CNN高效卷积实现算法和应用综述(下)
论文分析
1. Fast Algorithms for Convolutional Neural Networks
分析的第一篇文章是16年CVPR,由于是CVPR中第一次将Winograd算法引入,大篇幅介绍了Winograd算法的原理,矩阵的操作,转化,没有做任何优化,直接按照矩阵公式操作的。其中与FFT进行了比较。现在看来,在追求快速和高的FLOPS指标下,完成相同任务的MACC操作数越少,则越高效。这个在CNN的网络Pruning中是一个重要指标,相同时间,增加FLOPS,网络Parameter Size为目的。FFT并不占优势。作者比较了cuDNN和Winograd算法的TFLOPS的比较。其中Winograd算法F(2x2,3x3)在上一篇综述中已经详细分析了理论。不懂的请查看上一篇综述文章(高效卷积实现算法和应用综述(上))。https://blog.csdn.net/qq_32998593/article/details/86177151
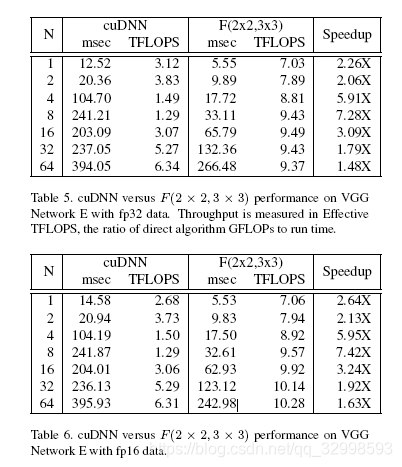
从上表可以看出,Winograd算法的TFLOPS比cuDNN的计算性能高,相同的网络,处理时间更低。
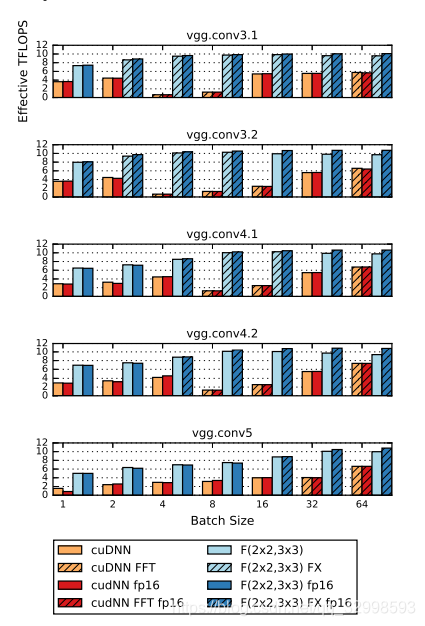
从上图可以看出,Winograd算法比cuDNN的GEMM算法拥有更高的计算能力,更低的操作数。
2. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs
下面是商汤中Winograd算法FPGA实现,17年发表在FCCM中的论文。
用更多的加法来替代乘法,传统的卷积实现,需要6层循环,而采用Winograd算法,只需要4层循环。

