持续部署是每次构建成功时自动部署应用程序的行为。我目前正在与一个正在致力于持续部署的开发团队合作,作为其持续交付采用计划的一部分。该系统涉及多个内部Web服务,这似乎是一个开始工作的好地方,不仅可以实现部署的自动化,还可以在这些部署期间保持非常高的正常运行时间。自动化部署涉及开发和高科技集团,所以我想我会寻找一些有用的例子来帮助说明所需的技术和步骤。我发现了几个博客和文章谈论不同的方法,但没有工作的例子。
本文将逐步介绍整个过程,同时也包括一个完整的工作示例。
对于这个例子的源代码和rake脚本不耐烦,可以在https://github.com/grahambrooks/zero-down找到。
如果您曾使用过Rails或 Play框架,那么您将了解数据库迁移(Play中的演变)。每次迁移都会更改数据库模式,包括数据迁移。这些系统非常强大,显着提高了Web应用程序更新的可靠性和速度。
但是有一个问题!升级过程假定存在服务中断或旧系统和新系统之间存在数据差距。
服务中断是旧数据库和应用程序更新时旧系统关闭或客户端无法访问的传统方法。通常,这些更新是在系统轻载时完成的,以最大限度地减少业务影响。
为了避免这种情况,一些实现使用蓝色/绿色部署片,但这可能会导致升级后需要解决的版本之间的数据差异。蓝色/绿色更新的优点是活动用户受到的干扰最小(如果有的话)。对于24/7操作,这种方法非常有吸引力。
最小化或消除服务中断的更新应该是标准,因此这里所涉及的技术专注于维护服务。
Martin Fowler在他的网站Martin Fowler Blue Green Deployment上介绍了蓝绿色发布流程
蓝/绿发布
初始绿色状态
从绿色系统客户端开始,我们通过负载平衡器调用Web服务。Web服务由关系数据库支持。一个相当典型的设置。

接下来,我们添加新的'蓝色'系统,它是包括应用程序服务器和数据库在内的系统组件的完整堆栈。
添加新的蓝色切片
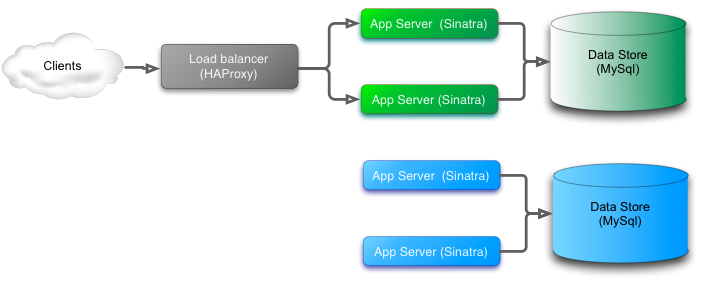
切换非常简单。在方便的时候,入境流量从绿色系统切换到新的蓝色版本。为了启动并运行蓝色系统,将采用绿色数据库的副本,然后使用新的蓝色版本的数据库迁移对其进行升级。在蓝色系统升级并准备切换时,绿色系统处理的任何交易都需要重新播放以避免数据丢失。在移动数据之前,发送到绿色系统的用户数据在新的蓝色系统中将不可用,这很容易导致在交易系统中很难解开和解决的差异。
将绿色切换为蓝色
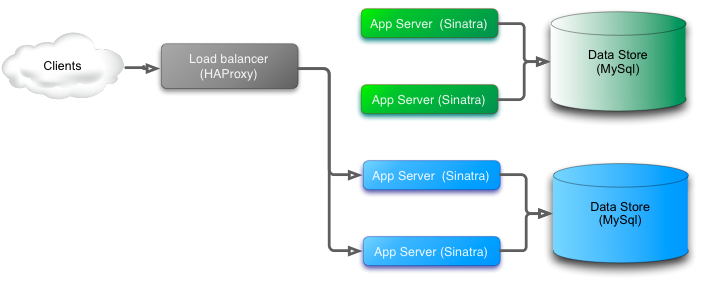
最后绿色系统被删除。
最终的蓝色状态

此选项使用新版本创建新的数据库和服务实例,然后将呼叫者从旧版本迁移到新版本。通常这是通过更新负载均衡器配置来完成的。
此选项要求将任一版本的请求成功处理到数据库中,否则在转换后,转换到原始系统将不可用。
如果可行,此选项的风险较低。在升级失败后,流量立即回退到原始系统,直到有固定版本可用。
向后和向前兼容的数据库
这种方法还有一些步骤,需要更多的代码,稍后会被丢弃,但它解决了升级期间和升级后数据完整性的关键问题。
假设我们从绿色系统开始处于相同状态,第一步是应用数据库更新。这些更新需要同时支持当前系统和新版本。很多数据库更改都可以支持这两个版本,但简单重构数据库模式是有问题的,并且需要额外的措施。
添加蓝色系统和蓝色/绿色数据库
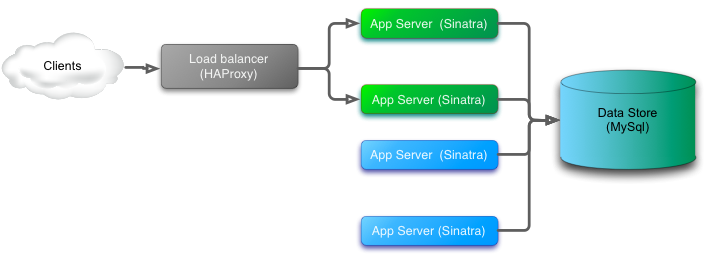
现在当我们切换时,没有数据差异。数据库更新适用于这两个系统,并且可以保持数据完整性。
切换

一旦从新的蓝色系统提供流量,可以删除数据库中用于支持旧的绿色系统的任何代码。
最终的蓝色状态
工作示例
这个例子不是一个完整的应用程序,但包含所有关键元素,用于零停机更新。
最初的'绿色'数据库模式的UML
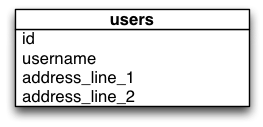
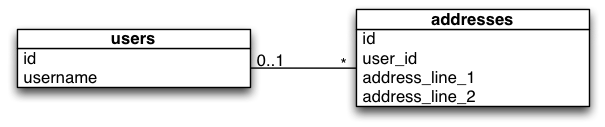
过渡型或临时型'蓝绿'数据库模式的UML
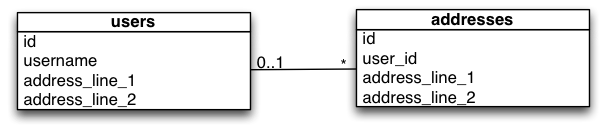
最终的'蓝色'数据库模式的UML
回到前面的更新
该方法首先更新数据库,然后更新每个应用程序服务器。为了实现这种工作方式,数据库必须与当前版本和新版本的服务兼容。
自然这种方法有更大的风险。如果数据库更新失败或不兼容,则发行被阻止。
技术
- 持久性 - MySQL
- 应用程序 - 使用活动记录的Ruby Sinatra应用程序
- 负载平衡器 - HAProxy
开发工具
- Rake用于自动执行部署任务
- 用于数据库迁移的dbdeploy
该应用程序非常简单。它提供显示用户列表的单个索引页面。版本1显示存储在用户表中的单个地址。版本2显示每个用户具有零个或多个地址。
更新基本流程
初始状态
- 服务器版本1在端口8001上运行
- HAProxy配置为接受端口8000上的入站连接,并将它们传递给端口8001上的应用程序
- 数据库包含一个表
CREATE TABLE users (
id int(11) NOT NULL AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
address_line_1 VARCHAR(100),
address_line_2 VARCHAR(100),
PRIMARY KEY (id)
);目标国家
- 服务器版本2在端口8002上运行(在现实生活中,这可能是一个不同的服务器)
- HAProxy在端口8000上接受入站连接,并在8002上将请求转发到版本2
- 数据库包含两个表(用户和地址)
升级步骤
- 创建新的表格(地址)
- 安装触发器在用户记录更新时创建,更新和删除地址记录
- 将用户表中的地址数据复制到地址表中
- 运行服务器V2
- 更新负载平衡器配置(HAProxy)以指向服务器V2
- 关机服务器V1
- 删除数据库触发器
- 从用户表中删除未使用的列
设置版本1
创建数据库
CREATE DATABASE rolling;为dbdeploy设置所需的表
CREATE TABLE changelog (
change_number BIGINT NOT NULL,
complete_dt TIMESTAMP NOT NULL,
applied_by VARCHAR(100) NOT NULL,
description VARCHAR(500) NOT NULL
);
ALTER TABLE changelog ADD CONSTRAINT Pkchangelog PRIMARY KEY (change_number)
;运行第一次迁移
CREATE TABLE users (
id int(11) NOT NULL AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
address_line_1 VARCHAR(100),
address_line_2 VARCHAR(100),
PRIMARY KEY (id)
);启动服务器
ruby server/v1/server.rb -p 8001
使用版本1配置启动HAProxy
haproxy -f cfg/v1/haproxy.cfg -D -p $(<haproxy-private.pid) -st $(<haproxy-private.pid)
此时,该服务可在http:// localhost:8000和位于http:// localhost:8001的服务器端点获得
设置安装版本2
首先,我们需要设置新的表结构以及在数据库中保持向前和向后兼容性的机制。此处显示的方法使用触发器和更新脚本来启动事情。
DROP TABLE IF EXISTS addresses;
//
CREATE TABLE addresses (
