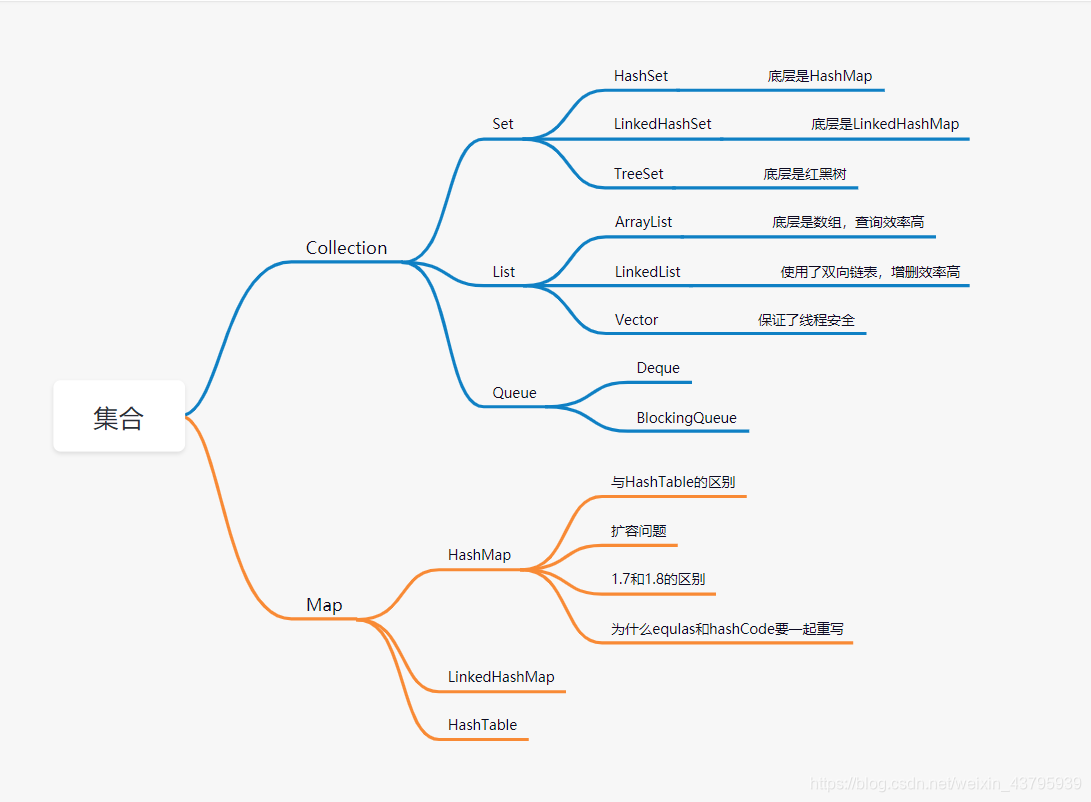
集合:
1. 集合的架构
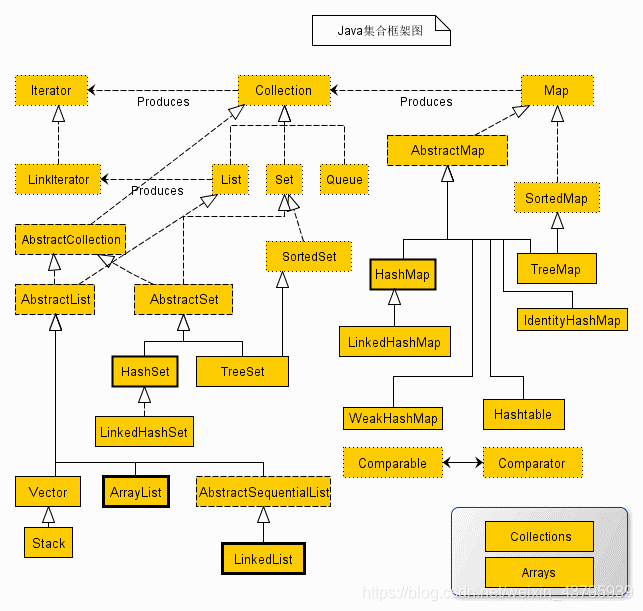
从该图可以直观的看出整个结构,java集合包含了两种类型的容器:
Collection:存储元素集合Map:存储kv映射
Collection接口又有三种子类型:
SetListQueue
后面又是一些抽象类,还有一些实现类:
ArrayListLinkedListHashSetHashTableTreeSetLinkedHashSetHashMapLinkedHashMap
2. 常见集合的底层实现
ArrayList底层是数组LinkedList底层是双向链表HashMap和HashTable是数组+链表,java8之后同一位置的哈希冲突大于8则链表变为红黑树HashSet底层是HashMapLinkedHashMap底层修改自HashMap,包含了一个维护插入顺序的双向链表LinkedHashSet底层是LinkedHashMapTreeMap底层是红黑树TreeSet底层是TreeMap
3. 常见问题
3.1 ArrayList和Vector的区别
vector是线程安全的,而ArrayList是线程不安全的(点进源码,可以看到vector的很多方法被synchronized关键字修饰了,一种同步机制)vector在数据满时变为原来的两倍,而ArrayList在数据满时增长为原来的1.5倍




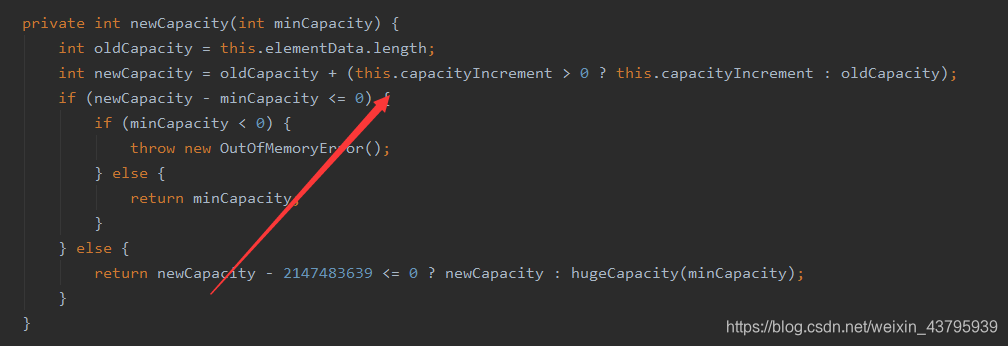