采用原始的卷积操作,需要6层for循环运算。而采用Winograd算法,在里面的两层,只需要调用Winograd(X,F,Y)这个计算模块,就能直接计算出卷积参数。少了60%以上的乘法操作。在FPGA实现中,首先就要避免直接计算乘法,尽量用移位来代替。在乘法资源如此昂贵的FPGA上,这个Winograd算法能够减少乘法操作,当然很受业界欢迎。带来了一大部分科研人员致力于Winograd算法在FPGA的高效实现。
作者利用line buffer架构,将输入的数据进行缓存,同时将每一组kernel从cache上取出来,放进设计好的PE模块中进行Winograd矩阵乘法。
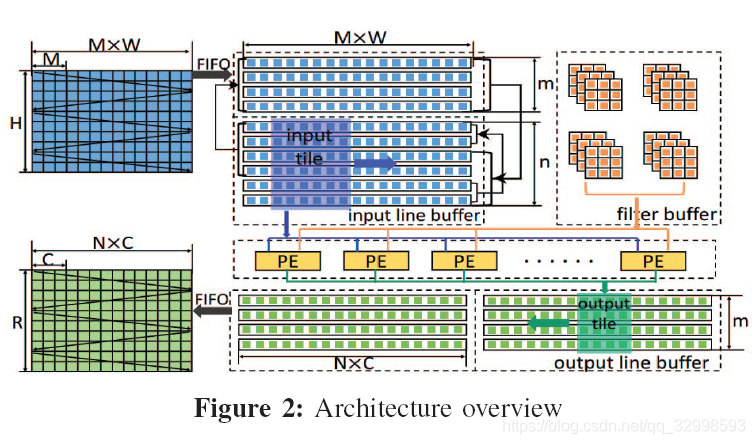
这里具体的目的就是按模块划分好各个功能,然后利用片上的line buffer,也就是BlockRAM来进行缓存,每6行就拿去做Winograd卷积,然后Stride为4。PE为一个专门的Winograd卷积模块。如下图所示为具体的操作:

每一个矩阵的转换需要的矩阵是固定的(A,B,G)是离线的,将矩阵的乘法分为4步,为了节省片上的BRAM,先对input和filter进行转换,这里面是采用的LUT进行,由于转换矩阵B和G的特点,只需要进行位运算。第二步,进行EWMM计算,第三步,计算Y的转换矩阵,最后,按通道累加得到对应的output。
对比的指标包括GOP/s,能源效率GOP/s/W。这个可以通过FPGA的开发平台进行评估。
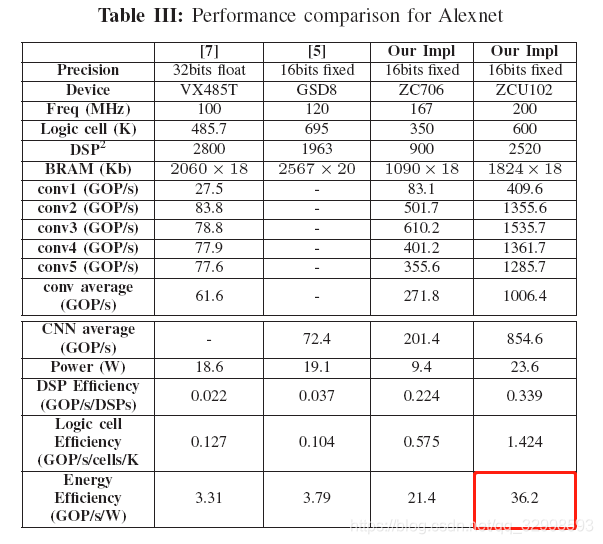
在AlexNet上进行对比,与其他平台相比,在ZYNQ上的销量有10x以上的提高。
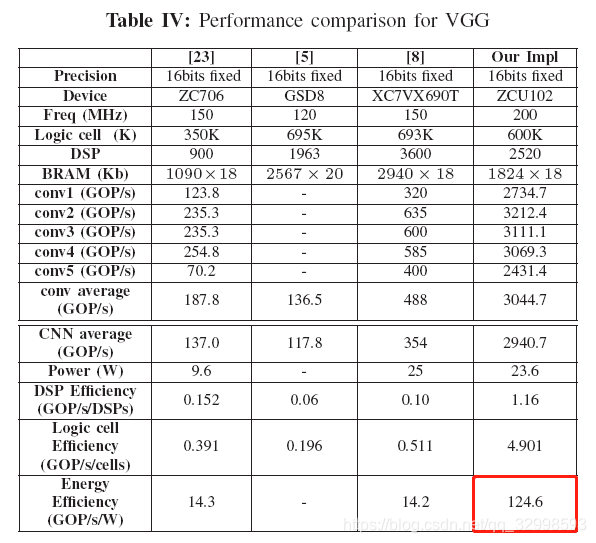
在VGG的实现对比上,与其他原始的实现相比,采用Winograd卷积算法的实现由将近8.7x的提升。
与GPU相比,也在效率上有一定提高。(PS:比计算峰值,吞吐量,TOPs比不过GPU,但是一旦牵扯到电源消耗,Watt数,就比GPU有很大的提高。不在一个数量级的电源效率。)

