前段时间琢磨了下人头检测这个功能,现在有了初步的认知和体会,下面开始讲下我在实现人头检测过程中遇到的坑和解决方法。
环境搭建:pycharm,python2.7,opencv2.7,numpy。
这些个环境都是前期准备的,安装和配置都挺方便的,不得不说这里就是python的各种功能的库是真的多,前辈们真是值得膜拜。这里给出一个我下载那些库的网站,python库下载
下载了需要的库用pip安装就行。
进入正题,因为opencv只有现成的人脸识别特征分类器,但是没有人头识别的,所以需要自己训练一个。这里我采用的是HAAR特征训练分类器。看了很多这方面的博文,大多数用的HAAR特征,所以也就开始就打定主意使用这个特征来训练,后面也简单了解了下HAAR特征和LBP特征,HAAR特征是将图像中相同像素内的白色部分减去黑色部分得到该区域的HAAR特征值,反应了图像的灰度变换情况;LBP特征则是将每个像素周围看成一个3*3的正方形,将中心像素的值作为阀值,周围8个点像素点与中心点做比较,若像素大于中心点则与中心像素作比较的点的LBP值置为1,反之为0。这样就得到一个中心的LBP值,反应区域的纹理信息。得到特征值后,用特征值作为分类依据训练分类器的事情就是那些个算法做的事情了,这里我就不发表拙见了。看看大牛写的一篇文章吧,涉及到很多数学内容,细细看还是会很有理解的。图像特征提取。
接下来进行具体训练过程:
1.创建一个训练所用的文件夹,目录结构如下:
各目录作用:
data:用于存放正样本描述文件pos.vec,由opencv_createsemples.exe产生。
data1:用于存放训练生成的级联分类器文件(casacade.xml),以及训练各阶段产生分类器(stages1.xml,stages2.xml等等)。
negdagta:用于存放负样本文件。
posdata:用于存放正样本文件。
最下面的那五个文件即是opencv所提供的训练所用算法的exe文件。可以在我的百度云分享里面下载:http://pan.baidu.com/s/1bpNCBj5
2.在正负样本目录下各自生成其数据文件:posdata.dat和negdata.dat。
命令为:


这样正负样本的数据文件都在其各自目录下生成了,接下来进行修改数据文件。打开数据文件的编辑界面,删掉数据文件最后面的posdata.dat,同理删除负样本数据文件里面的negdata.dat。如图:
接下里修改数据文件成我这样,posdata.dat:

negdata.dat:
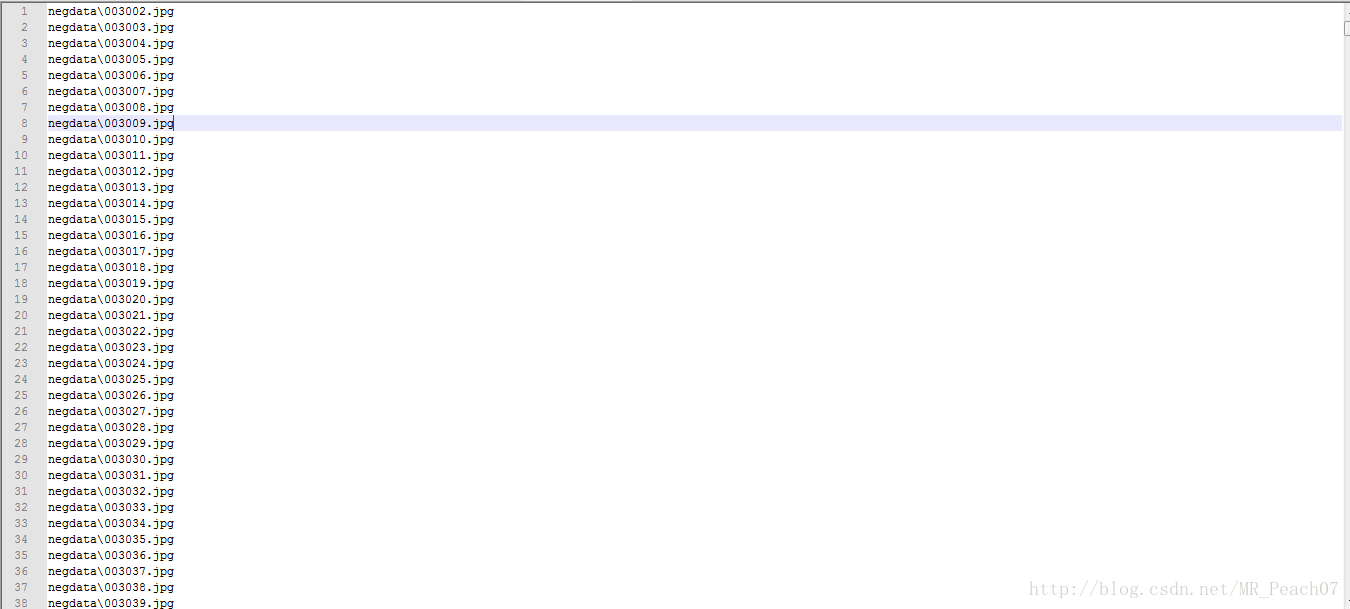
解释下 1 0 0 20 20这个参数的意思,1代表文件,0 0 20 20,是这个目录下每一张图片的坐标,因为是二维的,而且我正样本所有图片全是20*20像素的,所以就是(0,0)点到(20,20)点,即是读取图片时,从左下角扫描到右上角。
注意:在负样本的数据文件里面,要给每一个图片文件加上他的相对地址,因为默认我们训练时,是在negdata的父目录下进行,即是你创建的训练文件夹下进行。
3.准备工作已经完成,下面开始训练具体操作,首先用opecv_createsamples.exe生成样本描述文件pos.vec。命令如下:
opencv_createsamples.exe -info posdata -vec data\pos.vec -num 你所需要创建的正样本数量(一般为正样本内文件数目的0.9倍) -w 20 -h 20
生成了正样本描述文件后,接下来就是用opencv_traincascade.exe进行分类器的生成。命令如下:
opencv_traincascade.exe -data data1 -vec data\pos.vec -bg 64negdata numPos 243 -numNeg 300 -minHitRate 0.9999 -maxFalseAlarmRate 0.5 -featureType HA
AR -numStages 20 -w 20 -h 20
各个参数的意思我这里就不赘述了,给一篇大牛写的文章,大家自行参考。http://note.sonots.com/SciSoftware/haartraining.html#e134e74e
接着,等着他训练完成就行。
最后我来说下我训练过程中碰到的坑和解决的办法:
1.训练参数中-bg,即负样本路径不正确,仔细检查后就能解决。

2.训练参数中的-numPos,-numNeg,一定要比实际的正负样本文件夹中样本数目少,千万不要强迫症,不然就会在训练中途停止,并报如下错误:Assertion failed (elements_read == 1) in icvGetHaarTraininDataFromVecCallback,file..\opencv\apps\haartraining\cvhaartraining.cpp, line 1861”
3.正负样本采集问题,开始我用的网上下的样本库训练,虽然样本数量很多,但是正样本质量太差,导致训练结果一直很差,所以就想到了自己采集样本的办法,这样就解决了这个问题。ps:可以自己写个截图工具来完成样本采集工作,正样本数量上的话,上千张就会有很好的效果了,一定注意要加些灰度处理后的正样本图片,会增加些精确度;负样本的话,大概与正样本的三倍,因为后面出现负样本不足的情况,可以换一批负样本接着训练。
4.训练到后面,训练终止,提示负样本不足,这个问题是我碰到的最难解决的问题了,我的解决方法是,用新的负样本替换掉negdata里面的负样本文件,然后重新生成相应的negdata.dat,接着用相同参数训练,这样就相当于boosting算法,能够重新在新的负样本中进行筛选,就能解决负样本不足情况。这样做还有个好处是,不用赋予-numNeg特别大的值,导致其他错误。
5.关于正负样本比例问题,这个问题看你所需要的训练场景而论,如果你训练的分类器用于变化比较大的环境,建议你正负样本比例至少是1:2;如果分类器用于环境变化较小的情况,就是我所面临的场景,我的建议是1:1。
至此,我的样本训练过程就完成了,最后,贴一张最终训练效果图,这是训练了接近是个分类器后,最好的一个了,基本达到了要求,进一步提升精确度就需要在图像预处理部分,和“去抖动”部分琢磨。