上面时Vector的源码,从熟知的add方法一直找下去,发现当s == elementData.length即数据量满了就会触发扩容,且如果构造方法不传入capacityIncrement那么就会加上原来的容量,这就是为什么扩成了2倍。
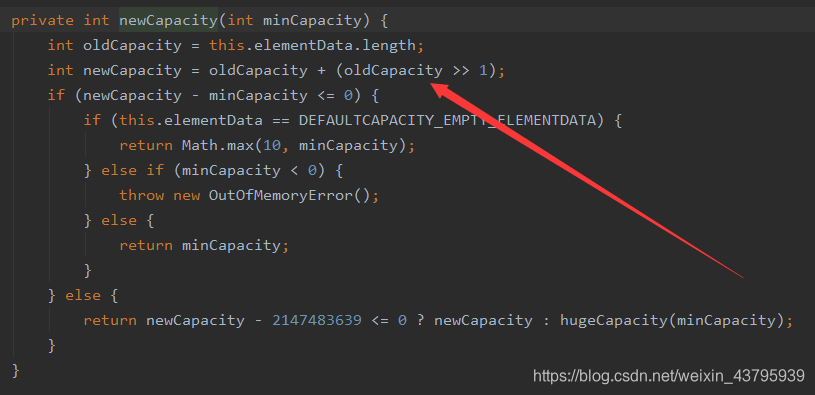
这是ArrayList扩容成1.5倍的源码
3.2 ArrayList和LinkedList的区别
LinkedList基于链表的数据结构,ArrayList基于动态数组的数据结构- 根据上面的数据结构也可以想到,
LinkedList在插入删除时候效率高,ArrayList查询效率更高
3.3 HashMap的底层
jdk7之前是数组+链表,如下图

put过程:
- 数组初始化,在第一个元素插入HashMap时做初始化,先确定了初始数组大小
- 计算具体数组位置,根据key进行hash运算
- 找到下标后判断是是否key重复,如果没重复放在表头(头插法,1.8Z之后改成尾插法)
- 在插入新值之前,如果size达到了阈值,并且当前插入的数组位置上已经有了元素,就会触发扩容。
get过程:
- 根据key算出hash值
- 根据hash找到对应的数组下标
- 遍历该位置的链表,找到相等的key
jdk8使用了数组+链表+红黑树
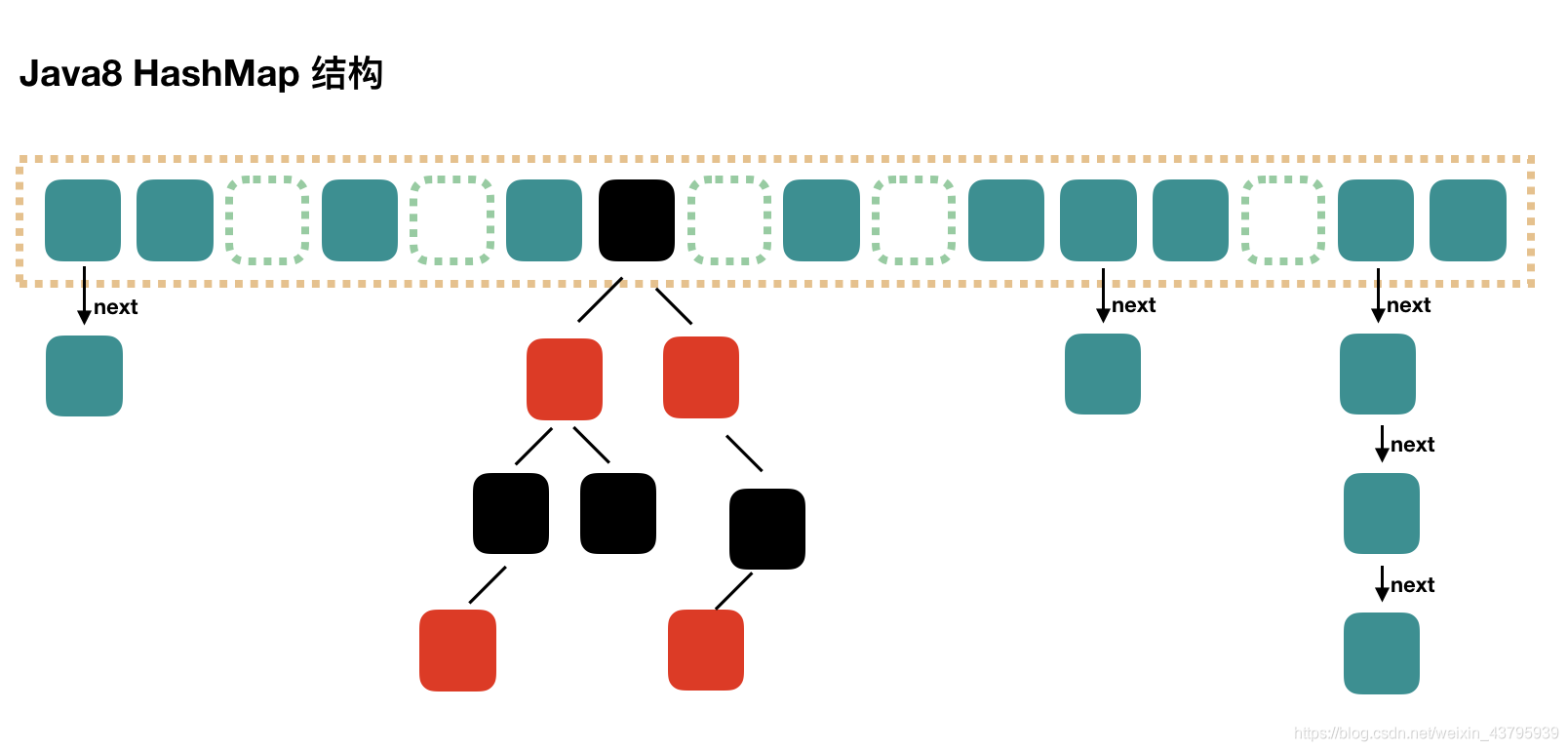
jdk7中Entry代表节点,jkd8改用Node,换成红黑树之后使用TreeNode
