前言
我们都知道,有时候redis服务器遇到了突发情况,比如宕机的话,那么服务器主节点就瘫痪了,也就不能写数据了,如果我们每次都自己手动去配置,重新为redis设置一个新的主节点,会比较麻烦,而且也会造成一定的时间内服务不可用,因此这不是一种推荐的模式,更多的时候,我们采用哨兵模式来自动解决这个问题,一旦某个主节点不可用,那么哨兵之间投票,选举一个从节点担任新的主节点,然后其他的从节点自动修改配置文件,把自己的master设置为新担任主节点的那个从节点。
一、哨兵模式是什么?
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是**哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
当哨兵检测到master宕机时,会自动把slave切换成为master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机,从而客户端能够再次写数据。
然而仅仅是一个哨兵对redis服务器进行监控还不够,因为一个哨兵监控本身也会出现一些问题,所以我们可以采用对个哨兵之间也进行监控。这样的话,不仅仅哨兵对redis服务器进行监控,哨兵之间也进行了监控(多哨兵模式)
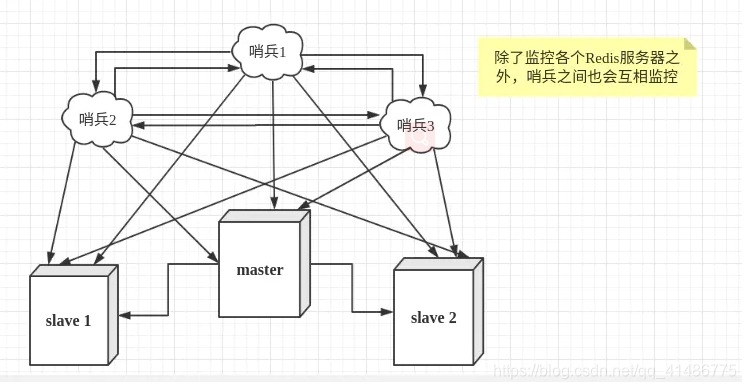
故障切换(faillover)
- 主观下线(redis服务器宕机,哨兵检测到了这个结果,并不会进行faillover过程,仅仅是一个哨兵认为这个服务器而已,可以理解为权限不够,这个现象叫做主观下线)
- 哨兵投票,故障切换(后面的多个哨兵也检测到了服务不可用,那么他们之间会进行投票表决,选举一个新的主节点,注意投票由一个哨兵发起。)
- 客观下线(故障切换成功之后,那么就会通过发布订阅模式,把这个消息发布给其余的哨兵,让他们把各自监控的从节点服务器进行切换主机,这个过程叫做客观下线。)
一整个流程走完,对于客户端都是透明的,不知道!
二、使用步骤
1.搭建环境
在redis的安装目录下有一个sentinel.conf配置文件,它就是跟哨兵模式配置相关的。
查看sentinel.conf的配置文件
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,127.0.0.1代表监控的主服务器,6379代表端口,1代表只有一个或一个以上的哨兵认为主服务器不可用的时候,才会进行failover(故障切换)操作。
sentinel monitor mymaster 127.0.0.1 6379 1
复制redis安装目录下的sentinel配置文件到/usr/local/bin/myconfig/下
[root@localhost local]# cp /usr/local/redis-6.0.9/sentinel.conf /usr/local/bin/myconfig/
[root@localhost local]# cd /usr/local/bin/myconfig/
[root@localhost myconfig]# ls
6379.log dump6380.rdb dump.rdb redis6380.conf redis.conf
6381.log dump6381.rdb redis6379.conf redis6381.conf sentinel.conf
启动哨兵模式
[root@localhost myconfig]# redis-sentinel /usr/local/bin/myconfig/sentinel.conf
6159:X 09 Feb 2021 10:19:04.629 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
6159:X 09 Feb 2021 10:19:04.629 # Redis version=6.0.9, bits=64, commit=00000000, modified=0, pid=6159, just started
6159:X 09 Feb 2021 10:19:04.629 # Configuration loaded
6159:X 09 Feb 2021 10:19:04.631 * Increased maximum number of open files to 10032 (it was originally set to 1024
开启三个redis服务
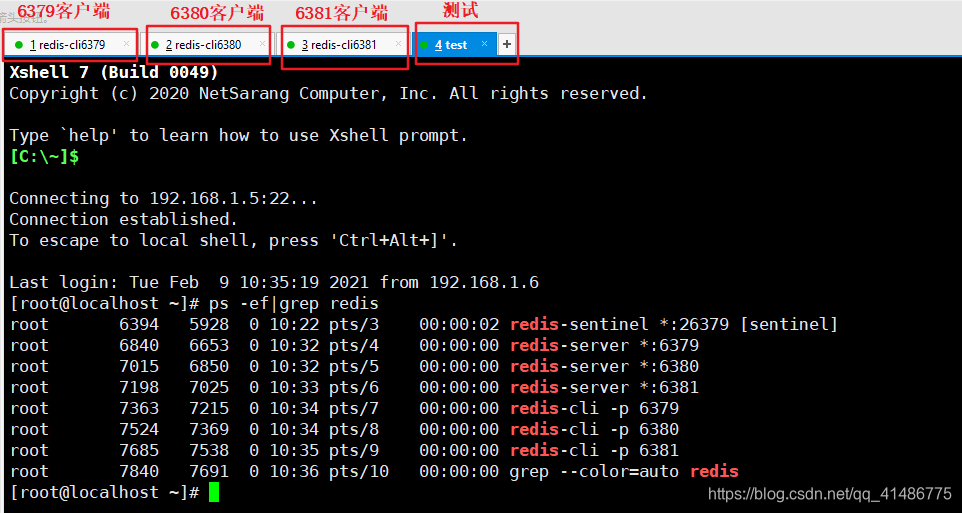
然后开启三个客户端
现在我们让6380服务成为6379服务的从机,让6381服务成为6379服务的从机
