注:本人已购买韦东山第三期项目视频,内容来源《数码相框项目视频》,只用于学习记录,如有侵权,请联系删除。
由于计算机只能识别 0 和 1,文字也只能以 0 和 1 的形式在计算机里存储,所以我们需要对文字进行编码才能让计算机处理,编码的过程就是规定特定的 01 数字串来表示特定的文字,最简单的字符编码例子是 ASCII 码。例如,Jz2440开发板通过串口把‘p’、‘o’、‘c’(对应的十六进制分别为:70、6F、43)三个字母发送到PC机,然后PC根据对应的编码在字体文件中找到相应字体数据(字体点阵),最后根据字体点阵把字体显示在LCD上。在现实生活中,字符和汉字是各种各样的,通过二进制可以将字符和汉字编程一个字符集(charset),每个字对应的二进制数就是字符的编码。字符编码经历了ASCII码、GB2312编码、Unicode编码三个阶段。

1. ASCII码
ASCII码是计算最早采用的字符编码方式,它使用一个字节8bit中的低7bit来表示英文、数字以及一些控制字符。ASCII 码表分为两部分,第一部分是控制字符或通讯专用字符,它们的数字编码从 0~31(如下图表1所示),它们并没有特定的图形显示,但会根据不同的应用程序,而对文本显示有不同的影响;第二部分包括空格、阿拉伯数字、标点符号、大小写英文字母以及“DEL(删除控制)”,这部分符号的数字编码从 32~127(如下图表2所示),除最后一个 DEL 符号外,都能以图形的方式来表示,它们属于传统文字书写系统的一部分。

2. GB2312编码
由于ASCII码不支持中文,常用的汉字有6763个,所以中国人发明了GB2312编码(GB国标)。它规定小于 127 的编码按原来 ASCII 标准解释字符;当 2 个大于 127 的字符连在一起时,就表示 1 个汉字,第 1 个字节使(0xA1-0xFE) 编码,第 2 个字节使用(0xA1-0xFE)编码,这样的编码组合起来可以表示了 7000 多个符号,其中包含 6763 个汉字。GB2312编码对字符进行了分区处理,一共分区了94个区(0xA1-0xFE),每个区有94个位(0xA1-0xFE),共8836 个码位。而区位码实际是 GB2312 编码的内部形式,它规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应 94 个区;第二个字节为“低字节”,对应 94 个位。所以它的区位码范围是: 0101-9494。为兼容 ASCII 码,区号和位号分别加上 0xA0 偏移就得到GB2312 编码,在区位码上加上 0xA0 偏移,可求得 GB2312 编码范围: 0xA1A1-0xFEFE。其中GB2312分区表如下图所示:详细的GB2312编码见:GB2312简体中文编码表

例如,“啊”字是 GB2312 编码中的第一个汉字,它位于 16 区的 01 位,所以它的区位码就是 1601,加上 0xA0 偏移,其 GB2312 编码为 0xB0A1,如下图所示:

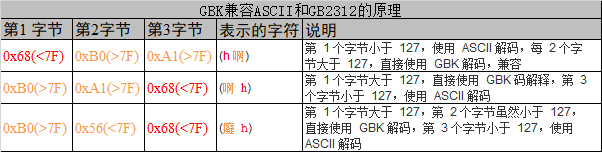
为了表示更多的汉字,对GB2312编码经过扩展后,有了GBK编码。GBK编码不再要求第 2 个字节的编码值必须大于 127,只要第 1 个字节大于 127 就表示这是一个汉字的开始,这样就做到了兼容 ASCII 和GB2312 标准。下表说明了 GBK 是如何兼容 ASCII 和 GB2312 标准的当我们设定系统使用GBK 标准的时候,它按顺序遍历字符串,按字节检测字符值的大小,若遇到一个字符的值大于 127 时,就再读取它后面的一个字符,把这两个字符值合在一起,用 GBK 解码,解码完后,再读取第 3 个字符,重新开始以上过程,若该字符值小于 127,则直接用 ASCII 解码。
3. Unicode编码(统一世界所有符号)
国际标准化组织(ISO)为了统一世界所有字符,重新给全球上所有文化使用的字母和符号进行编号,对每个字符指定一个唯一的编号(ASCII 中原有的字符编号不变),这些字符的号码从 0x000000 到 0x10FFFF,该编号集被称
为 Universal Multiple-Octet Coded Character Set,简称 UCS,也被称为 Unicode。Unicode 字符集只是对字符进行编号,但具体怎么对每个字符进行编码, Unicode 并没指定,因此衍生出了UTF-32、UTF-16、UTF-8这几种unicode 编码方案
3.1 UTF-32
UTF-32字符编码方式,它直接对Unicode 字符集里的每个字符都用 4 字节来表示,转换方式很简单,直接将字符对应的编号数字转换为 4 字节的二进制数,例如:A = 0x0000 0041,啊 = 0x0000 554A.。由于 UTF-32 把每个字符都用要 4 字节来存储,因此 UTF-32 不兼容 ASCII 编码。UTF-32 的优点是编码简单,解码也很方便;它的缺点是浪费存储空间,大量常用字符的编号只需要 2 个字节就能表示。
3.2 UTF-16
对于UTF-32 的缺点,人们改进出了 UTF-16 的编码方式,它采用 2 字节或 4 字节的变长编码方式(UTF-32 定长为 4 字节)。对 Unicode 字符编号在 0 到 65535 的统一用 2 个字节来表示,将每个字符的编号转换为 2 字节的二进制数,即从 0x0000 到 0xFFFF。例如:A = 0x0041,啊 = 0x554A.。UTF-16 编码的优点是相对 UTF-32 节约了存储空间,缺点是仍不兼容 ASCII 码。
3.2 UTF-8
UTF-8 是目前 Unicode 字符集中使用得最广的编码方式,它也是一种变长的编码方式,它的编码有 1、 2、 3、 4 字节长度的方式,每个Unicode 字符根据自己的编号范围去进行对应的编码。它的编码符合以下规律:
(1) 对于 UTF-8 单字节的编码,该字节的第 1 位设为 0(从左边数起第 1 位,即最高位),剩余的位用来写入字符的 Unicode 编号。即对于 Unicode 编号从 0x0000 0000 - 0x0000 007F 的字符, UTF-8 编码只需要 1 个字节,因为这个范围 Unicode 编号的字符与 ASCII 码完全相同,所以 UTF-8 兼容了 ASCII 码表。
(2) 对于 UTF-8 使用 N 个字节的编码(N>1),第一个字节的前 N 位设为 1,第 N+1 位设为 0,后面字节的前两位都设为 10,这 N 个字节的其余空位填充该字符的Unicode 编号,高位用 0 补足。下表是 UTF-8 编码原理:

例如:“中” 的 Unicode 编号 为 0x4E2D (二进制:100 1110 0010 1101)。由上表可知,0x4E2D 落在 0x00000800-0x0000FFFF 的范围,所以“中”的 Unicode 编码 需要用 3 个字节表示,其格式为:1110xxxx 10xxxxxx 10xxxxxx。接着,从“中”Unicode 编号的二进制最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。所以得到“中”的UTF-8编码为11100100 10111000 10101101,它的16进制为0xE4B8AD。
UTF-8解码原理: UTF-8 解码的时候以字节为单位去看,如果第一个字节的 bit 位以 0 开头,那就是ASCII 字符,以单字节进行解析。如果第一个字节的数据位以“110”开头,就按双字节进行解析, 3、 4 字节的解析方法类似。
UTF-8 的优点: 兼容了 ASCII 码,节约空间,且没有字节顺序的问题,容错能力高。
Unicode转UTF-8 代码:
#include <stdio.h>
int Unicode_to_Utf8(unsigned long unicode, unsigned char *output_utf8)
{
if(unicode <= 0x7F) /*一个字节*/
{
*output_utf8 = unicode & 0x7F;
return 1;
}else if(unicode >= 0x80 && unicode <= 0x7FF) /*两个字节*/
{
*(output_utf8 + 1) = (unicode & 0x3F) | 0x80;
*output_utf8 = ((unicode >> 6) & 0x1F) | 0xA0;
return 2;
}else if(unicode >= 0x800 && unicode <= 0xFFFF) /*三个字节*/
{
*(output_utf8 + 2) = (unicode & 0x3F) | 0x80;
*(output_utf8 + 1) = ((unicode >> 6) & 0x3F) | 0x80;
*output_utf8 = ((unicode >> 12) & 0xF) | 0xE0;
return 3;
}else if(unicode >= 0x10000 && unicode <= 0x10FFFF)
{
*(output_utf8 + 3) = (unicode & 0x3F) | 0x80;
*(output_utf8 + 2) = ((unicode >> 6) & 0x3F) | 0x80;
*(output_utf8 + 1) = ((unicode >> 12) & 0x3F) | 0x80;
*output_utf8 = ((unicode >> 18) & 0x7) | 0xF0;
return 4;
}else
{
printf("error, it is not a unicode\n");
return 0;
}
return 0;
}
int main(void)
{
unsigned long unicode = 0x4E2D; /*“中”的unicode码*/
unsigned char output_utf8[4];
int len, i;
len = Unicode_to_Utf8(unicode, output_utf8);
if(!len) return 0;
for(i = 0; i < len; i++)
{
printf("%.2X ",output_utf8[i]);
}
printf("\n");
return 0;
}
编译运行程序,打印的结果如下图所示:正确打印出“中”字的UTF-8编码0xE4B8AD。

4. 文件标志
一般一个文件的开头会有标志,通过十六进制编辑文件,便可以看到
(1) EF BB BF 表示utf-8
(2) FE FF表示utf-16大端(大开头,比如a=00 61)
(3) FF FE 表示utf-16小端(小开头,比如a=61 00)
(4) 没有前缀 表示ANSI格式
5. 源文件的格式不同,执行的结果也不同
(1) 使用Notepad++编写以下代码,然后另存为ansi.c 和 utf-8.c 两个文件,编码分别选择ANSI(GBK编码)和UTF-8格式;
#include <stdio.h>
int main(int argc, char **argv)
{
int i = 0;
unsigned char s[] = "abc中";
while(s[i])
{
printf("%02x ",s[i]);
i++;
}
printf("\n");
return 0;
}
(2) 把编写好的ansi.c 和 utf-8.c 两个文件上存到ubuntu服务器执行以下命令编译:
gcc -o ansi ansi.c
gcc -o utf-8 utf-8.c
执行结果如下图所示:
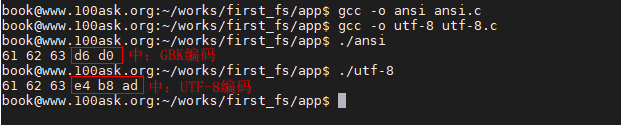
从上图可知,同一个源程序,使用不同的编码格式,执行的结果也不同。那么,如何解决这个问题呢?
(3) 解决文件格式不同,编码也不同的问题:编译程序时,指定字符集(即强制编译器以什么编码格式解析程序)。
(4) 如何指定字符集?
① 执行命令 ,查看gcc使用手册:
man gcc //查看gcc使用手册
②执行命令,查找字符集:
/charset //搜索charset相关字
③ 找到如下结果:
-finput-charset=charset //表示源文件的编码方式, 默认以UTF-8来解析
-fexec-charset=charset //表示可执行程序里的字时候以什么编码方式来表示,默认是UTF-8
④ 指定字符集(charset):
gcc -finput-charset=GBK -fexec-charset=UTF-8 -o utf-8_2 ansi.c
上述命令的意思是:告诉gcc编译器该文件是GBK编码,需要转换为UTF-8编码,然后再编译,这样就可以解决程序文件格式的问题。
编译后程序的执行结果如下图所示:
