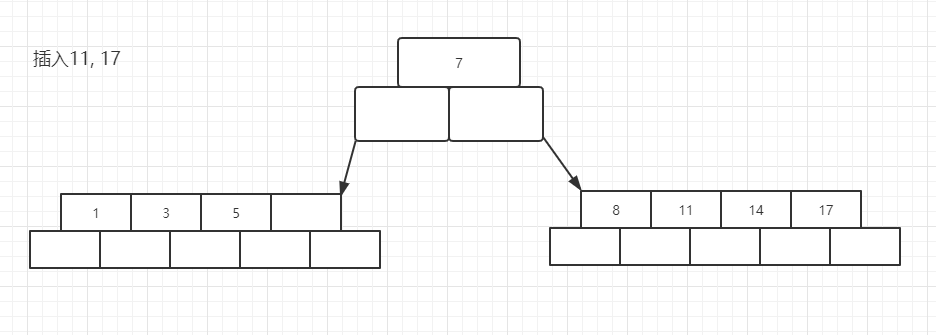
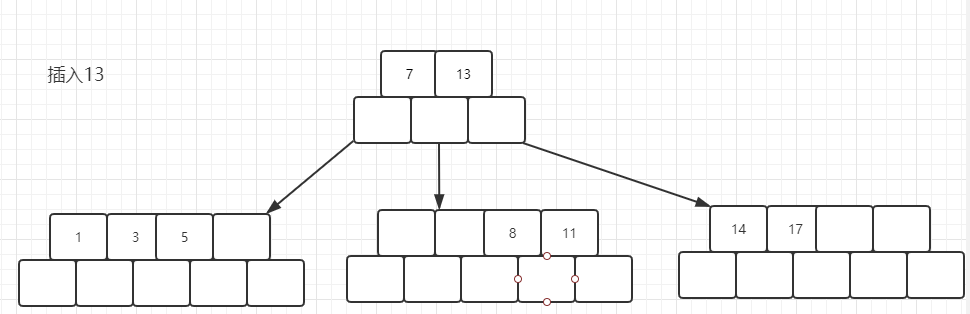
现在插入13, 7的右子树空间又不够了,将会再次发生分裂, 不过这次需要注意的是,13会插入到7的后面
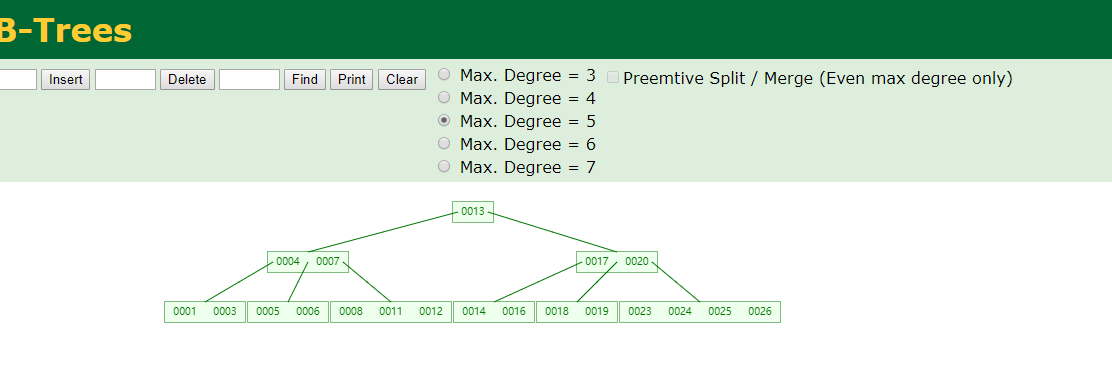
后面过程略,最终结构如下图所示
再比较一下B+tree的结构

MySQL是如何建联合索引的?
假设我们使用user_id+name+age建联合索引, MySQL的底层还是使用user_id字段来创建的索引,只不过使用user_id创建的这颗索引树的叶子节点不再是存储的MySQL数据,它存储的是 user_id+name+age+ 数据地址(这个地址指向了数据库的真实数据).
所以,在使用联合索引查询数据的时候,首先是通过user_id查找这颗树的叶子,然后在叶子节点中找到 user_id+name+age 对应的这条数据地址,然后再使用这个地址去磁盘读取数据.
联合索引也体现了最左原则,所以在使用联合索引查询的时候,如果没有user_id,MySQL根本就找不到索引树.所以,索引就会失败.
MySQL索引树一个节点存储关键字的多少 = 页大小(16K)/索引大小
每个节点上关键字越多,树就应该越矮, 查找速度也就更快, 所以,建索引的字段应该越小越好.
再来一个小示例
mysql> select * from tb_emp;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 乔峰 | 123 |
+----+--------+------+
1 row in set (0.00 sec)
mysql> show index from tb_emp;
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| tb_emp | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
# 创建一个name+age 的联合索引
mysql> alter table tb_emp add index `name_age_index`(name,age);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from tb_emp;
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| tb_emp | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | |
| tb_emp | 1 | name_age_index | 1 | name | A | 1 | NULL | NULL | YES | BTREE | | |
| tb_emp | 1 | name_age_index | 2 | age | A | 1 | NULL | NULL | YES | BTREE | | |
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
索引创建成功!
(1) name_age_index索引存在
mysql> explain select * from tb_emp where age =123;
+----+-------------+--------+------------+-------+---------------+----------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+----------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | tb_emp | NULL | index | NULL | name_age_index | 88 | NULL | 2 | 50.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+----------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
(2) drop name_age_index索引
mysql> drop index name_age_index on tb_emp;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from tb_emp where age =123;
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_emp | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
在原先的认知, name+age创建的组合索引name_age_index后,如果查询条件中没有使用name,仅使用age是不会走索引的.
然而,通过上面的测试可知,Extra给出的解释是Using where; Using index ,说明它即使用了索引, 也回了表.
删除name_age_index后,Extra给出的解释只有Using where, 说明只是回表查询.
why? 不知道!