#6380客户端
127.0.0.1:6380> slaveof 192.168.1.5 6379
OK
127.0.0.1:6380>
#6381客户端
127.0.0.1:6381> slaveof 192.168.1.5 6379
OK
127.0.0.1:6381>
#在6379客户端查看主从复制信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 #6379从机数量2个
slave0:ip=127.0.0.1,port=6380,state=online,offset=37524,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=37524,lag=0
master_replid:dc9ef83dc08d48b93c5d62b02511ea24f9a90642
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:37524
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:37524
127.0.0.1:6379>
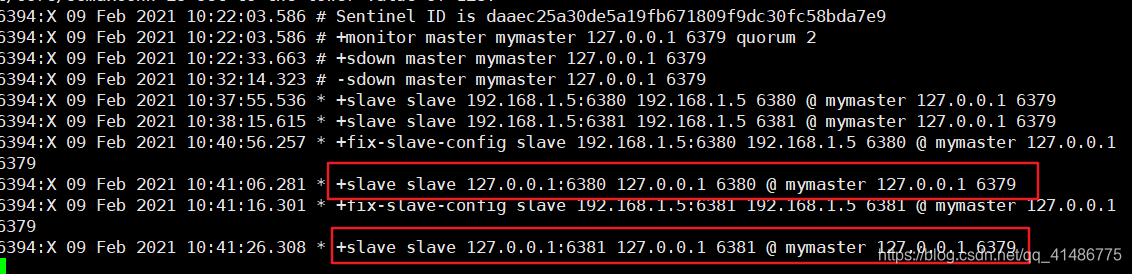
在开启了哨兵模式之后,就会发现这里已经成功监控到了两个从机6380和6381
2.测试
重点来了,现在我们把6380服务端口断开,看看会发生什么?
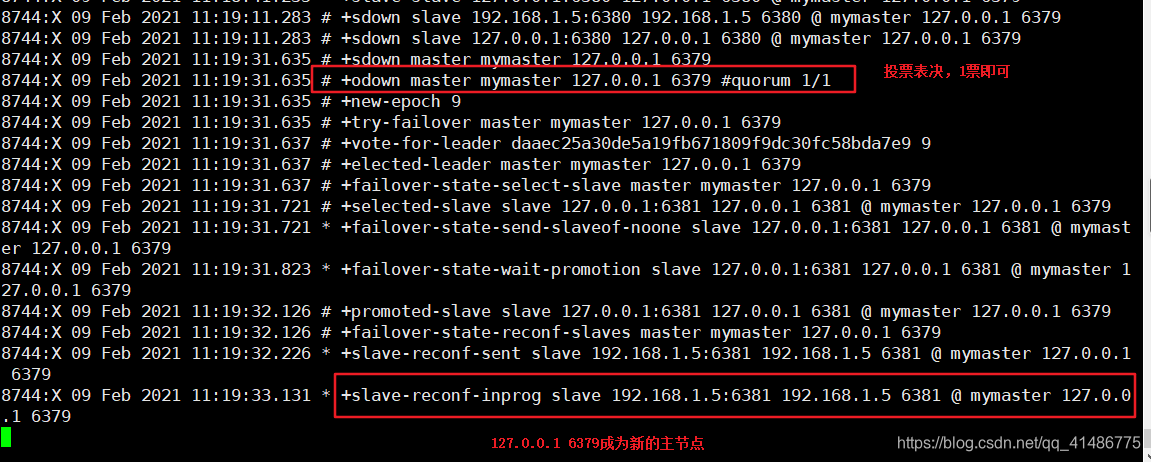
redissentinel.conf配置文件详解
# 哨兵sentinel实例运行的端口,默认26379
port 26379
# 哨兵sentinel的工作目录
dir ./
# 哨兵sentinel监控的redis主节点的
## ip:主机ip地址
## port:哨兵端口号
## master-name:可以自己命名的主节点名字(只能由字母A-z、数字0-9 、这三个字符".-_"组成。)
## quorum:当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass <foobared>,所有连接Redis实例的客户端都要提供密码。
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
# 指定主节点应答哨兵sentinel的最大时间间隔,超过这个时间,哨兵主观上认为主节点下线,默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 指定了在发生failover主备切换时,最多可以有多少个slave同时对新的master进行同步。这个数字越小,完成failover所需的时间就越长;反之,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为1,来保证每次只有一个slave,处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间failover-timeout,默认三分钟,可以用在以下这些方面:
## 1. 同一个sentinel对同一个master两次failover之间的间隔时间。
## 2. 当一个slave从一个错误的master那里同步数据时开始,直到slave被纠正为从正确的master那里同步数据时结束。
## 3. 当想要取消一个正在进行的failover时所需要的时间。
## 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来同步数据了
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# 当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本。一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
# 对于脚本的运行结果有以下规则:
## 1. 若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10。
## 2. 若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
## 3. 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
三、总结
哨兵模式配置起来有点繁琐,但是一旦真正配置好了,就可以省去很多时间,当其中的某个节点断了,哨兵之间会自动选举一个新的主节点。因此可以保证服务的可用性。