put过程:先插值再扩容
3.4 HashMap与HashTable的区别
- HashMap没有考虑线程安全的问题,HashTable则是线程安全的
- HashMap允许
KV是null,HashTable不允许
3.5 HashMap的负载和容量问题
为什么负载因为默认为0.75呢?
- 当负载因子为0.5的时候,因为默认容量为16,那么达到8时就要扩容成32,达到16时就要扩容成64,这样下去空间利用率会极低。
- 当负载因子为1的时候就是空间用完再扩容,会增加put操作的等待时间。
- 好吧,真实的原因实在看不懂,那数学式子有毒。
为什么扩容后要重新hash呢?
因为Hash公式里面带了长度,如果不重新计算是get不到的。
容量为什么要是2的幂次方呢?
哈希公式是
hash & (length - 1),length是容量长度,默认是16即1 << 4
这样length - 1的二进制表示全部是1,index索引位置等于hashcode的后几位,所以HashCode只要均匀,hash算法结果就均匀
- 实现了均匀分布
- 位运算速度快
为什么重写equlas就也要重写HashCode?
看HashMap的get过程调用了如下方法
看这个源码,要先调用目标对象的hash方法,找到地址算出index索引之后,就是找链表或者红黑树上的结点了,找的时候调用了equals,如果只是重写equlas方法而不重写hashCode,那就默认继承了Object类的hashCode即地址,就算两个对象内容一样,地址不可能相同的,所以索引位置都不一样,怎么可能找得到。