3. Efficient Sparse-Winograd Convolutional Neural Networks
这是MIT韩松指导的论文,发表在ICLR 2018年会议上,延续了他的风格,做剪枝,网络的稀疏化,减少了计算过程中的乘法次数。将稀疏性引入卷积转换上。
将剪枝后的稀疏性用在Winograd卷积实现上,充分减少乘法的次数,将近10.4x,6.8x和10.8x的减少。如果在传统算法上进行ReLU和Prune,在未变换之前,Activation Layer和Kernel Layer是稀疏的,当进行变换后,在做EWMM时,一样的是非稀疏的乘法,没减少乘法次数。而作者将变化在ReLU和Prune之前,使得经过稀疏操作的矩阵就是能够直接进行Winograd算法的矩阵,减少了乘法次数。
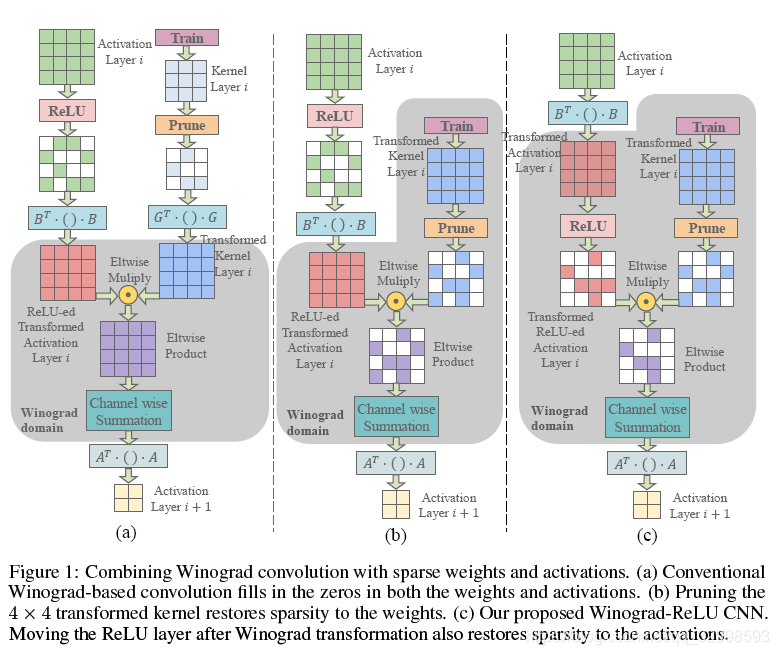
具体的内容可以在论文中去查看。这个图解释的非常清楚,相同的稀疏方法加在不同的地方,对结果的不同影响。
其中做稀疏化的公式为:
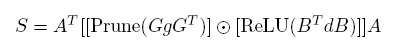

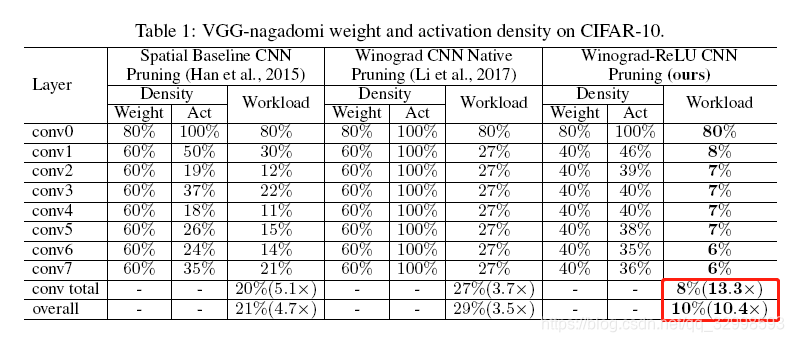
最终VGG在CIFAR10上的精度比较,可以看出在大密度剪枝的情况下,最终的分类精度没有掉太多。且带来的13.3x的计算负载降低。减少了权值的数量,减少了乘法次数。
其他数据集上的比较,ImageNet,CIFAR100,Resnet的实现等,可以查看该论文。
4. Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
这是一篇在FPGA 2018 顶会上发表的一篇论文,作者将Winograd算法的2D卷积扩展到3D卷积,在FPGA上实现。建立了统一的计算模板。具体示意图如图所示。