id int(11) NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
address_line_1 VARCHAR(100),
address_line_2 VARCHAR(100),
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users(id)
);
//
DROP TRIGGER IF EXISTS create_addresses_trigger;
//
CREATE TRIGGER create_addresses_trigger AFTER INSERT ON users FOR EACH ROW
INSERT INTO addresses (user_id, address_line_1, address_line_2) VALUES(NEW.id, NEW.address_line_1, NEW.address_line_2);
//
DROP TRIGGER iF EXISTS update_addresses_trigger;
//
CREATE TRIGGER update_addresses_trigger AFTER UPDATE ON users FOR EACH ROW
BEGIN
UPDATE addresses SET address_line_1 = NEW.address_line_1, address_line_2 = NEW.address_line_2 WHERE user_id = NEW.id;
INSERT INTO addresses (user_id, address_line_1, address_line_2)
SELECT u.id, u.address_line_1, u.address_line_2
FROM user u
LEFT JOIN addresses ua ON ua.user_id = u.id
WHERE ua.user_id IS NULL;
END
//
CREATE TRIGGER user_delete_addresses_trigger BEFORE DELETE ON users FOR EACH ROW
DELETE FROM addresses WHERE user_id = OLD.id;
//
INSERT INTO addresses (user_id, address_line_1, address_line_2)
SELECT u.id, u.address_line_1, u.address_line_2
FROM users u
LEFT JOIN addresses ua ON ua.user_id = u.id
WHERE ua.user_id IS NULL
;现在我们可以开始第2版
ruby server/v2/server.rb -p 8002
服务器现在已启动并正在运行,可通过http:// localhost:8002进行测试和预热
现在我们可以重新配置负载均衡器
haproxy -f cfg/v2/haproxy.cfg -p $(<haproxy-private.pid) -st $(<haproxy-private.pid)
HAProxy完成对服务器1的事务处理,但新请求转到服务器版本2.如果服务器版本1没有流量,则服务器可以关闭,并且最终删除用户表中的旧数据库列。
ALTER TABLE users
DROP COLUMN address_line_1,
DROP COLUMN address_line_2
;概要
实现零停机升级肯定是可以实现的,但一切都有成本。本文中概述的步骤仍然假定一定级别的人工干预依次运行每个脚本,并且检查之前的操作是否成功。下一步就是集成一些生产级的部署后自动化烟雾测试,以使流程完全自动化。只有这样它才能成为自动交付管道的一部分。
有用的文章