将矩阵的转换,卷积的操作,全部作为整体,这样会减少更多的乘法次数,会节省FPGA上的乘法器资源。

这个卷积的实现,对比第二篇论文,即商汤在FPGA上的实现图,可以看出两篇文章的for循环的层数都是相同的,本文在3D的Winograd算法进行了优化,做了更多的处理,使得原本的2D矩阵乘法能够扩展到3D上。其实现过程更加复杂。
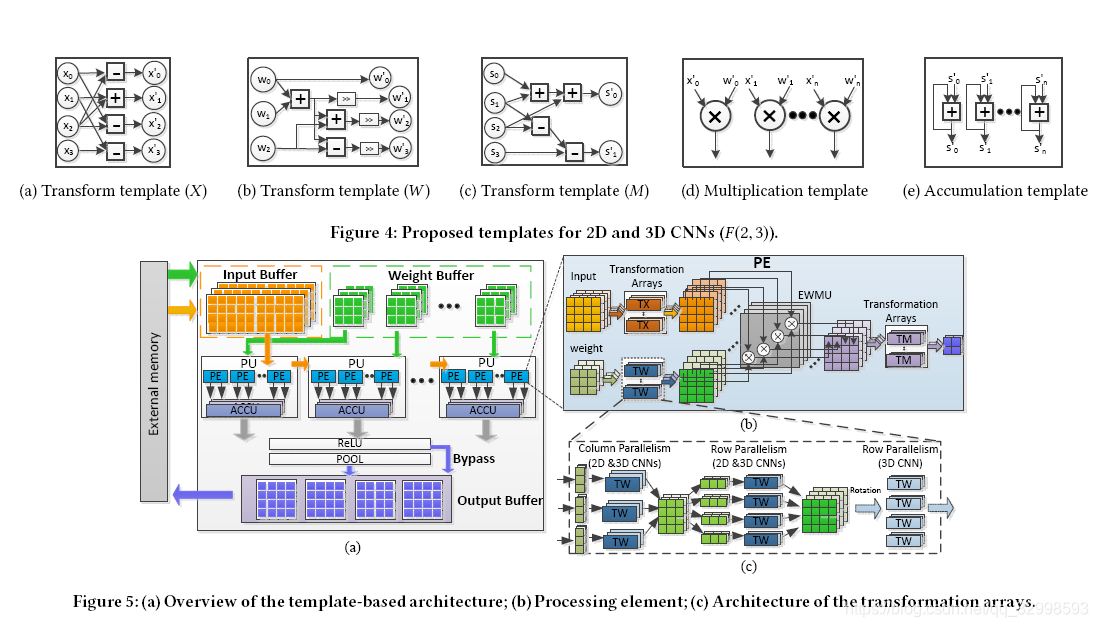
具体的实现过程如上图所示。将矩阵的转置,矩阵的乘法,先在模板中进行变换,最后在PE中进行Winograd最后的element-wise matrix multiplication。其实可以看出,这个模块和商汤的那篇文章很像,整个流水和处理的结构都很相似。

从最后的评估结果可以看出,性能都有很大的提升。在1.0 TOPS以上去了。更多的内容可以查看论文。
在关于Winograd算法,GEMM等高效卷积实现的算法分析在上一篇综述中,请参阅上一篇综述。上一篇综述文章地址。https://blog.csdn.net/qq_32998593/article/details/86177151